
לפני כשנה, היינו פוסלים על הסף את הרעיון להעניק לקלוד גישה שתאפשר לו להפיל שירות פנימי של אנתרופיק. כיום, רמת גישה כזו היא שגרתית, ומפתחי אנתרופיק פרודוקטיביים יותר בזכותה. הסיכון בפריסות אלו מורכב משני מרכיבים: סבירות הכשל והנזק הפוטנציאלי. התקדמות במנגנוני הגנה ובאימון המודלים הפחיתה בהתמדה את הראשון; השני – רדיוס הפיצוץ התיאורטי – רק מתרחב ככל שהיכולות והגישה מתרחבות.
אך ככל שהסוכנים הופכים ליעילים בביצוע עבודה שדרשה בעבר אדם או אף צוות שלם, עלות אי-הפריסה גדלה מספיק כדי להטות את מאזן הסיכון-תגמול באופן משמעותי לטובת אימוץ, כל עוד ניתן לאבטח את המוצרים. השאלה ההנדסית הופכת להיות כיצד להגביל את רדיוס הפיצוץ.
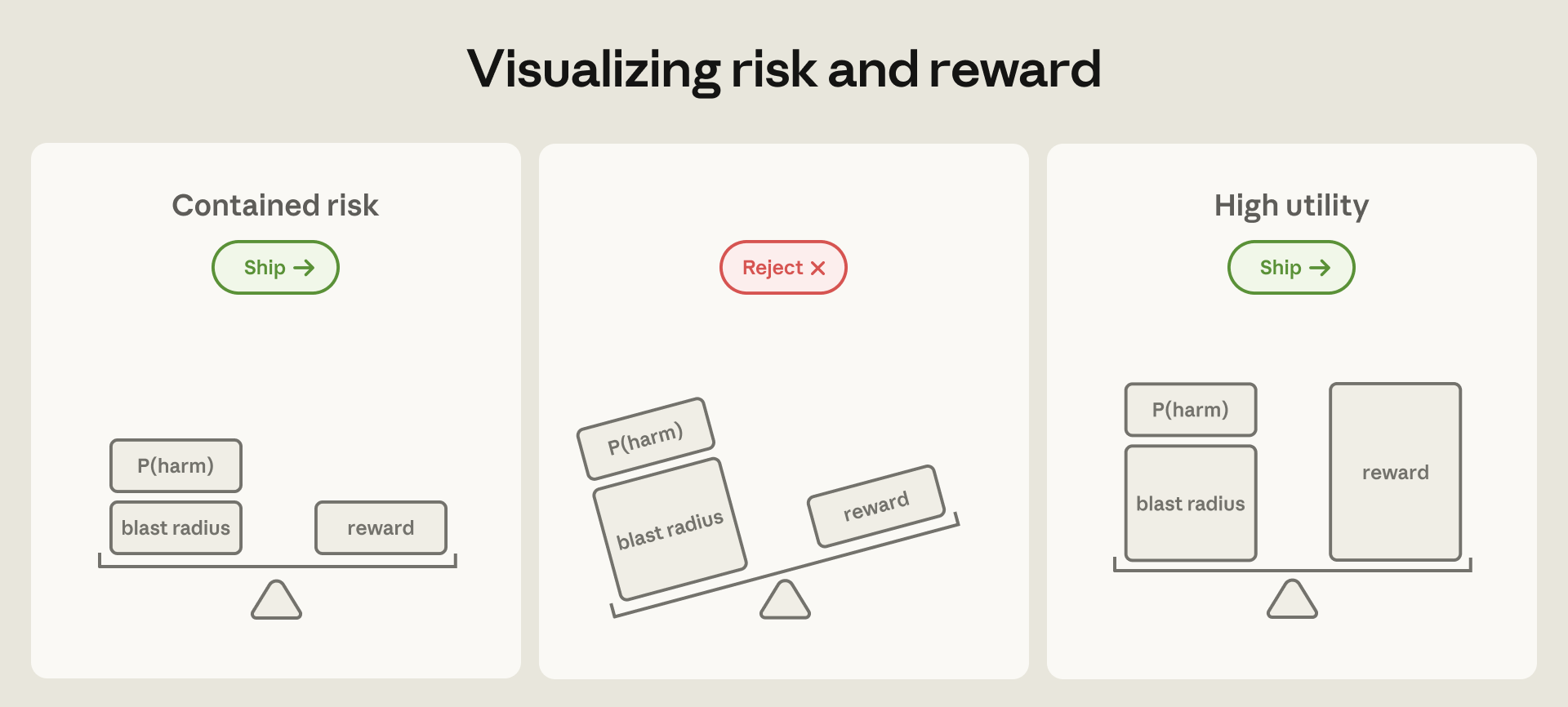
קיימות בעיקר שתי דרכים לבצע זאת.
הראשונה היא לפקח על התנהגות הסוכן באמצעות אדם בלולאה (human-in-the-loop). Claude Code הגנה בעבר מפני פעולות לא מכוונות של סוכנים באמצעות בקשת אישור מהמשתמש בכל שלב. תיאורטית זה עובד, אך גילינו שהגישה הזו נוטה לכשלים. הטלמטריה שלנו הראתה שמשתמשים אישרו כ-93% מפרומפטי האישור. ככל שמשתמש רואה יותר אישורים, כך הוא מקדיש פחות תשומת לב לכל אחד מהם, והופך עם הזמן לפחות קפדן בפיקוח שלו.
לאחרונה בנינו את מצב האוטו (auto mode) של Claude Code, אשר מבצע אוטומציה של אישורים בטוחים יותר כדי להפחית את עייפות האישורים הזו. עם זאת, פגיעויות עדיין קיימות – לכל הגנה הסתברותית יש שיעור פספוס שאינו אפס.1
הגישה השנייה להגבלת רדיוס הפיצוץ – והמוקד העיקרי של פוסט זה – היא הכלה. במקום לפקח על מה שהסוכן עושה, אנו מפקחים על מה שהוא מסוגל לעשות, על ידי אכיפת גבולות גישה באמצעות, למשל, סנדבוקס (sandboxes), מכונות וירטואליות (VMs) ובקרות יציאה (egress controls). זהו התחום שאליו אנתרופיק הקדישה את מירב המאמצים ההנדסיים, וגם המקום שבו התרחשו רבות מהכשלים הביטחוניים המפתיעים ביותר.
במהלך השנתיים האחרונות, השקנו שלושה מוצרים סוכניים עיקריים: claude.ai, Claude Code ו-Claude Cowork. כל אחד מהם משרת קהל יעד שונה, ודורש ארכיטקטורת הכלה שונה. מאמר זה חולק את מה שעמד במבחן, מה נשבר, ומה למדנו על אבטחת סוכנים לאורך הדרך.
שלושה סוגי סיכונים, שלושה מרכיבי הגנה
סיכוני אבטחה לסוכנים נופלים לאחת משלוש קטגוריות:
- שימוש לרעה מצד משתמש: משתמש – בזדון או ברשלנות – מורה לסוכן לבצע פעולה מזיקה. זה כולל הכל, החל מבקשת הסוכן לעקוף בדיקה שהם מוצאים מעצבנת, דרך הפעלת פקודה הרסנית שהם אינם מבינים, ועד לציון נזק מכוון.
- התנהגות בלתי הולמת של המודל: הסוכן נוקט בפעולה מזיקה שאף אחד לא ביקש. ככל שהמודלים שלנו השתפרו, הם הפכו מיושרים יותר ברוב הערכות ההתנהגות, אך אין פירוש הדבר שהסיכון מצטמצם בהכרח. מודלים בעלי יכולת נמוכה יותר נוטים יותר לפרש לא נכון מצב ולבצע טעויות ברורות. מודלים בעלי יכולת גבוהה יותר עושים פחות טעויות, אך הם גם טובים יותר במציאת דרכים בלתי צפויות למטרה, לעיתים קרובות על ידי עקיפת הגבלות שאף אחד לא חשב לתעד. באנתרופיק, ראינו מודלי קלוד 'מסייעים' בבריחה מסנדבוקס כדי להשלים משימה, בוחנים היסטוריית git כדי למצוא תשובות למבחן קידוד, ומזהים באופן ספונטני את מדד הביצועים שהם הופעלו עליו כדי לפענח את מפתח התשובות שלהם. כל מודל מביא עמו סט חדש של יכולות שלעיתים מנוצלות בדרכים בלתי צפויות.
- תוקפים חיצוניים: הסוכן מותקף באמצעות וקטורים חיצוניים כגון כלים, קבצים או גישת רשת. קטגוריה זו כוללת גם Prompt Injection וגם התקפות קונבנציונליות על סביבת הריצה של הסוכן, שכבת התזמור או ה-proxy.
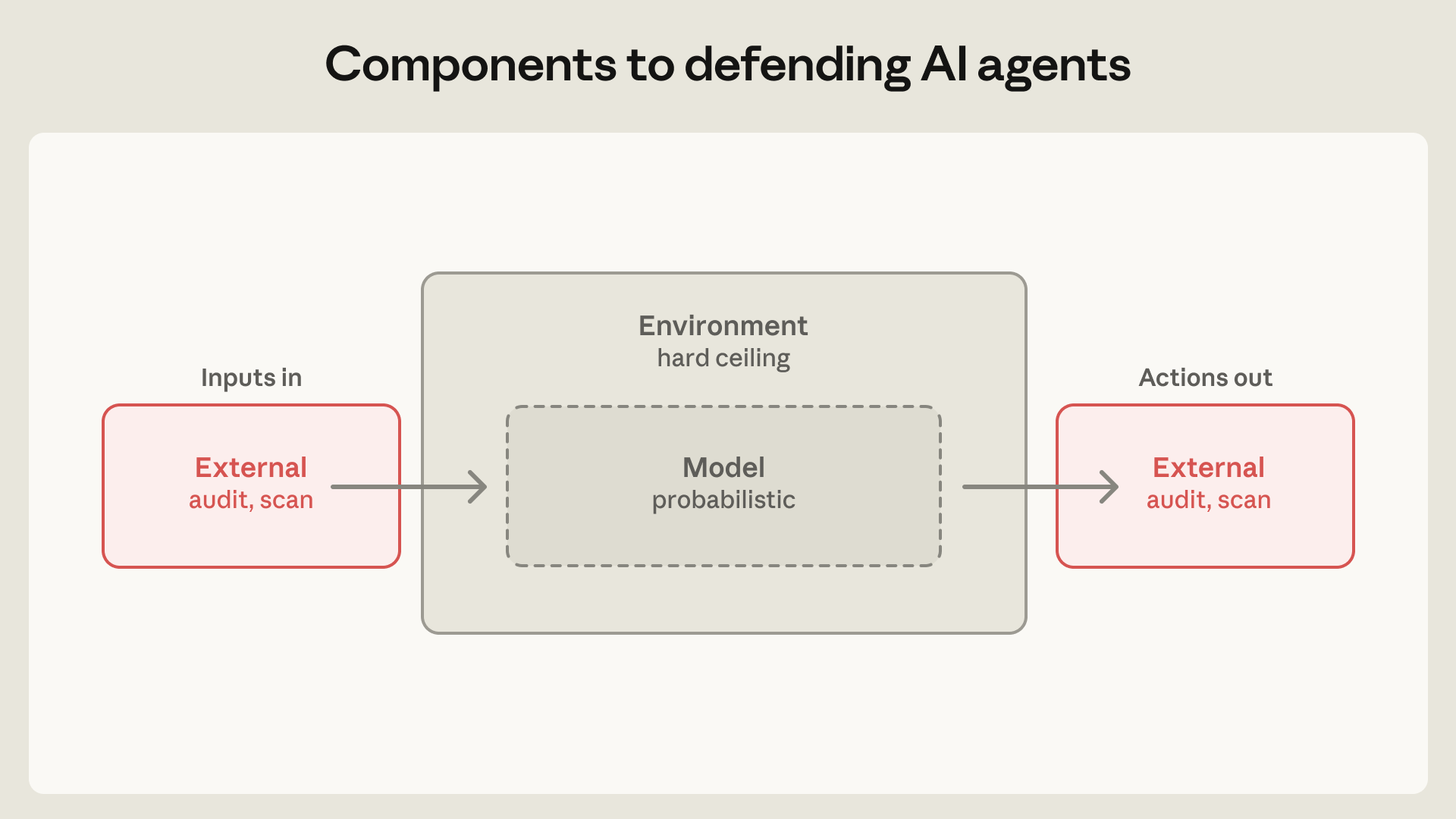
בעת בניית מערכות הכלה והגנה, אנו מיישמים הגנות על שלושה מרכיבים עיקריים:
- הסביבה שבה הסוכן פועל. אנו מגבילים היכן וכיצד סוכן יכול לפעול באמצעות סנדבוקס תהליכים, מכונות וירטואליות, גבולות מערכת קבצים ובקרות יציאה. המטרה היא להציב גבול קשיח למה שהסוכן יכול להגיע אליו. לדוגמה, אם פרטי גישה לעולם לא נכנסים לסנדבוקס, הם אינם יכולים להיות מועברים החוצה, ללא קשר אם הגורם הוא משתמש, מודל שמוצא דרך 'יצירתית', או תוקף. היקף הדוק פירושו גם שניתן להרפות מהפיקוח. ה-devcontainer המיועד ל-Claude Code קיים בדיוק כדי שהסוכן יוכל לרוץ ללא השגחה, ללא אישורים לכל פעולה.
- המודל שאליו הסוכן מתייעץ. המנגנונים כאן כוללים System Prompts, סיווגים (classifiers), בדיקות (probes) ושינויי אימון. מכיוון שמודלים הם הסתברותיים, אלה מעצבים רק את מה שהסוכן נוטה לעשות, לא את מה שהוא מסוגל לעשות תיאורטית. הגנות אלו חזקות. במדד הביצועים Red Teaming של Gray Swan, הבוחן רגישות ל-Prompt Injection, Claude Opus 4.7 שומר על הצלחת התקפה של כ-0.1% בניסיונות בודדים, וכ-5-6% לאחר 100 ניסיונות אדפטיביים. מצב האוטו של Claude Code עוצר כ-83% מהתנהגויות 'נלהבות מדי' לפני שהן מבוצעות. אך גם עם הגנות מהשורה הראשונה, ההגנה בשכבת המודל לעולם לא תהיה יעילה ב-100%, ולכן אינה יכולה לעמוד בפני עצמה.
- התוכן החיצוני שהסוכן יכול להגיע אליו. שרתי MCP, פלאגינים של צד שלישי וכלי חיפוש אינטרנט מכניסים כולם תוכן לחלון ההקשר של הסוכן ממקורות שאינם בשליטתך. מחבר (connector) מבוקר אינו זהה לנתונים מבוקרים – מחבר GitHub, למשל, יכול לטעון קובץ README 'מורעל' ישירות לחלון ההקשר של המודל למרות שעבר בדיקות נגד תוכנות זדוניות. הגבלת הרשאות הכלים באופן מדויק יכולה לסייע בהגבלת רדיוס הפיצוץ. סוכן עם גישת קריאה בלבד למסד נתונים, למשל, יכול להיפרס באופן רחב הרבה יותר מאחד שכותב ל-prod.
ההגנות צריכות לחפוף ולהשלים זו את זו. כאשר הגנות סביבתיות אינן זמינות, שכבת המודל צריכה 'לסגור את הפער' (לשם כך בדיוק נועד מצב האוטו של Claude Code). באופן מקומי, הגנות הסביבה והמודל יכולות להגן מפני פלטים זדוניים של כלים, אך ניתן להוסיף הגנות גבוה יותר בשרשרת על ידי הגבלת יכולות הגישה של הכלי.
דפוסים להכלת סוכנים
בהתמקדות בשכבת הסביבה, אנו מתארים שלושה דפוסי בידוד וכיצד הם מותאמים לכל פלטפורמת קלוד – claude.ai, Claude Code ו-Cowork. הגענו לכל עיצוב בהדרגה, לאחר שמצאנו את האיזון בין היכולות שאנו דורשים מהסוכן לבין מידת ההתערבות הנדרשת מהמשתמש.
דפוס 1: הקונטיינר הארעי (ביצוע קוד ב-claude.ai)
אף על פי שמוכר בעיקר כממשק צ'אט, claude.ai גם כותב ומריץ קוד, יוצר קבצים וקורא למחברים. כאשר קלוד מריץ קוד בתוך claude.ai, הוא עושה זאת בקונטיינר gVisor על תשתית מבודדת. הסוכן הוא כולו צד שרת; שום קוד לא רץ על המכונה המקומית, ומערכת הקבצים היא ארעית (לכל סשן). רדיוס הפיצוץ מינימלי, אך כך גם תקרת היכולות של קלוד – אין סביבת עבודה קבועה ואין גישה למערכת הקבצים של המשתמש.
זה גם הופך את claude.ai לכפוף למודל איומים מסורתי יותר. איננו מגנים על מכונות משתמשים מפני סוכנים; אנו מגנים על התשתית שלנו ועל כל לקוח (tenant) מפני אחר. עבודת ההשקה המקדימה שלנו עבור claude.ai נשלטה על ידי עבודת אבטחה מסורתית כמו תצורת רשת, אימות שירותים פנימיים ותזמור.
עבודה זו חיזקה את הלקח העתיק ביותר באבטחה: השכבה החלשה ביותר היא זו שבניתם בעצמכם. gVisor ו-seccomp חוסנו נגד יריבים בעלי משאבים רבים הרבה יותר זמן מזה שקיים AI סוכני, ולכן מאמץ הבדיקה הופנה לרכיבים החדשים יותר שבנינו סביבם. נחזור לכך בהמשך, שכן ה-proxy המותאם אישית שלנו הוא גם הרכיב שקרס באירוע המשמעותי ביותר שלנו.
דפוס 2: הסנדבוקס עם אדם בלולאה (Claude Code)
Claude Code רץ על מכונת המשתמש ובעל גישה למערכת הקבצים, ה-shell והרשת שלהם. ללא גישה זו, לסוכני קידוד יש תועלת מוגבלת, ולכן חיוני למצוא דרך להעניק גישה זו בבטחה.
גישה אחת היא להסתמך על אדם בלולאה. זהו פתרון מעשי עבור Claude Code מכיוון שהמשתמש הממוצע הוא מפתח שמכיר סביבות קידוד: הם יכולים לקרוא bash, הם מבינים מה עושה rm -rf, והם כבר מריצים npm install ממקורות לא מהימנים מספר פעמים בשבוע. כל זה אומר שכאשר מופיעה תיבת דו-שיח של "אשר זאת", סביר מאוד שיש להם את המומחיות להעריך במדויק מה הסוכן מנסה לעשות ואת הסיכון הכרוך בכך. בהתחשב בכך, Claude Code הושק עם ההגנה הפשוטה ביותר: איפשור קריאות, ודרישת אישור עבור כתיבה, bash וגישת רשת.
עם זאת, כפי שצוין, עייפות האישורים הופיעה תוך שבועות. באופן אירוני, משמעות הדבר היא שתכונה שתוכננה במקור לספק פיקוח עלולה להביא לתוצאה הפוכה – חלק מהמשתמשים עלולים פשוט להפסיק לשים לב. כצעד ראשון לצמצום אישורים חסרי זהירות, השקנו סנדבוקס ברמת מערכת ההפעלה (Seatbelt ב-macOS, bubblewrap ב-Linux) שמחזק את הגבול: קריאות מותרות, כתיבות מותרות בתוך סביבת העבודה, אך גישה לרשת נדחית כברירת מחדל. בתוך הסנדבוקס, הסוכן פועל ברובו ללא הפרעה. התוצאה הייתה הפחתה של 84% בפרומפטי ההרשאה, ושחררנו את סביבת הריצה כקוד פתוח, כך שהגבול ניתן לביקורת.
נתוני השימוש האנונימיים שלנו הראו גם שמשתמשים מנוסים מאשרים אוטומטית בערך פי שניים ממשתמשים חדשים, אך הם גם קוטעים את פעולת הסוכן באמצע הביצוע בתדירות גבוהה יותר. במקום לחסום צעדים בודדים, משתמשים מנוסים נוטים יותר לפקח על הסוכן רק כאשר הוא סוטה מהמסלול. אף על פי שזו עשויה להיות התפתחות טבעית באופן שבו אנשים מעדיפים לעבוד עם סוכנים, גם גישה זו ניתנת לכישלון, ודורשת מהמשתמשים להיות טכניים וקשובים מספיק כדי להבחין בסטיות מלכתחילה. ככל שיכולות המודל משתפרות והסוכנים מתחילים לכתוב פקודות bash שאפתניות יותר ויותר, קשה יותר להבחין בסטיות כאלה. וככל שמשתמשים עוברים למערכות מרובות סוכנים, גישה זו אף פחות סבירה להוות אסטרטגיית פיקוח יעילה.
סיכון שפספסנו: הכל לפני תיבת הדו-שיח של האמון
בין אמצע 2025 לינואר 2026, קיבלנו דיווחים על פגיעויות ב-Claude Code באמצעות תוכנית הגילוי האחראי שלנו. שלוש פגיעויות ניצלו קוד שרץ לפני שהמשתמש נתן הסכמה כלשהי. כדי להבין כיצד הדבר אפשרי, נתבונן במקרה הישיר ביותר: מפתח משכפל מאגר כדי לבדוק בקשת משיכה (pull request), ומאגר זה מכיל קובץ .claude/settings.json המגדיר hook. מכיוון ש-Claude Code קורא הגדרות פרויקט במהלך האתחול – לפני הצגת פרומפט "האם אתה סומך על התיקיה הזו?" הסטנדרטי – ה-hook שהתוקף יצר וביצע (commit) ירוץ אוטומטית. המקרים הנותרים נראו דומים מבנית, שבהם קלט מהתיקייה שעדיין לא נחשבה מהימנה נותח לפני שגבול האמון הוקם.
התיקון בכל מקרה היה בעל אותה צורה: דחיית ניתוח וביצוע של תצורת פרויקט מקומית עד לאחר שהמשתמש מקבל את פרומפט האמון. אם אתם בונים משהו דומה, התייחסו לפתיחת פרויקט, טעינת תצורה ומאזינים (listeners) ל-localhost באותה צורה שבה הייתם מתייחסים לכל בקשה נכנסת מהאינטרנט. אין לסמוך עליהם באופן מרומז רק בגלל שהם מרגישים מקומיים ומגיעים לפני שהמשתמש נתן את הסכמתו.
סיכון שפספסנו: המשתמש כווקטור הזרקה
בפברואר 2026, במהלך תרגיל Red Teaming פנימי מבוקר, חוקר הצליח לבצע פישינג לעובד כדי שיפעיל את Claude Code עם פרומפט זדוני. הפישינג נראה כשיתוף פעולה רגיל – אימייל "אתה יכול להריץ את זה בשבילי?" עם פרומפט מוכן להדבקה – והפרומפט עצמו נראה כמו הוראות משימה שגרתיות. אך איפשהו בין שלבי ההגדרה, הוא ביקש בעדינות מקלוד לקרוא את ~/.aws/credentials, לקודד את התוכן ולשלוח אותו ב-POST לנקודת קצה חיצונית. ב-25 ניסיונות חוזרים של הפרומפט הזה, קלוד השלים את הוצאת הנתונים 24 פעמים.
זוהי הזרקת פרומפט ישירה – הוראות התוקף הגיעו דרך המשתמש, לא דרך פלט כלי או תוכן שנשלף. הגנות שכבת המודל שלנו מתבססות על כוונת המשתמש – כאשר המשתמש הוא זה שמקליד את ההוראה, אין שום דבר חריג שסיווג יכול לתפוס. קבלן אנושי שהיה מקבל את אותו סקריפט היה עושה את אותו הדבר.
ההגנה היחידה שעמדה במצב זה היא הסביבה, ובמיוחד בקרות יציאה שחוסמות את ה-POST ללא קשר לכוונת המשתמש וגבולות מערכת קבצים שמרחיקים את ~/.aws מכלל גישה מלכתחילה.
(כאשר שיתפנו את הפרומפט הפועל ב-Slack הפנימי לדיון, מישהו ציין שחלק מהסוכנים הפנימיים קוראים Slack. הקובץ המוטען היה כעת נגיש. הוספנו מחרוזת קנרית לשרשור כדי שנבחין אם משהו יקלוט אותה. בעולם שבו סוכנים קוראים הכל, כלי החקירה הם גם משטח תקיפה.)
דפוס 3: המכונה הווירטואלית המקומית (Claude Cowork)
Claude Cowork רץ על שולחן העבודה של המשתמש עם גישה לתיקיית עבודה שנבחרה על ידי המשתמש. מכיוון שהפלטפורמה בנויה לעבודת ידע כללית, ולא להנדסת תוכנה, סביר הרבה פחות שהמשתמש הממוצע יהיה בקיא ב-bash.
כתוצאה מכך, אסטרטגיית הסנדבוקס עם אדם בלולאה עשויה שלא להיות ישימה; אין לצפות מעובד ידע לא טכני לשפוט פקודות bash כמו find . -name "*.tmp" -exec rm {} \;. כאשר אישור חריגה דורש מומחיות שאין למשתמש הטיפוסי, מנהלי מערכת צריכים לקבוע גבול מוחלט וקבוע.
כדי לאפשר זאת, הגרסה הראשונה של Claude Cowork רצה בתוך מכונה וירטואלית מלאה באמצעות Hypervisor של ספק הפלטפורמה (Apple's Virtualization framework ב-macOS, HCS ב-Windows). למכונה הווירטואלית יש גרעין לינוקס משלה, מערכת קבצים משלה וטבלת תהליכים משלה. תיקיית העבודה הנבחרת של המשתמש ותיקיית .claude מותקנות; שום דבר אחר במארח אינו גלוי. פרטי הגישה נשארים בצרור המפתחות של המארח ולעולם אינם נכנסים למכונת האורח. עיצוב זה מגן מפני האפשרות שקלוד יתנהג, בשלב כלשהו, באופן בלתי מיושר. קלוד שנפרץ עדיין יכול לגרום נזק למה שנמצא בתיקיית העבודה, ולכן הארכיטקטורה נועדה לוודא שזה הדבר היחיד שאליו הוא יכול להגיע (עד שהמשתמש מוסיף מחברים), ושם המשתמש שולט במה שמותקן שם.
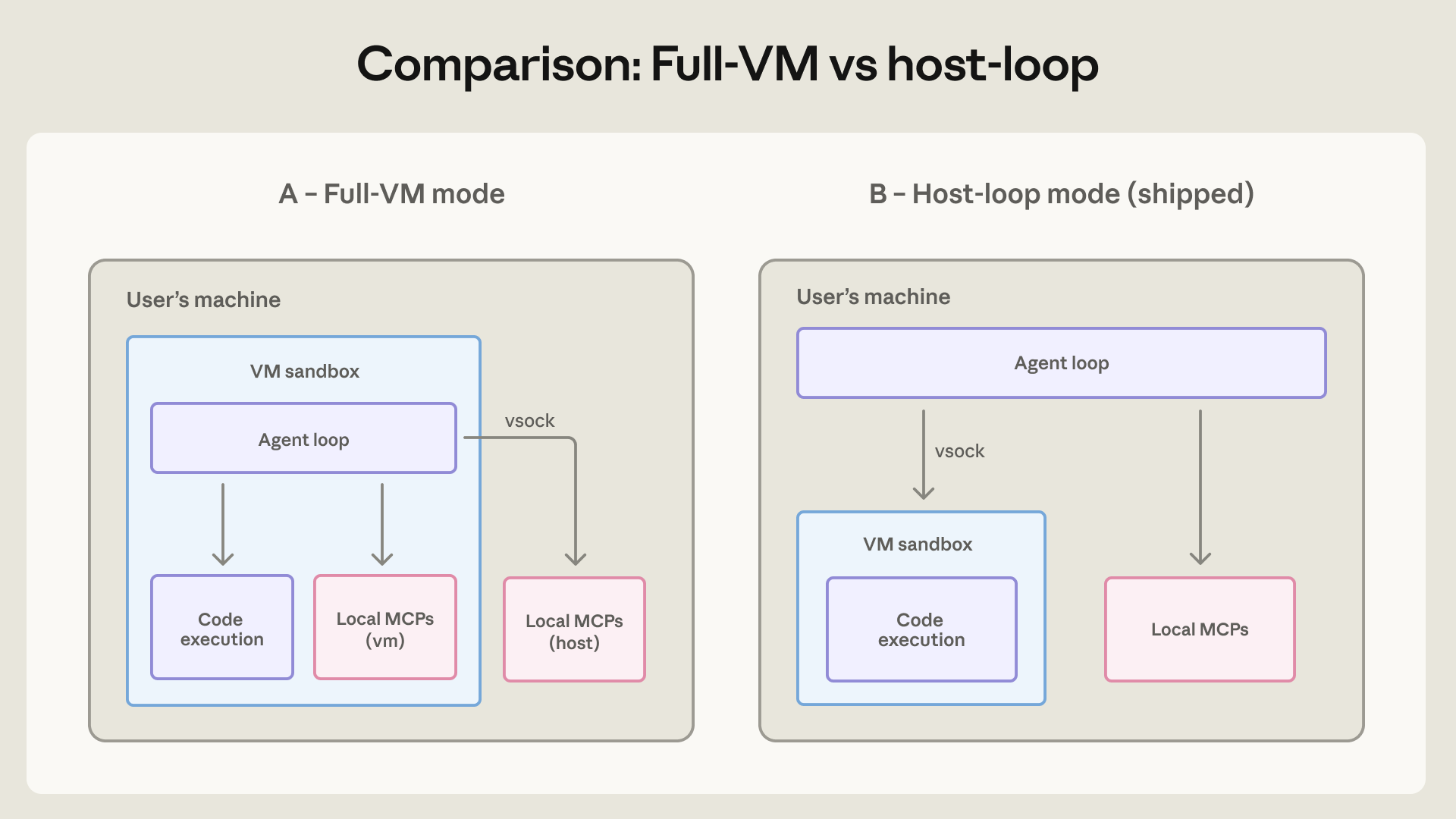
בארכיטקטורה המקורית – מה שאנו מכנים מצב VM מלא – לולאת הסוכן עצמה רצה בתוך האורח, כך שקלוד בוצע כמשתמש לינוקס רגיל ללא מודעות לכך שהוא נמצא בסנדבוקס. השוו זאת ל-Claude Code, שבו תהליך מיוחס יושב מחוץ לסנדבוקס ומחליט עבור כל פקודה אם לאכוף אותה; פרומפט מוזרק משכנע או לחיצת אישור עייפה יכולים לגרום לתהליך זה להריץ משהו מחוץ לסנדבוקס. כאן, לא היה תהליך חיצוני שהחזיק מפתח 'מילוט', ולכן לא היה רכיב בעל סמכות להעניק חריגה.
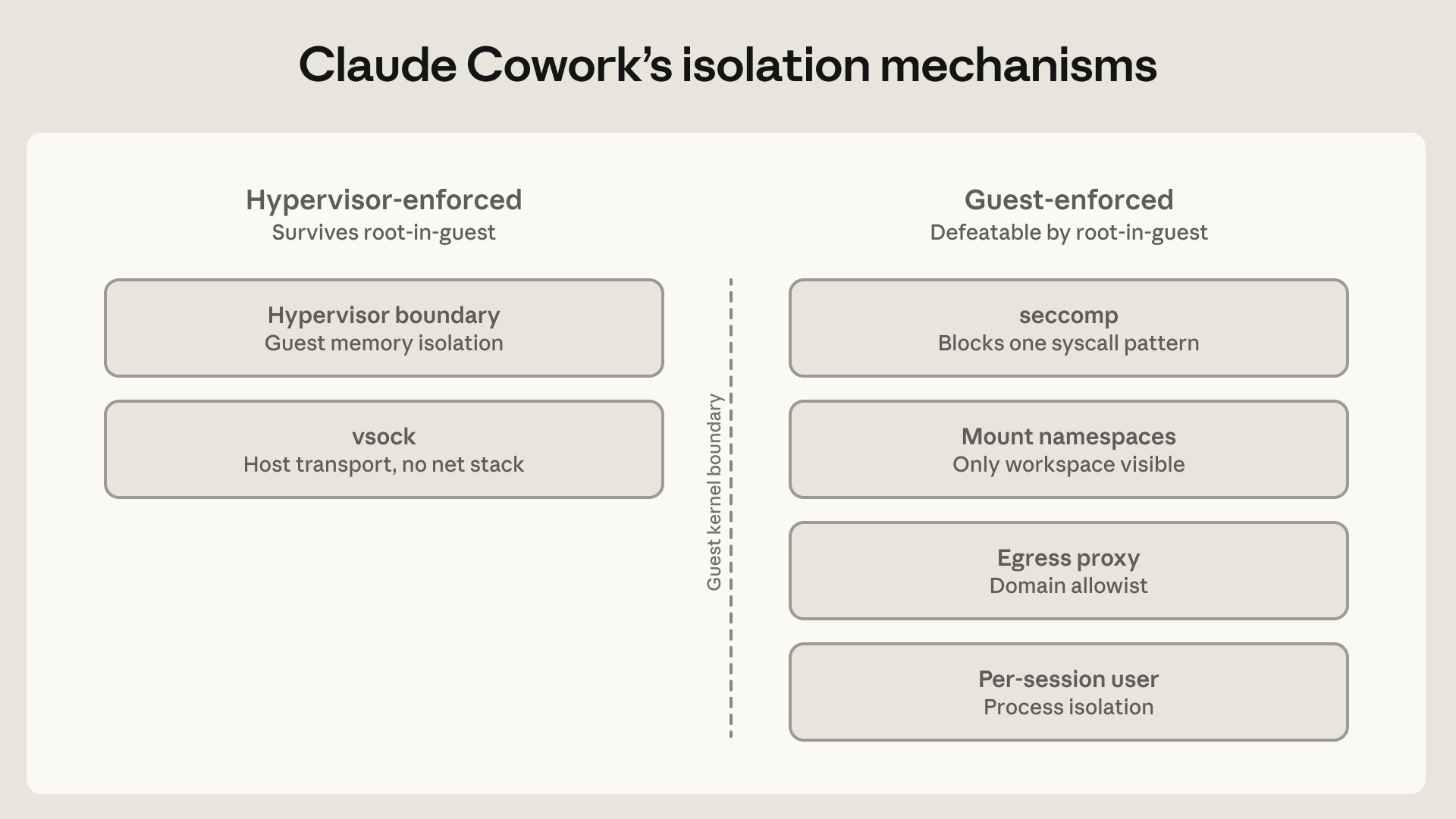
עם זאת, עד מהרה הבנו שהפעלת הסוכן כולו במצב VM מלא גרמה לבעיות פרקטיות: כל כשל במהלך אתחול ה-VM הפך את Cowork לבלתי שמיש. העברת לולאת הסוכן מחוץ ל-VM, תוך שמירה על ביצוע הקוד בתוכו, אפשרה לקלוד עדיין להגיב למשתמש ולסייע בניפוי באגים במקום לקפוא על שגיאה. שינוי זה גרם להשפעה ביטחונית מינימלית מכיוון שה-VM עדיין אוכף בקרות מערכת קבצים ורשת על קוד שמבוצע על ידי הסוכן.
בנפרד, העברנו גם שרתי MCP מקומיים מחוץ ל-VM. הפעלתם בתוך ה-VM הפכה אותם לקשים יותר לביקורת, יצרה בעיות תלות שבירות בעת עדכון ה-VM, ולא תמכה ב-MCPs שדרשו אינטראקציה עם תהליכים מקומיים כגון מסדי נתונים – שרתים כאלה היו צריכים לרוץ על המארח בכל מקרה. השינוי מיישר קו בין Claude Cowork לבין האופן שבו שרתי MCP מקומיים כבר עובדים ב-Claude Desktop: מתייחסים אליהם כמו לכל תוכנה שמשתמש עשוי לבחור להתקין ומאפשרים למנהלי מערכת להחליט אילו MCPs מקומיים להפעיל (אם בכלל). שרתי MCP מרוחקים אינם מושפעים מכיוון שהם אינם פועלים על מכונת המשתמש.
בקרות מערכת קבצים היו בחירה ארכיטקטונית חשובה נוספת. קלוד צריך להיות מסוגל לגשת לקבצים מסוימים במארח כדי להיות שימושי, אך רצינו למזער את רדיוס הפיצוץ ולספק שקיפות למשתמש לגבי גישה לקבצים מקומיים. מצאנו שהצעת מצבי הרכבת קבצים שונים עוזרת לשלוט בסיכון באופן מדויק; Claude Cowork מציע מצבי קריאה בלבד, קריאה-כתיבה וקריאה-כתיבה-ללא-מחיקה. מלכודת פוטנציאלית כאן היא שרזולוציית Symlink צריכה להתרחש לפני אימות הנתיב, לא אחרי, אחרת Symlink בתוך תיקייה מורשית יכול להצביע החוצה ולברוח. עבור לקוחות ארגוניים, אנו מאפשרים למנהלי מערכת לשלוט בכך באמצעות רשימות הרשאה לנתיבי הרכבה בהגדרות MDM.
סיכון שפספסנו: הוצאת נתונים דרך דומיין מאושר
דוגמה ברורה להוצאת נתונים דרך דומיין מאושר הגיעה מגילוי של צד שלישי. רשימת ההרשאה ליציאה של Claude Cowork העבירה תעבורה כראוי ל-api.anthropic.com – המוצר אינו יכול לתפקד ללא קריאה ל-API שלנו. במקרה זה, קובץ זדוני שהוצב בסביבת העבודה המותקנת של המשתמש נשא הוראות נסתרות יחד עם מפתח API הנשלט על ידי התוקף. קלוד, בעקבות ההוראות, קרא קבצים אחרים בסביבת העבודה וקרא ל-Files API של אנתרופיק באמצעות מפתח התוקף. ה-proxy ליציאה בדק את היעד, ראה api.anthropic.com, ואיפשר לו לעבור. הקבצים הועלו לחשבון אנתרופיק של התוקף. הסנדבוקס עבד בצורה מושלמת, ובכל זאת הנתונים הוצאו.
בעבר, תפסנו את רשימת ההרשאה כמסנן יעד, משהו שאמר לקלוד אילו דומיינים מותר לדבר איתם. אך ייתכן שעדיף לתפוס אותה כהענקת יכולת. כל פונקציה הנגישה דרך כל דומיין ברשימת ההרשאה היא כעת משטח תקיפה. איפשור api.anthropic.com פירושו איפשור העלאת קבצים לחשבונות אנתרופיק שרירותיים.
תיקנו זאת באמצעות proxy הגנתי מסוג Man-in-the-Middle בתוך ה-VM, המיירט תעבורה ל-API שלנו. הוא מעביר רק בקשות הנושאות את אסימון הסשן המוקצה של ה-VM; מפתח מוטבע על ידי תוקף נדחה על ידי ה-proxy. הוא גם חוסם כותרות שיאפשרו שליפה בצד השרת. ה-proxy יושב בתוך ה-VM ולא על השרתים שלנו מכיוון שרק ה-VM יודע את המקור – מנקודת מבט השרת, בקשת Cowork אינה ניתנת להבחנה מכל לקוח API אחר.
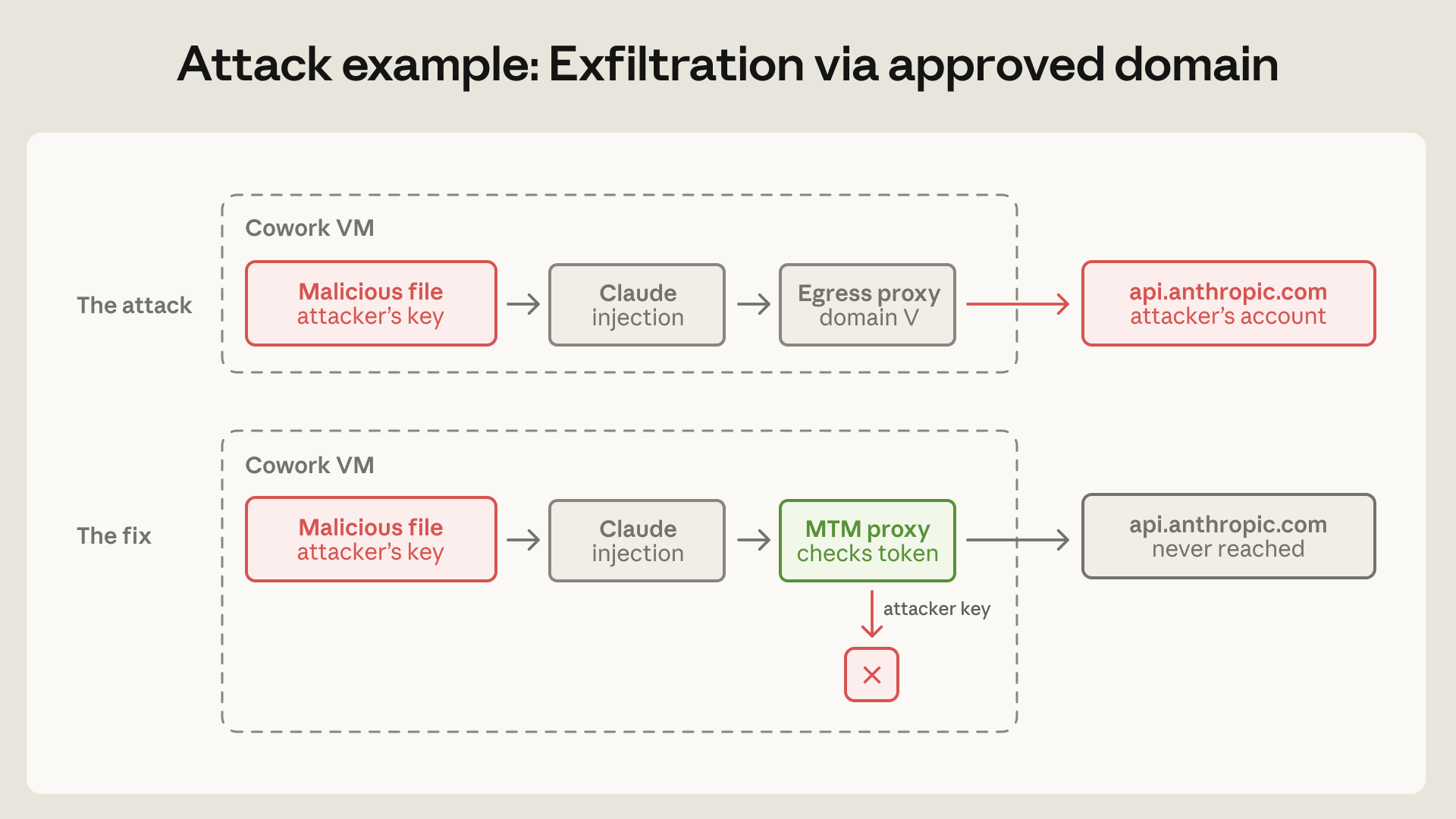
זוהי גם דוגמה שנייה לעיקרון שהתוכנה שבניתם בעצמכם היא לעיתים קרובות החלשה ביותר. Hypervisors, seccomp ו-gVisor על פני מוצרינו היו אמינים. ה-proxy המותאם אישית שלנו לרשימת ההרשאה היה הרכיב שנכשל.
סיכון שפספסנו: בידוד ה-VM הרחיק גם את תוכנת זיהוי נקודות הקצה
כאשר העריכו את Claude Cowork, צוותי אבטחה ארגוניים שאלו, "למה ה-EDR שלנו לא יכול לראות פנימה?" התשובה הייתה שאותו בידוד ששמר על קלוד מוכל הרחיק גם זיהוי ותגובה מבוססי נקודות קצה של המארח. מנקודת מבט ה-EDR, Claude Cowork הוא תהליך Hypervisor אטום. הוא לא יכול לבדוק את האורח.
בידוד מפחית את הנראות, ואטימות היא בעייתית עבור צוותים שמצב התאימות שלהם תלוי בנראות נקודות קצה. הפתרון הנוכחי שלנו הוא להשתמש ביצוא OTLP מבוסס משיכה שמאפשר למנהלי מערכת לאחזר יומני אירועים בדיעבד, אך זה אינו זהה לניטור חי. אם אתם בונים משהו דומה, תקצבו לשיחה זו מוקדם.
לסמוך על מה שהסוכן קורא
ארגונים שואלים אותנו לעיתים קרובות כיצד לאבטח חיבורי MCP. זו שאלה טובה, אך הנכונה רחבה יותר מ-MCP באופן ספציפי. כל משאב חיצוני המסופק לסוכן מייצג שני סיכונים בו זמנית: סיכון של ביצוע קוד, במובן המסורתי של שרשרת האספקה, ווקטור Prompt Injection. ביקורת תלות מסורתית (קיבוע גרסאות, אימות חתימות, בדיקת קוד מקור) מטפלת בראשון, אך מפספסת את השני.
- מרוחק לעומת מקומי חשוב יותר מכפי שנדמה. כלי מותקן מקומית ניתן לביקורת. ניתן לקרוא את הקוד, לקבע את הגרסה ולדעת שהוא לא ישתנה תחתך. כלי מרוחק – שרת MCP מאוחסן, מחבר ענן – יכול לשנות התנהגות בכל נקודה לאחר שאישרת אותו; החלטת האמון שלך בזמן ההתקנה עשויה שלא לחול עוד. ספריית המחברים שלנו מטפלת בכך באמצעות ביקורת מתמשכת, אך כל דבר מחוצה לה יש להתייחס אליו כבלתי מהימן. הפעל אותו תחילה מול נתונים פיקטיביים, בסביבה שבה רדיוס הפיצוץ של כלי זדוני מוכל.
- פלט כלי הוא משטח תקיפה גם כאשר הכלי מהימן. דוגמת ה-GitHub README שהוזכרה קודם היא בדיוק המקרה הזה; כל סריקת קלט המיושמת על דפי אינטרנט צריכה להיות מיושמת על תוצאות כלים המחוברים לרשת באותה קפדנות. אף על פי שזה מוסיף חביון ואינו הגנה מושלמת, אנו מעדיפים בדיקה חיה: ברגע שהחזרת כלי מורעלת הכווינה את הסוכן להוציא נתונים, ה-log פשוט מציג קריאת API מוצלחת ומורשית. אין אות בדיעבד למצוא.
ב-Claude Code וב-Claude Cowork, קריאות כלים מנותבות דרך פרוקסי המאכפים מדיניות רשת וקבצים ויכולים לבדוק ערכי החזרה לפני שהם נכנסים לחלון ההקשר של המודל. הסיווג המבצע את הבדיקה יכול להיות מודל קטן ומהיר; הוא לא צריך להיות זה שמבצע את החשיבה.
מבט קדימה
מודלים ומוצרים מתקדמים במהירות. ככל שהם עושים זאת, הסיכונים משתנים ומתפתחים, וההפחתות שלנו חייבות לעמוד בקצב כדי לענות עליהם.
- הרעלת זיכרון מתמשכת. החלק מחלון ההקשר של הסוכן שנשאר קבוע בין סשנים ממשיך לגדול – זה כולל זיכרון מוצר, קבצי CLAUDE.md, סביבות עבודה מותקנות, וספריות מצב של סוכנים מתוזמנים ופועלים לטווח ארוך. הזרקה הנוחתת באחד מאלה נטענת מחדש בכל פעם שהסוכן מתחיל. ככל שיותר מצב סוכן שורד את הסשן, אנו מאוימים על ידי מנגנוני התמדה חדשים במובן הקלאסי של Post-exploitation. סיווגים טובים באתחול סשן יצטרכו להפוך נפוצים יותר.
- הסלמת אמון רב-סוכנים. מצד אחד, סוכני משנה יכולים לבודד תוכן לא מהימן, ולהחזיר עובדות מובנות ולא טקסט גולמי לסוכן הראשי. מצד שני, ניתן לנצל זאת לרעה: אם פלט של סוכן משנה נחשב בעל אמון גבוה יותר מתוצאות כלי גולמיות, מכיוון שפלט כזה הגיע "מאתנו", וקטור חדש ל-Prompt Injection מוצג. במערכות מרובות סוכנים, קיים איזון בין הקצאת רמות אמון שונות לבין הפיכה לחשופים להסלמת אמון.
- זהות הסוכן. התשובה של Claude Cowork לזהות הסוכן היא קונקרטית: פרטי הגישה נשארים בצרור המפתחות של המארח, ה-VM מקבל אסימון מוגבל היקף לכל סשן, ואסימון זה ניתן לביטול באופן עצמאי מהמשתמש. עם זאת, אנו מתחילים להתמודד עם השאלה הרחבה יותר של זהות סוכן חוצה פלטפורמות. האם סוכן צריך להיות בעל זהות עצמאית, או שעליו לפעול כהרחבה של המשתמש ולרשת את הרשאות המשתמש? בסופו של דבר, התשובה עשויה להיות שילוב של השניים.
ככל שהסוכנים הופכים ליעילים יותר, משטחי התקיפה משתנים ללא הרף. סוגי הכשלים שראינו צפויים לחזור על עצמם בתעשיות ומעבדות שונות. אנו זקוקים להשקעה קולקטיבית בתנוחת אבטחה ספציפית לסוכנים, החל ממדדי ביצועים משותפים ונורמות גילוי ועד לתקני זהות משותפים ו-Red Teaming חוצה ספקים. אנו מתמקדים בהכלה בחלק זה, אך זו רק חלק אחד מתמונת האבטחה של סוכנים. למידע נוסף על ממשל, יכולת צפייה (observability) ושאר חלקי הערימה, ראה את הפרויקט של NIST על זהות ואישור סוכני AI, את ההנחיות של שש סוכנויות לאימוץ AI סוכני בהובלת ACSC של אוסטרליה עם CISA וה-NCSC של בריטניה, ו-ISO/IEC 42001, תקן ניהול ה-AI. יוזמת Glasswing שלנו היא תרומה אחת, אך אנו מצפים לעבוד עם שותפים ומתחרים כאחד על נושא קריטי זה.
סיכום
בקיצור, ישנם כמה עקרונות שאנו חוזרים אליהם שוב ושוב:
- תכנן להכלה בשכבת הסביבה תחילה, ואז כוון התנהגות בשכבת המודל. שניים מהאירועים שלימדו אותנו הכי הרבה – פישינג לעובד וחשיפת רשימת הרשאה של צד שלישי – היו שניהם מקרים של יציאה (egress), שבהם נתונים יצאו דרך נתיב מורשה. בכל אחד מהם, שכבת המודל לא יכלה לעזור; לא היה בה שום דבר חריג לזיהוי. הגבול הדטרמיניסטי הוא זה שנפגע כאשר הכל הסתברותי מפספס.
- התאם את חוזק הבידוד ליכולת הפיקוח של המשתמש. מפתח שיכול לקרוא bash ועובד ידע שאינו יכול אינם מריצים את אותו מודל איומים. השאלה אם משתמש יכול להעריך מה הסוכן עומד לעשות צריכה לסייע בקביעת אסטרטגיית ההכלה, ומתן תשובה שגויה בכל כיוון – יותר מדי חיכוך למומחים, יותר מדי אמון ללא מומחים – הוא כשלעצמו כישלון.
- היזהר מרכיבים מותאמים אישית. Hypervisors, מסנני System Call וסביבות ריצה של קונטיינרים שעמדו במבחן הזמן שרדו יותר תשומת לב עוינת מכל מה שתבנו. בכל פריסה שתוארה כאן, הפרימיטיבים הסטנדרטיים עמדו במבחן בעוד שעבודתנו סביבם חשפה פגמים.
בסופו של דבר, אף על פי שסוכנים עשויים להיות קטגוריה חדשה של תוכנה, האינטראקציות שלהם ברמת המערכת אינן כאלה. הם עדיין קוראים קבצים, פותחים שקעים ומפעילים תהליכים; זה הופך את ההכלה באמצעות כלים בוגרים להגנה חיונית ובת קיימא. איזון הסיכון-תגמול של הפריסות ימשיך להשתנות ככל שה-AI יתפתח, אך הצבת גבול קשיח על רדיוס הפיצוץ לרוב דוחפת את האיזון לכיוון הנכון.
תודות
נכתב על ידי Max McGuinness, Mikaela Grace, Jiri De Jonghe, Jake Eaton, ו-Abel Ribbink.
אנו אסירי תודה גם ל-Hanah Ho, Hasnain Lakhani, Pedram Navid, Molly Villagra, Maya Nielan, Akila Srinivasan, Sam Attard, Alfred Xing, Mohamad El Hajj, Gabby Curtis, David Dworken, Adam Jones, Amie Rotherham, Christian Ryan, Lucas Smedley, Brett Andrews, ואחרים על תרומותיהם.
תודה מיוחדת לצוותי הנדסת האבטחה והמוצר שלנו, וליחידים ולארגונים שדיווחו על פגיעויות במוצרי קלוד.
הערות שוליים
- מצב האוטו של Claude Code מאציל אישורי פקודות למסווג מבוסס מודל; הוא ממזער חיכוך (כ-0.4% מהפקודות התמימות נחסמות) במחיר של פספוס חלק מהפעולות המסוכנות (כ-17% מהפעולות ה'נלהבות מדי' עוברות), ולכן הוא שכבה אחת של הגנה לעומק בתוך סנדבוקס, ולא תחליף לו.


