כדי שמודל AI יהיה שימושי בהקשרים ספציפיים, הוא לרוב זקוק לגישה לידע רקע. לדוגמה, צ'אטבוטים לתמיכת לקוחות דורשים ידע על העסק הספציפי עבורו הם משמשים, וסוכנים לניתוח משפטי צריכים להכיר מגוון רחב של תיקים קודמים.
מפתחים משפרים בדרך כלל את הידע של מודל AI באמצעות RAG (Retrieval-Augmented Generation). RAG היא שיטה השולפת מידע רלוונטי מבסיס ידע ומצרפת אותו לפרומפט של המשתמש, מה שמשפר משמעותית את תגובת המודל. הבעיה היא שפתרונות RAG מסורתיים מסירים הקשר בעת קידוד המידע, מה שלרוב גורם למערכת להיכשל בשליפת המידע הרלוונטי מבסיס הידע.
בפוסט זה, אנו מפרטים שיטה המשפרת באופן דרמטי את שלב השליפה ב-RAG. השיטה נקראת "שליפה בהקשר" (Contextual Retrieval) ומשתמשת בשתי תתי-טכניקות: Contextual Embeddings ו-Contextual BM25. שיטה זו יכולה להפחית את מספר כשלי השליפה ב-49% ובשילוב עם reranking, בעד 67%. נתונים אלו מייצגים שיפורים משמעותיים בדיוק השליפה, שמתורגמים ישירות לביצועים טובים יותר במשימות המשך.
תוכלו לפרוס בקלות פתרון שליפה בהקשר משלכם עם Claude באמצעות ה-cookbook שלנו.
הערה על שימוש בפרומפט ארוך יותר
לפעמים הפתרון הפשוט ביותר הוא הטוב ביותר. אם בסיס הידע שלכם קטן מ-200,000 טוקנים (כ-500 עמודי חומר), תוכלו לכלול את בסיס הידע כולו בפרומפט שאתם מעבירים למודל, ללא צורך ב-RAG או בשיטות דומות.
לפני מספר שבועות, השקנו את ה-prompt caching עבור Claude, מה שהופך גישה זו למהירה ויעילה משמעותית מבחינת עלויות. כעת מפתחים יכולים לשמור פרומפטים בשימוש תכוף במטמון בין קריאות API, מה שמפחית את זמן השהיה ביותר מפי 2 ואת העלויות בעד 90% (תוכלו ללמוד איך זה עובד ב-ה-prompt caching cookbook שלנו).
עם זאת, ככל שבסיס הידע שלכם גדל, תזדקקו לפתרון שניתן להרחבה. זה המקום שבו נכנסת ה"שליפה בהקשר".
מבוא ל-RAG: סקיילינג לבסיסי ידע גדולים יותר
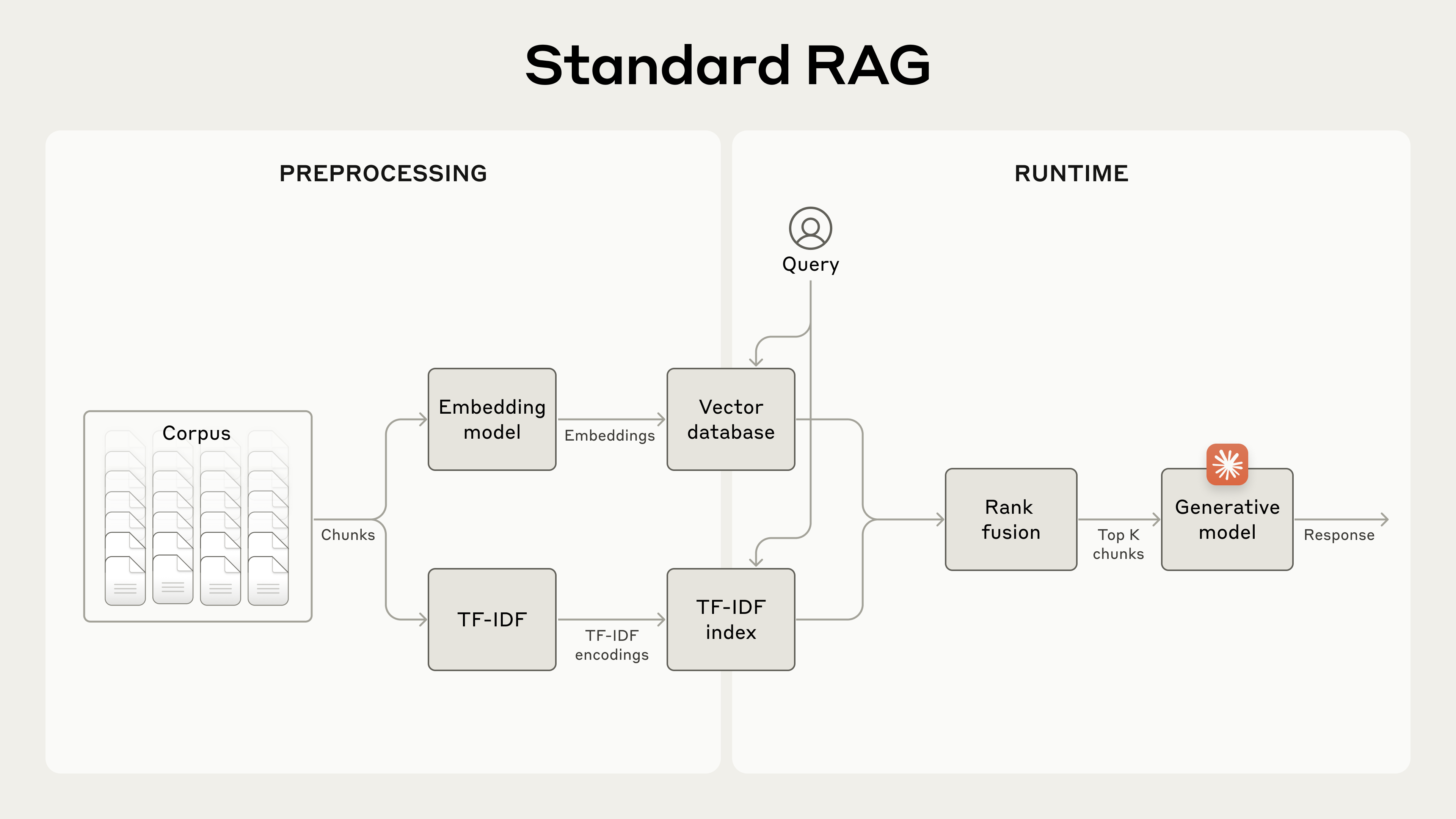
עבור בסיסי ידע גדולים יותר שאינם נכנסים בחלון ההקשר, RAG הוא הפתרון הטיפוסי. RAG פועל על ידי עיבוד מקדים של בסיס ידע באמצעות השלבים הבאים:
- לפרק את בסיס הידע (ה"קורפוס" של המסמכים) לחלקי טקסט קטנים יותר, בדרך כלל לא יותר מכמה מאות טוקנים;
- להשתמש במודל embedding כדי להמיר את החלקים הללו ל-vector embeddings המקודדים משמעות;
- לאחסן את ה-embeddings הללו במסד נתונים וקטורי המאפשר חיפוש לפי דמיון סמנטי.
בזמן ריצה, כאשר משתמש מזין שאילתה למודל, מסד הנתונים הווקטורי משמש למציאת חלקי הטקסט הרלוונטיים ביותר בהתבסס על דמיון סמנטי לשאילתה. לאחר מכן, החלקים הרלוונטיים ביותר מתווספים לפרומפט הנשלח למודל הגנרטיבי.
בעוד שמודלי embedding מצטיינים בלכידת יחסים סמנטיים, הם עלולים לפספס התאמות מדויקות קריטיות. למרבה המזל, קיימת טכניקה ותיקה יותר שיכולה לסייע במצבים אלו. BM25 (Best Matching 25) היא פונקציית דירוג המשתמשת בהתאמה לקסיקלית כדי למצוא התאמות מדויקות של מילים או ביטויים. היא יעילה במיוחד עבור שאילתות הכוללות מזהים ייחודיים או מונחים טכניים.
BM25 פועלת על בסיס הרעיון של TF-IDF (Term Frequency-Inverse Document Frequency). TF-IDF מודד את חשיבותה של מילה למסמך באוסף. BM25 מחדדת זאת על ידי התחשבות באורך המסמך ויישום פונקציית רוויה לתדירות המונח, מה שמסייע למנוע ממילים נפוצות לשלוט בתוצאות.
הנה כיצד BM25 יכולה להצליח היכן ש-semantic embeddings נכשלים: נניח שמשתמש שואל "Error code TS-999" במסד נתונים של תמיכה טכנית. מודל embedding עשוי למצוא תוכן על קודי שגיאה באופן כללי, אך עלול לפספס את ההתאמה המדויקת ל-"TS-999". BM25 מחפש מחרוזת טקסט ספציפית זו כדי לזהות את התיעוד הרלוונטי.
פתרונות RAG יכולים לשלוף בצורה מדויקת יותר את חלקי הטקסט הרלוונטיים ביותר על ידי שילוב טכניקות ה-embeddings ו-BM25 באמצעות השלבים הבאים:
- לפרק את בסיס הידע (ה"קורפוס" של המסמכים) לחלקי טקסט קטנים יותר, בדרך כלל לא יותר מכמה מאות טוקנים;
- ליצור קידודי TF-IDF ו-semantic embeddings עבור חלקי טקסט אלו;
- להשתמש ב-BM25 למציאת חלקי הטקסט המובילים בהתבסס על התאמות מדויקות;
- להשתמש ב-embeddings למציאת חלקי הטקסט המובילים בהתבסס על דמיון סמנטי;
- לשלב ולבטל כפילויות של תוצאות מ-(3) ו-(4) באמצעות טכניקות איחוד דירוגים (rank fusion);
- להוסיף את K חלקי הטקסט המובילים לפרומפט כדי ליצור את התגובה.
על ידי מינוף מודלי BM25 ו-embedding כאחד, מערכות RAG מסורתיות יכולות לספק תוצאות מקיפות ומדויקות יותר, תוך איזון בין התאמת מונחים מדויקת להבנה סמנטית רחבה יותר.
גישה זו מאפשרת לכם לבצע סקיילינג יעיל מבחינת עלות לבסיסי ידע עצומים, הרבה מעבר למה שיכול היה להיכנס לפרומפט בודד. אך למערכות RAG מסורתיות אלו יש מגבלה משמעותית: הן לעיתים קרובות הורסות הקשר.
דילמת ההקשר ב-RAG מסורתי
ב-RAG מסורתי, מסמכים מחולקים בדרך כלל לחלקי טקסט קטנים יותר לשם שליפה יעילה. בעוד שגישה זו פועלת היטב עבור יישומים רבים, היא עלולה להוביל לבעיות כאשר לחלקי טקסט בודדים חסר הקשר מספק.
לדוגמה, דמיינו שיש לכם אוסף של מידע פיננסי (נניח, דוחות SEC אמריקאיים) המוטמע בבסיס הידע שלכם, וקיבלתם את השאלה הבאה: "מה הייתה צמיחת ההכנסות של חברת ACME ברבעון השני של 2023?"
חלק טקסט רלוונטי עשוי להכיל את הטקסט: "הכנסות החברה צמחו ב-3% ביחס לרבעון הקודם." עם זאת, חלק טקסט זה לבדו אינו מפרט לאיזו חברה הוא מתייחס או את תקופת הזמן הרלוונטית, מה שמקשה על שליפת המידע הנכון או שימוש יעיל במידע.
הכירו את "שליפה בהקשר"
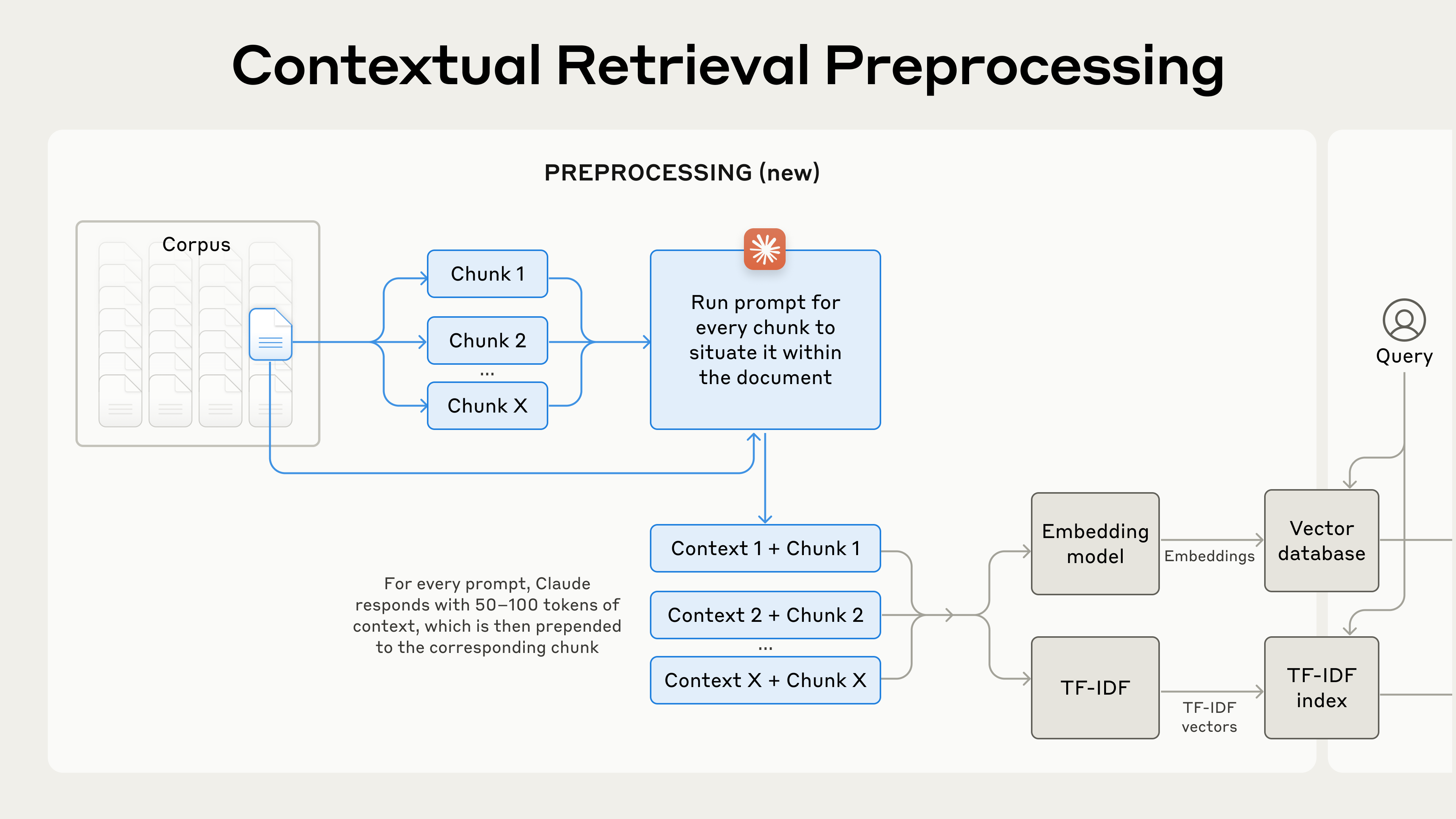
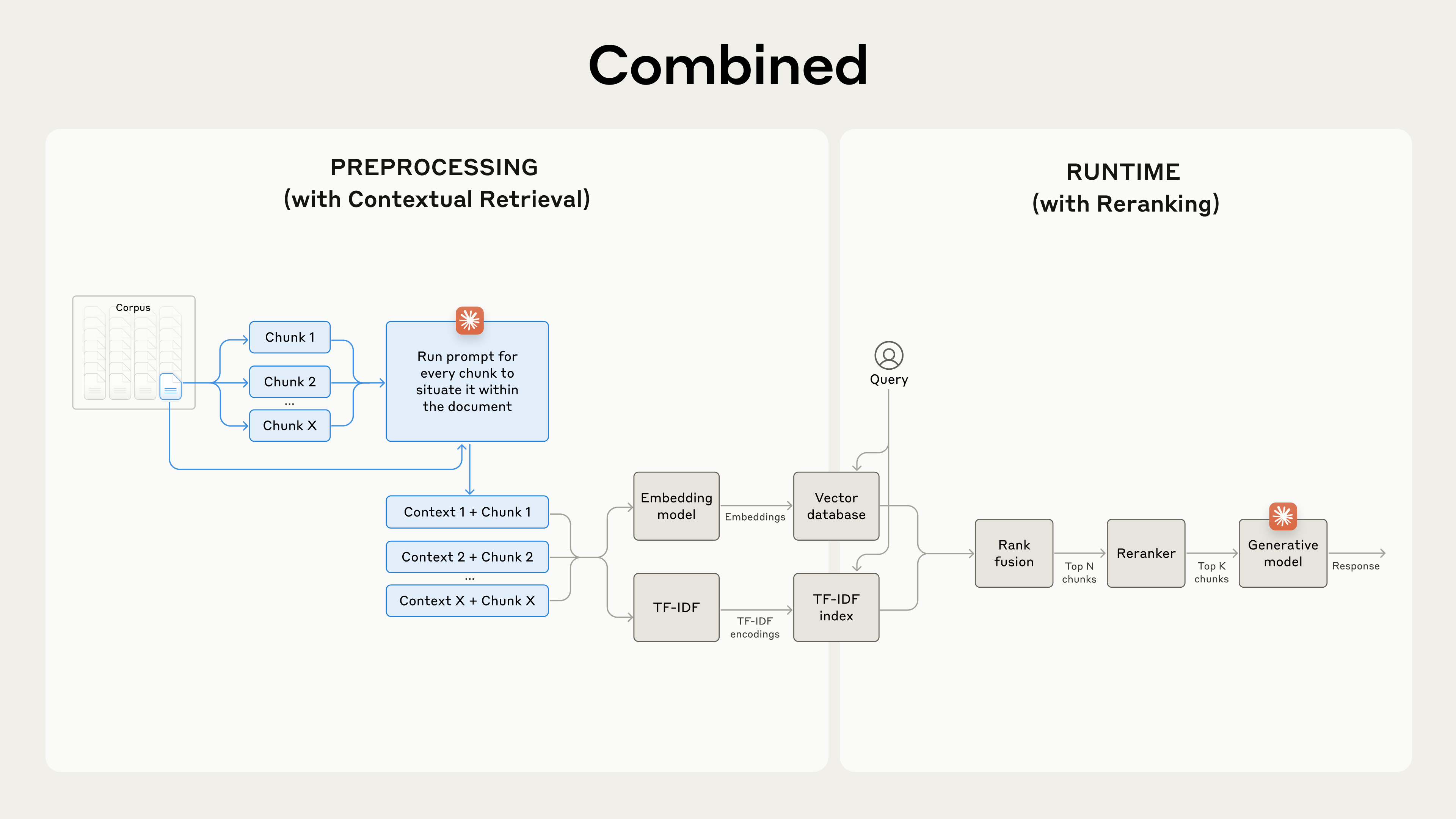
שליפה בהקשר פותרת בעיה זו על ידי הוספת הקשר הסברי ספציפי לכל חלק טקסט לפני הטמעה (Contextual Embeddings) ויצירת אינדקס BM25 (Contextual BM25).
בואו נחזור לדוגמה שלנו של אוסף דוחות SEC. הנה דוגמה לאופן שבו חלק טקסט יכול להשתנות:
original_chunk = "The company's revenue grew by 3% over the previous quarter."
contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."ראוי לציין כי גישות אחרות לשימוש בהקשר לשיפור שליפה הוצעו בעבר. הצעות אחרות כוללות: הוספת סיכומי מסמכים כלליים לחלקי טקסט (ערכנו ניסויים וראינו רווחים מוגבלים מאוד), הטמעת מסמך היפותטי, ו-אינדוקס מבוסס סיכום (הערכנו וראינו ביצועים נמוכים). שיטות אלו שונות ממה שמוצע בפוסט זה.
יישום שליפה בהקשר
כמובן, יהיה זה עבודה רבה מדי לסמן ידנית אלפי או אפילו מיליוני חלקי טקסט בבסיס ידע. כדי ליישם שליפה בהקשר, אנו פונים ל-Claude. כתבנו פרומפט המורה למודל לספק הקשר תמציתי וספציפי לכל חלק טקסט, המסביר את החלק תוך שימוש בהקשר המסמך הכולל. השתמשנו בפרומפט הבא של Claude 3 Haiku כדי לייצר הקשר עבור כל חלק טקסט:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.הטקסט ההקשרי המתקבל, בדרך כלל 50-100 טוקנים, מתווסף בתחילת חלק הטקסט לפני הטמעתו ולפני יצירת אינדקס ה-BM25.
הנה איך נראה תהליך העיבוד המקדים בפועל:
אם אתם מעוניינים להשתמש בשליפה בהקשר, תוכלו להתחיל עם ה-cookbook שלנו.
שימוש ב-Prompt Caching להפחתת עלויות שליפה בהקשר
שליפה בהקשר מתאפשרת באופן ייחודי בעלות נמוכה עם Claude, הודות לתכונת ה-prompt caching המיוחדת שהזכרנו לעיל. עם prompt caching, אינכם צריכים להעביר את מסמך הייחוס עבור כל חלק טקסט. אתם פשוט טוענים את המסמך למטמון פעם אחת ולאחר מכן מפנים לתוכן השמור במטמון. בהנחה של חלקי טקסט בני 800 טוקנים, מסמכים בני 8k טוקנים, הוראות הקשר של 50 טוקנים, ו-100 טוקנים של הקשר לכל חלק טקסט, העלות החד-פעמית ליצירת חלקי טקסט בהקשר היא 1.02 דולר למיליון טוקני מסמך.
מתודולוגיה
ערכנו ניסויים במגוון תחומי ידע (מאגרי קוד, ספרות בדיונית, מאמרים מ-ArXiv, מאמרים מדעיים), מודלי embedding, אסטרטגיות שליפה ומדדי הערכה. כללנו כמה דוגמאות לשאלות ותשובות שבהן השתמשנו עבור כל תחום בנספח II.
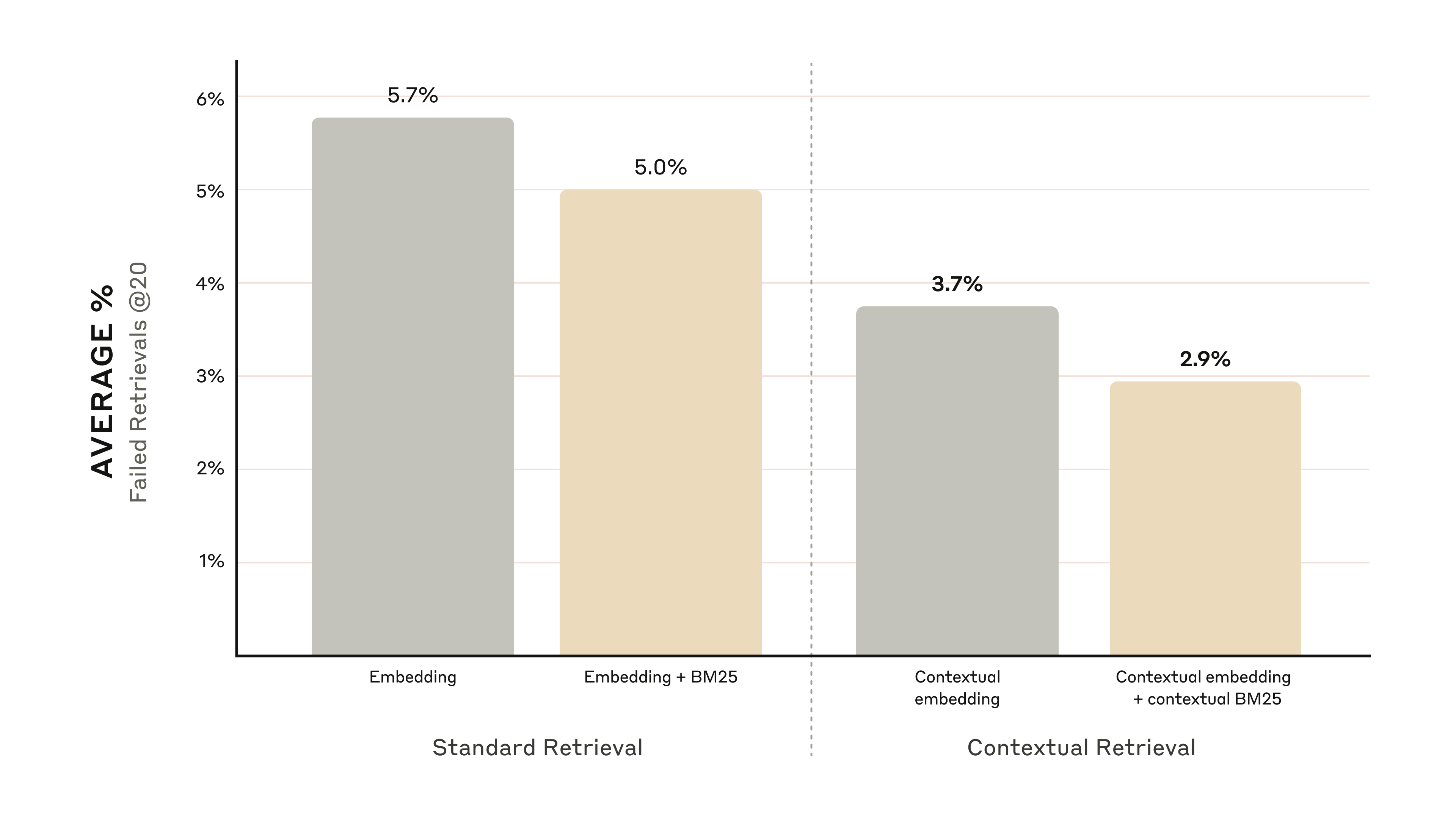
הגרפים שלהלן מציגים את הביצועים הממוצעים בכל תחומי הידע עם תצורת ה-embedding בעלת הביצועים הטובים ביותר (Gemini Text 004) ושליפת 20 חלקי הטקסט המובילים. אנו משתמשים ב-1 פחות recall@20 כמדד ההערכה שלנו, המודד את אחוז המסמכים הרלוונטיים שלא נשלפים בתוך 20 חלקי הטקסט המובילים. את התוצאות המלאות ניתן לראות בנספח – הוספת הקשר משפרת את הביצועים בכל שילוב של מודל embedding ומקור נתונים שהערכנו.
שיפורי ביצועים
הניסויים שלנו הראו כי:
- Contextual Embeddings הפחיתו את שיעור כשלי שליפת 20 חלקי הטקסט המובילים ב-35% (5.7% → 3.7%).
- שילוב של Contextual Embeddings ו-Contextual BM25 הפחית את שיעור כשלי שליפת 20 חלקי הטקסט המובילים ב-49% (5.7% → 2.9%).
שיקולי יישום
בעת יישום שליפה בהקשר, ישנם מספר שיקולים שכדאי לזכור:
- גבולות חלקי טקסט: שקלו כיצד אתם מפצלים את המסמכים שלכם לחלקי טקסט. הבחירה בגודל חלק הטקסט, בגבולותיו ובחפיפה ביניהם יכולה להשפיע על ביצועי השליפה.
- מודל Embedding: בעוד ש"שליפה בהקשר" משפרת ביצועים בכל מודלי ה-embedding שבחנו, ישנם מודלים שעשויים להפיק תועלת רבה יותר מאחרים. מצאנו כי embeddings של Gemini ושל Voyage היו יעילים במיוחד.
- פרומפטים מותאמים אישית להקשריות: בעוד שהפרומפט הגנרי שסיפקנו עובד היטב, ייתכן שתוכלו להשיג תוצאות טובות אף יותר עם פרומפטים המותאמים לתחום הספציפי או למקרה השימוש שלכם (לדוגמה, הכללת מילון מונחים של מונחי מפתח שעשויים להיות מוגדרים רק במסמכים אחרים בבסיס הידע).
- מספר חלקי טקסט: הוספת חלקי טקסט רבים יותר לחלון ההקשר מגדילה את הסיכויים לכלול את המידע הרלוונטי. עם זאת, מידע רב מדי עלול להסיח את דעתם של מודלים, ולכן יש לכך גבול. ניסינו להזין 5, 10 ו-20 חלקי טקסט, ומצאנו כי שימוש ב-20 היה בעל הביצועים הטובים ביותר מבין האפשרויות הללו (ראו נספח להשוואות), אך כדאי לערוך ניסויים במקרה השימוש הספציפי שלכם.
בצעו תמיד הערכות: יצירת תגובות עשויה להשתפר על ידי העברת חלק הטקסט הממוקם בהקשר והבחנה בין מהו ההקשר ומהו חלק הטקסט.
שיפור נוסף בביצועים עם Reranking
בשלב אחרון, אנו יכולים לשלב שליפה בהקשר עם טכניקה נוספת כדי להשיג שיפורים נוספים בביצועים. ב-RAG מסורתי, מערכת ה-AI מחפשת בבסיס הידע שלה כדי למצוא את חלקי המידע הרלוונטיים הפוטנציאליים. עם בסיסי ידע גדולים, שליפה ראשונית זו מחזירה לעיתים קרובות חלקי טקסט רבים – לפעמים מאות – בעלי רלוונטיות וחשיבות משתנות.
Reranking היא טכניקת סינון נפוצה לוודא שרק חלקי הטקסט הרלוונטיים ביותר עוברים למודל. Reranking מספק תגובות טובות יותר ומפחית עלויות וזמני השהיה מכיוון שהמודל מעבד פחות מידע. השלבים המרכזיים הם:
- בצעו שליפה ראשונית כדי לקבל את חלקי הטקסט הפוטנציאליים הרלוונטיים ביותר (השתמשנו ב-150 המובילים);
- העבירו את N חלקי הטקסט המובילים, יחד עם שאילתת המשתמש, דרך מודל ה-reranking;
- באמצעות מודל reranking, תנו לכל חלק טקסט ציון בהתבסס על רלוונטיותו וחשיבותו לפרומפט, ולאחר מכן בחרו את K חלקי הטקסט המובילים (השתמשנו ב-20 המובילים);
- העבירו את K חלקי הטקסט המובילים למודל כהקשר כדי לייצר את התוצאה הסופית.
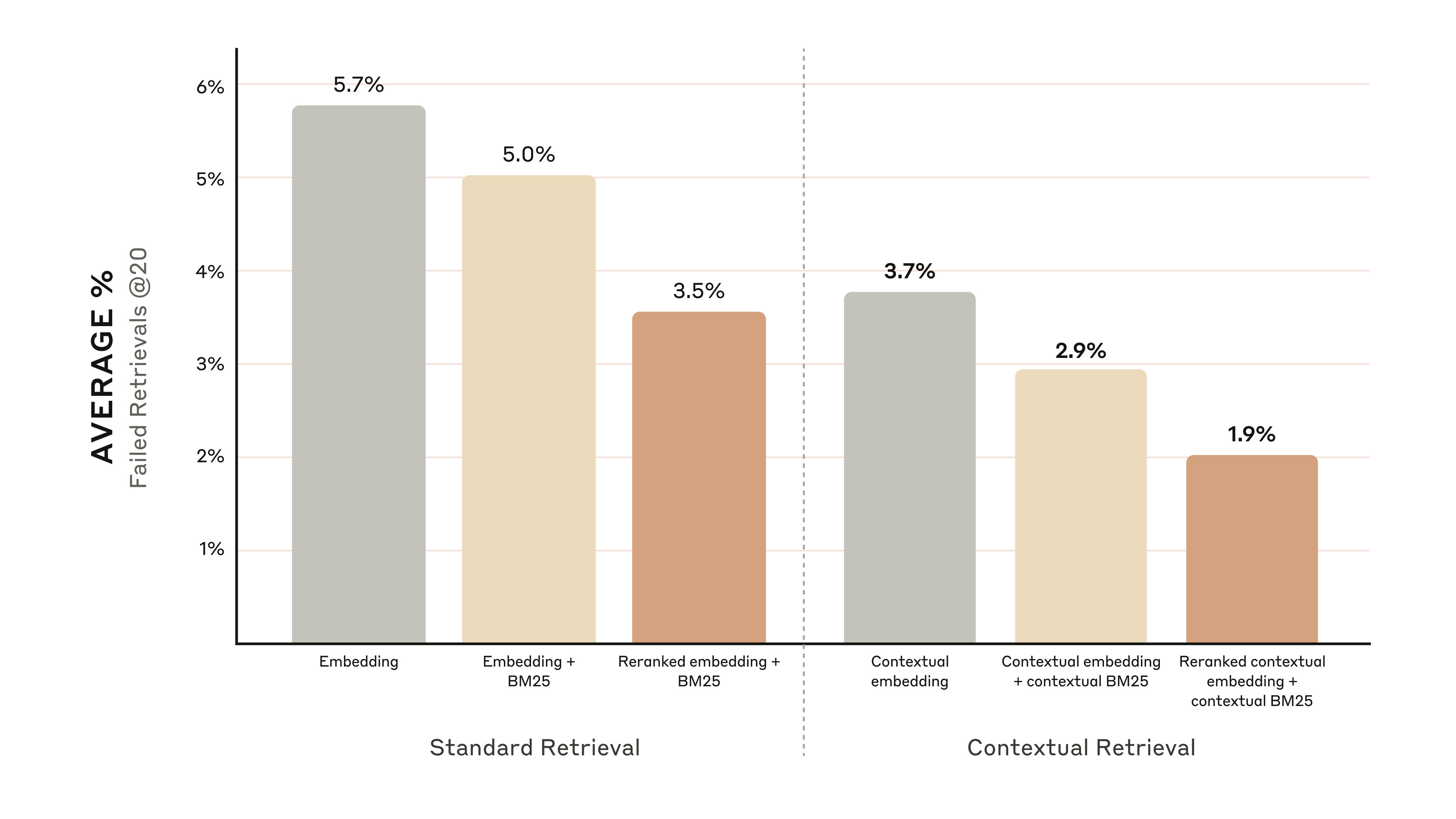
שיפורי ביצועים
קיימים מספר מודלי reranking בשוק. ביצענו את הבדיקות שלנו עם ה-reranker של Cohere. Voyage גם מציעה reranker, אם כי לא היה לנו זמן לבדוק אותו. הניסויים שלנו הראו כי, במגוון תחומים, הוספת שלב reranking משפרת עוד יותר את השליפה.
באופן ספציפי, מצאנו כי Contextual Embedding ו-Contextual BM25 עם reranking הפחיתו את שיעור כשלי שליפת 20 חלקי הטקסט המובילים ב-67% (5.7% → 1.9%).
שיקולי עלות וזמן השהיה
שיקול חשוב אחד ב-reranking הוא ההשפעה על זמן השהיה ועל העלות, במיוחד כאשר מעבירים מספר רב של חלקי טקסט ל-reranking. מכיוון ש-reranking מוסיף שלב נוסף בזמן ריצה, הוא מוסיף בהכרח כמות קטנה של זמן השהיה, גם אם ה-reranker מדרג את כל חלקי הטקסט במקביל. ישנו איזון מובנה בין reranking של יותר חלקי טקסט לביצועים טובים יותר לבין reranking של פחות חלקי טקסט לזמן השהיה ועלות נמוכים יותר. אנו ממליצים לערוך ניסויים עם הגדרות שונות במקרה השימוש הספציפי שלכם כדי למצוא את האיזון הנכון.
מסקנות
ערכנו מספר רב של בדיקות, השווינו שילובים שונים של כל הטכניקות שתוארו לעיל (מודל embedding, שימוש ב-BM25, שימוש בשליפה בהקשר, שימוש ב-reranker, והמספר הכולל של K התוצאות המובילות שנשלפו), והכל על פני מגוון סוגי נתונים שונים. הנה סיכום של מה שמצאנו:
- Embeddings + BM25 עדיפים על embeddings לבדם;
- ל-Voyage ול-Gemini יש את ה-embeddings הטובים ביותר מבין אלו שבחנו;
- העברת 20 חלקי הטקסט המובילים למודל יעילה יותר מאשר רק 10 או 5 המובילים;
- הוספת הקשר לחלקי טקסט משפרת מאוד את דיוק השליפה;
- Reranking עדיף על אי-שימוש ב-reranking;
- כל היתרונות הללו מצטברים: כדי למקסם את שיפורי הביצועים, אנו יכולים לשלב Contextual Embeddings (מ-Voyage או Gemini) עם Contextual BM25, בתוספת שלב reranking, והוספת 20 חלקי הטקסט לפרומפט.
אנו מעודדים את כל המפתחים העובדים עם בסיסי ידע להשתמש ב-cookbook שלנו כדי להתנסות בגישות אלו ולפתוח רמות חדשות של ביצועים.
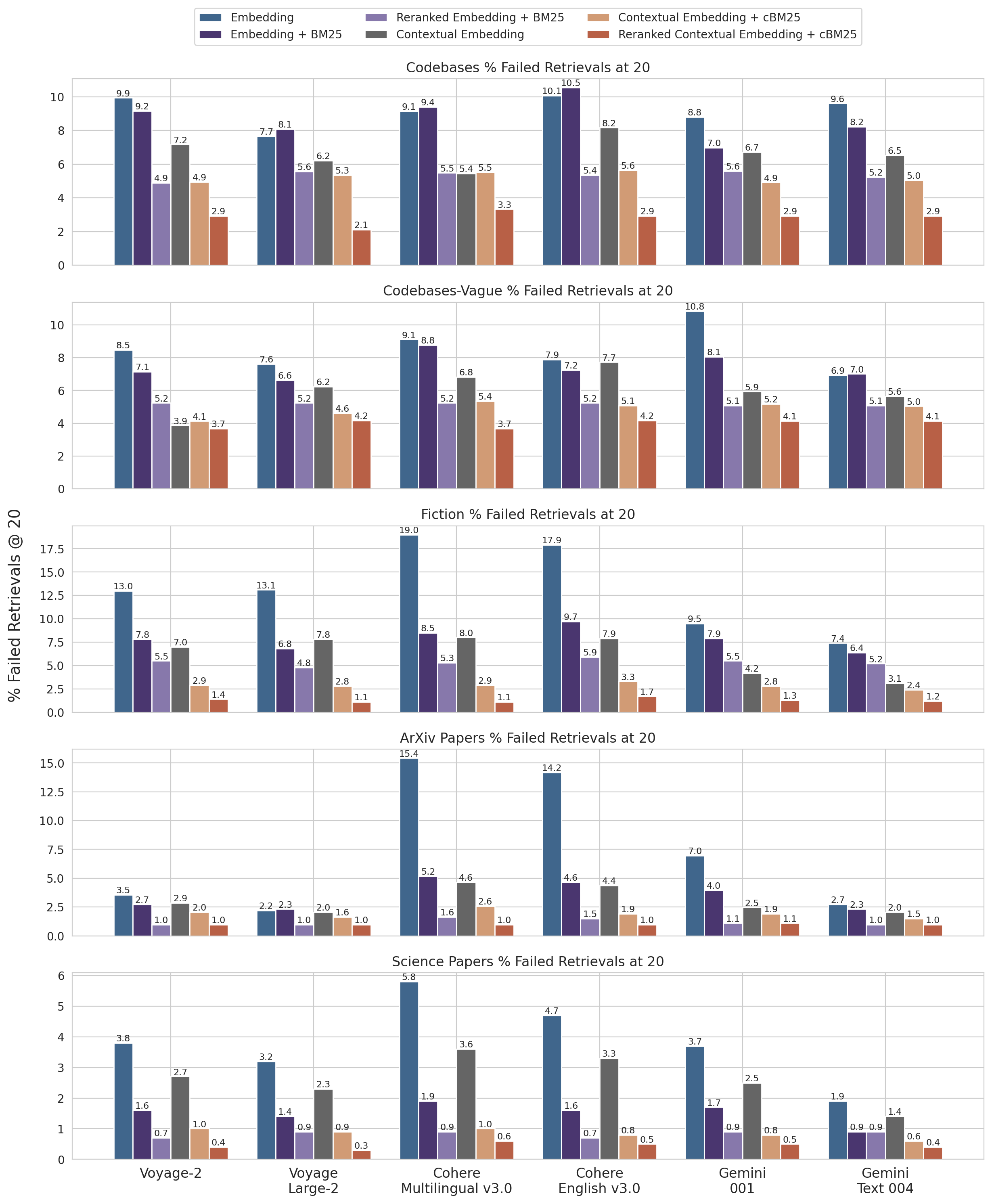
נספח I
להלן פירוט התוצאות על פני מערכי נתונים, ספקי embedding, שימוש ב-BM25 בנוסף ל-embeddings, שימוש בשליפה בהקשר, ושימוש ב-reranking עבור שליפות ב-@20.
ראו נספח II לפירוט עבור שליפות ב-@10 ו-@5, כמו גם שאלות ותשובות לדוגמה עבור כל מערך נתונים.
תודות
מחקר וכתיבה מאת דניאל פורד (Daniel Ford). תודה לאורווא סיקדר (Orowa Sikder), גאוטם מיטאל (Gautam Mittal) וקנת' ליין (Kenneth Lien) על משוב קריטי, לסמואל פלמיני (Samuel Flamini) על יישום ה-cookbooks, ללורן פולנסקי (Lauren Polansky) על תיאום הפרויקט ולאלכס אלברט (Alex Albert), סוזן פיין (Susan Payne), סטיוארט ריצ'י (Stuart Ritchie) ובראד אברמס (Brad Abrams) על עיצוב פוסט זה בבלוג.


