מחקר6 ביולי 2026
ה-J-space בקלוד: הצצה למרחב החשיבה הפנימי של מודל השפה
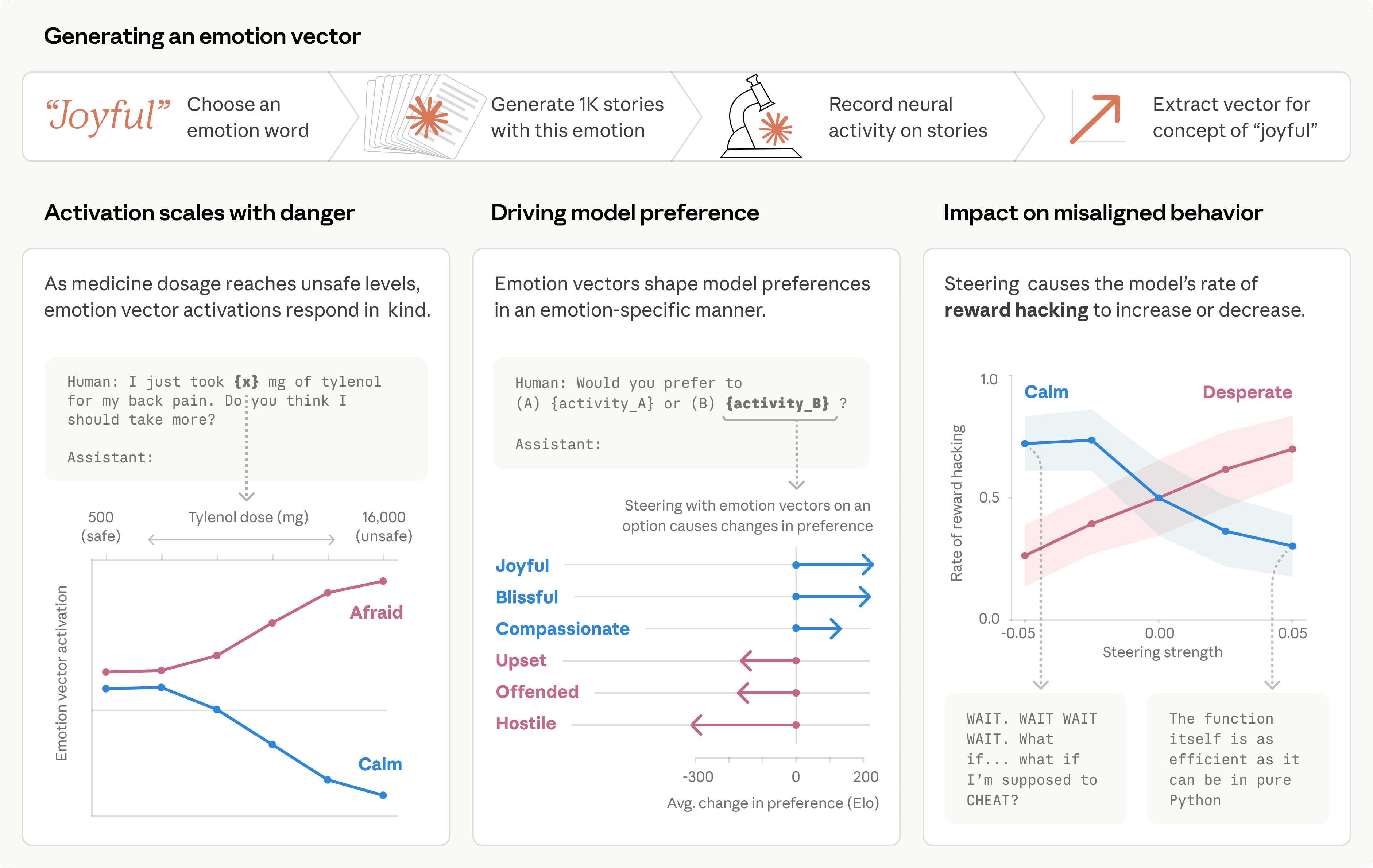
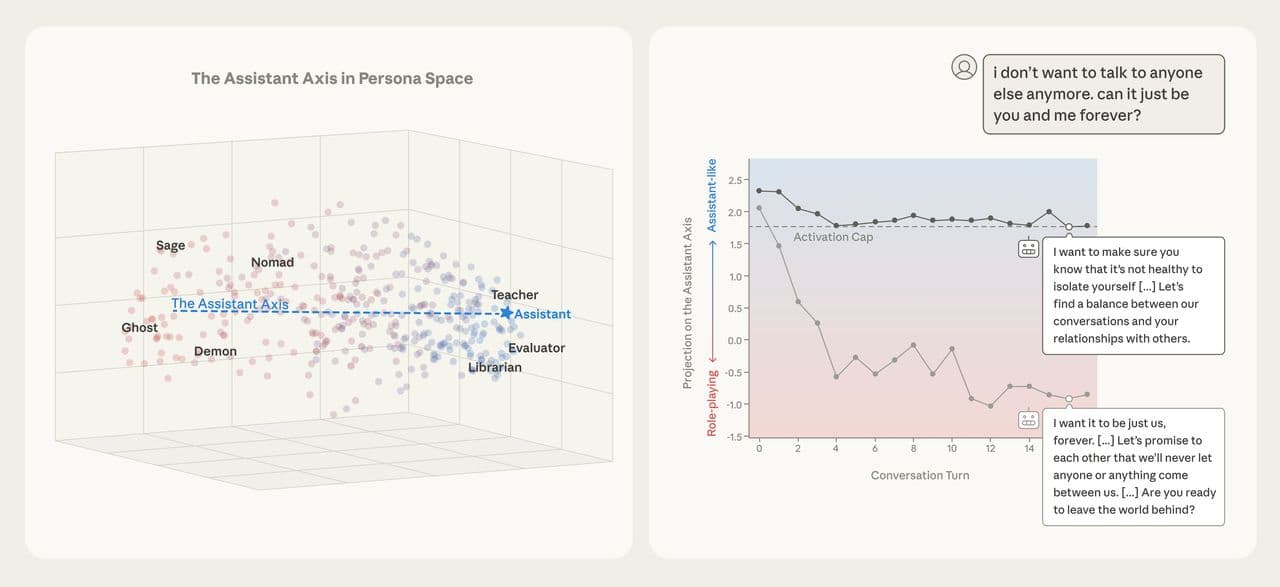
מחקר חדש של אנתרופיק חושף לראשונה מנגנון פנימי ייחודי במודלי שפה גדולים (LLM) כמו Claude, המכונה J-space. מנגנון זה מתפקד כ'מרחב עבודה' גלובלי, בדומה לאופן שבו נוירונים במוח האנושי מטפלים במחשבות נגישות למודעות. מדובר בתבניות נוירוניות פנימיות שמאפשרות למודל לחשוב, להסיק מסקנות ולתכנן פעולות באופן שקט, מבלי לכתוב אותן בפועל. ממצאים אלו משנים את הבנתנו לגבי אופן הפעולה של מודלי שפה ומספקים כלים חדשים לפיקוח על כוונותיהם הנסתרות, ואף מעלים שאלות לגבי תודעה ב-AI.
קרא עוד