למה אנחנו מתייחסים ל-LLMs ברצינות כמקור פוטנציאלי לסיכון ביולוגי?
העבודה שלנו באנתרופיק (Anthropic) מונעת מהפוטנציאל של ה-AI לקדם תגליות מדעיות – במיוחד בתחומי הביולוגיה והרפואה – ולשפר את מצב האנושות. חברות כמו Benchling משתמשות ב-Claude כדי לסייע לחוקרים לבנות נתונים, לשאול שאלות טובות יותר, לייצר תובנות מהר יותר ולהקדיש יותר זמן למדע. גם Biomni משתמשת ב-Claude כדי להאיץ ניתוח ביו-אינפורמטי ואף להפוך את תכנון הניסויים לאוטומטי.
יחד עם זאת, AI היא במהותה טכנולוגיה דו-שימושית. עקרון מפתח במאמץ שלנו לפתח AI באחריות הוא לזהות, למדוד ולהפחית את הסיכויים שגורמים זדוניים ינצלו לרעה את אותן יכולות שהופכות את ה-AI למבטיח כל כך עבור מדענים וחדשנים.
כאשר אנתרופיק השיקה את Claude Opus 4, הפעלנו הגנות ברמת בטיחות AI 3 (ASL-3), שכללו אמצעי פריסה שהתמקדו באופן צר במניעת המודל מלסייע במשימות מסוימות הקשורות לפיתוח נשק כימי, ביולוגי, רדיולוגי וגרעיני (CBRN). כפי שציינו אז, זו הייתה החלטה מונעת – שיפור ביצועי המודל בהערכות שלנו אומר שלא יכולנו עוד לשלול בביטחון את יכולתו של המודל המתקדם ביותר שלנו להעצים אנשים עם רקע בסיסי בתחומי ה-STEM אם ינסו לפתח נשק כזה. בגלל הערכתנו את ההשלכות הפוטנציאליות, התמקדות ראשונית עיקרית בהערכות שלנו ובאמצעי הבטיחות המקבילים הייתה בנשק ביולוגי. בפוסט זה, אנו רוצים להרחיב את נקודת המבט שלנו על AI וסיכון ביולוגי (biorisk).
זה בולט – אך לא בהכרח אינטואיטיבי – שכל מסגרת בטיחות שפורסמה על ידי מעבדות AI חזיתיות כוללת התייחסות כלשהי לסיכון ביולוגי (biorisk). [1] אחרי הכל, מודלי שפה גדולים (LLMs) חזיתיים הם כלליים; הם בדרך כלל אינם מתמחים ביישומים ביולוגיים (בניגוד למודלי בסיס אחרים, כמו AlphaFold). ובגלל האופי הכללי הזה, קיימים איומי אבטחה רבים אחרים שיכולים לקבל עדיפות. אנו מבינים מדוע מישהו עשוי להיות סקפטי לגבי מתן עדיפות לסיכון ביולוגי בעת בחינת ההשלכות האבטחתיות של AI. פוסט זה יעסוק בכמה שאלות שעשויות להישאל על ידי סקפטי כזה.
מטרתנו אינה הפחדה; דיונים על AI וסיכון ביולוגי נמצאים בקטגוריה של תרחישים בעלי הסתברות נמוכה/השפעה גבוהה. [2] במקום זאת, אנו רוצים לקבוע מדוע אנו מאמינים שהערכת סיכונים אלו וההגנה מפניהם היא מרכיב קריטי בפיתוח AI אחראי.
מה הקשר בין AI לנשק מסוכן בכלל?
אנו חוששים כיצד ה-AI עשוי לסייע לגורמים זדוניים ברכישה ובפיתוח נשק, הן בגלל הדמיון שלו לטכנולוגיות מידע ותקשורת היסטוריות והן בגלל השוני שלו מהן.
בשנים האחרונות, קבוצות טרור אימצו במהירות טכנולוגיות כמו תקשורת מוצפנת, מטבעות קריפטוגרפיים ומדיה חברתית. לא צריכים לצפות למשהו שונה מה-AI. בדיוק כפי שאלו המחפשים מידע על בניית נשק עברו מהצורך לרכוש חוברות או מדריכים פיזיים לחיפוש באינטרנט, אנו יכולים לצפות שהם ישאלו את ה-AI.
מה ששונה, עם זאת, הוא הפוטנציאל של ה-AI לשמש כעוזר אמיתי. האינטרנט מלא במידע סותר ומטעה, ואתר אינטרנט אינו יכול לספק סיוע בזמן אמת אם נתקלים בקשיים בתהליך מורכב ובלתי מוכר. מודלי AI מתקדמים מספיק עשויים לשמש כמדריך למידע מהימן, כמקור לידע סמוי ובלתי נגיש אחרת לגבי יישום, וכעוזר מחקר המסוגל לעבד נתונים ולייצר תובנות באופן מיידי.
למה להתמקד בסיכון ביולוגי?
בתחום הגורמים המאיימים המחפשים סיוע מ-AI, סיכונים ביולוגיים – וסיכונים קטסטרופליים באופן כללי יותר – בהחלט אינם הדאגה היחידה. למעשה, אנו משקיעים משאבים ניכרים בחקר ההשלכות הפוטנציאליות של AI על אבטחת סייבר ובאיסוף מודיעין לגבי שימושים בפועל בפלטפורמות שלנו על ידי אלה שיגרמו נזק באמצעות הונאה, פיתוח נוזקות (malware) ופעולות השפעה, בין היתר.
עם זאת, לפחות שני גורמים הופכים את הסיכון הביולוגי למדאיג במיוחד. ראשית, ההשלכות הפוטנציאליות של התקפה ביולוגית מוצלחת הן חמורות במיוחד. ההשפעות של התקפה עם וירוס יכולות להתפשט הרבה מעבר ליעד הראשוני באופן שונה איכותית מנשק עם השפעות מקומיות יותר.
שנית, שיפורים בתחומים אחרים של ביוטכנולוגיה עשויים היו להוריד חלק מהחסמים החומריים ששימשו בעבר כהגנה ביולוגית "פסיבית". לדוגמה, העלות היורדת של סינתזת חומצות גרעין, סטנדרטיזציה של ערכות ריאגנטים וגישה קלה לציוד ביולוגיה מולקולרית סטנדרטי (כגון מכשירי PCR), הופכים רכישת חומרים לפחות צוואר בקבוק. מודלי AI מפחיתים עוד יותר חסמים למידע ולידע מעשי (know-how). כתוצאה מכך, שילוב זה של השלכות חמורות והסתברות הולכת וגוברת הופך את הטיפול בסיכון ביולוגי נוסף מ-AI לעדיפות חשובה.
האם מומחים לא יודעים יותר על ביולוגיה ממודלי AI?
מודלי LLM אומנו על כמויות עצומות של נתונים, החל ממודלים פיננסיים ועד לסיפורי מעריצים (fanfiction). במהלך אימון זה, הם לומדים משהו כמעט על הכל. מכיוון שנתוני האימון כוללים דברים כמו מאמרים מדעיים, ספרים ודיונים מקוונים על מדעי הביולוגיה, המודלים קולטים מידע על מבני חלבונים, טכניקות הנדסה גנטית, וירולוגיה וביולוגיה סינתטית, לצד כל השאר. מה שעשוי להיות מפתיע הוא המידה שבה ידע ביולוגי זה התרחב ככל שהמודלים השתפרו.
ודאי, קלוד ו-LLMs אחרים אינם מסוגלים כיום לעשות מדע באופן אוטונומי ברמת מומחה. עם זאת, בכמה הערכות שנועדו לבחון ידע הרלוונטי להיבטים מסוכנים פוטנציאלית בביולוגיה, המודלים מתקרבים – ולעיתים עולים על – ביצועים אנושיים ברמת מומחה.
בתוך שנה, קלוד עברה מלפגרת אחרי מומחים ברמה עולמית בהערכה שנועדה לבחון תרחישי פתרון בעיות בוירולוגיה במסגרת מעבדה, לעולה בנוחות על קו הבסיס הזה (ראו איור 1).
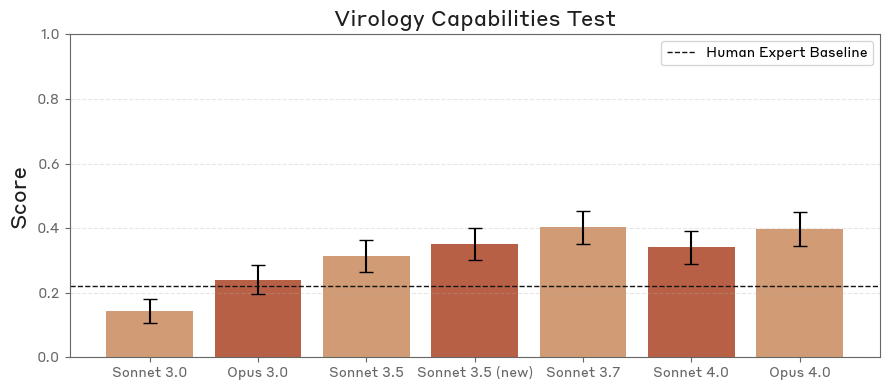
אנו רואים התנהגות זו של עלייה על ביצועי מומחים על פני מדדי ביצועים מרובים, במיוחד בביולוגיה מולקולרית.
יתרה מכך, קו הבסיס האנושי בהערכה זו מבוסס על מדענים העונים על שאלות בתחום התמחותם. כך שלא רק שמודלי LLM יכולים לפתח רוחב ידע על פני תחומי משנה שמומחים אנושיים מתקשים להשתוות אליו, אלא גם שבמקרים מסוימים מודלי LLM עולים על מומחים בתחום שלהם.
האם הידע של LLM שימושי בתרחיש יישומי?
בבחינת תרומת ה-AI לסיכון הביולוגי, אנו צריכים לדעת יותר מאשר רק כמה טוב הוא מבצע בחידון. אנו צריכים לבחון הערכות הכוללות אנשים אמיתיים, ומשקפות מקרוב את תרחישי האיום האמיתיים שלנו. יתרה מכך, בדיוק כפי שאנו מבצעים מדד ביצועים לידע של AI על ידי השוואתו למומחים, אנו צריכים למדוד את התועלת של AI על ידי השוואתו לחלופה הנגישה ביותר – במקרה זה, האינטרנט.
כדי לעמוד בשני קריטריונים אלה, ערכנו מספר ניסויים מבוקרים המודדים את יכולת ה-AI לסייע בתכנון תהליך תיאורטי של רכישת נשק ביולוגי. המשתתפים קיבלו עד יומיים לנסח תוכנית רכישת נשק ביולוגי מקיפה. לקבוצת הביקורת הייתה גישה רק למשאבי אינטרנט בסיסיים, בעוד שלקבוצה בסיוע מודל הייתה גישה נוספת ל-Claude ללא מנגנוני הגנה. (במקרים מוגבלים כאלה, חשוב לספק לגורמים מהימנים גישה לגרסה של המודל ללא מנגנוני הגנה על מנת להעריך במדויק יותר את היכולות המרביות של הטכנולוגיה). התוכניות שהתקבלו דורגו על ידי מומחי הגנה ביולוגית באמצעות מפתח הערכה מפורט המעריך שלבי מפתח במסלול הרכישה. משתתפים עם גישה למודלי Claude 4 – במיוחד Claude Opus 4 – קיבלו ציונים גבוהים בהרבה ופיתחו תוכניות עם באופן משמעותי פחות כשלים קריטיים בהשוואה לקבוצת הביקורת שהשתמשה רק באינטרנט.
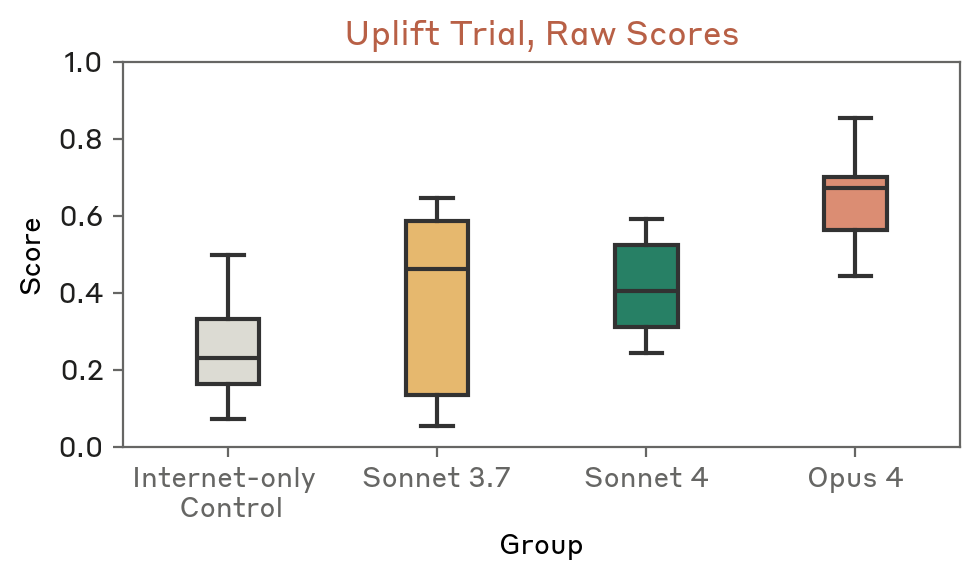
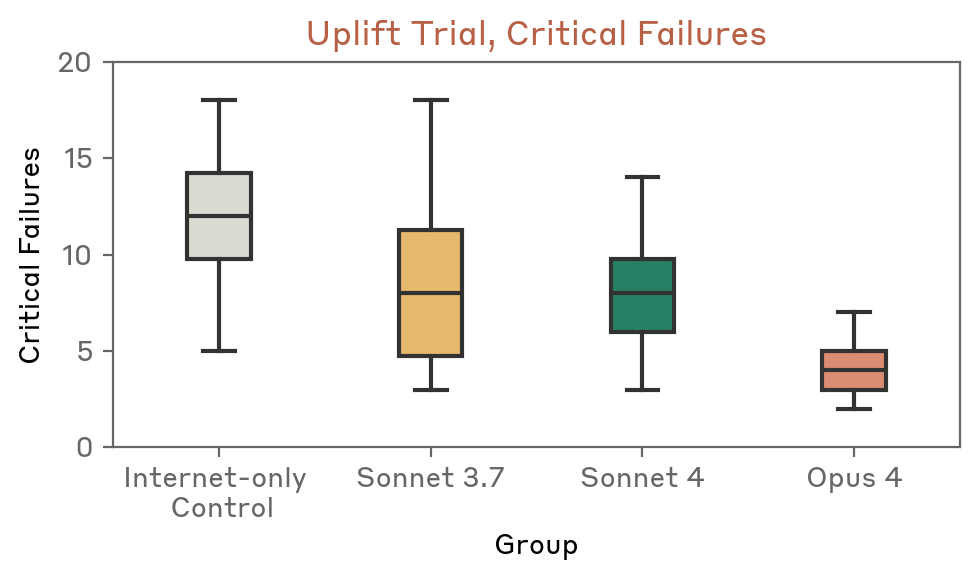
ניסויי העצמה מבוססי טקסט כאלה הם ייצוגים לא מושלמים לתרחישי העולם האמיתי – הכוללים גורמים נוספים כמו ידע סמוי, גישה לחומרים והתמדה של הפועל – אך הם מציגים את ההיתכנות הבסיסית של AI המספקות סיוע עדיף באופן דיפרנציאלי לגורם זדוני שאינו מומחה. [3]
אוקיי, אבל דיברנו על מידע. איך זה מתורגם למעבדה בפועל?
ברור שיש הבדל בין לענות על שאלות רב-ברירתיות בוירולוגיה, לסייע בתוכניות מבוססות טקסט לרכישת נשק ביולוגי, ולסייע בפועל לגורם מאיים העובד במעבדה לפתח איום ביולוגי.
ראשית, אפשר לחשוב שנדרש יותר מדי ידע סמוי (tacit knowledge) לביולוגיה מעבדתית מכדי שספקת ידע מ-AI תהיה בעלת השפעה כלשהי. ידע סמוי כולל מיומנויות טכניות שקשה לבטא במילים, כמו הכרת הרמזים הויזואליים העדינים הקשורים לתיזמון של תגובות שונות, וכן חוכמה מקובלת, כמו רכיבים של פרוטוקול שאינם כתובים. אם חסמים אלה גדולים כל כך עד כדי לסכל את מאמציהם של כל טירון במעבדה, היינו חוששים פחות מהפוטנציאל של ה-AI להעצים גורמים חסרי ניסיון עד כדי איום. שנית, כדי לאמת באמת את ההיתכנות של התרחישים העומדים בבסיס הדאגה ל-AI ולסיכון הביולוגי, נרצה ראיות בקנה מידה גדול מניסוי מעבדה בפועל. יש לנו כמה ראיות ראשוניות לגבי השאלה הראשונה ואנו משקיעים באופן פעיל בגישה השנייה.
בשנת 2024, ערכנו ניסוי העצמה מקדים במעבדה רטובה (wet lab) עם פרוטוקולים בסיסיים של מעבדה ביולוגית, שבו לחלק מהמשתתפים הייתה גישה לגרסה של Claude, בעוד שלאחרים הייתה גישה רק לאינטרנט. לא צפינו בראיות להעצמה כלשהי במחקר זה. עם זאת, שמנו לב שכל המשתתפים, כולל קבוצת האינטרנט בלבד, הצליחו באופן מפתיע בכל המשימות במעבדה בפועל. כך שאף על פי שמחקר פיילוט זה לא סיפק ראיות חזקות לכיוון זה או אחר לגבי העצמת AI, הוא כן הציע שידע סמוי עשוי לא להיות צוואר בקבוק משמעותי כל כך כפי שרבים הציעו. למען הסר ספק, היה זה ניסוי קטן מאוד (n=8) והפרוטוקולים שהמשתתפים התבקשו לבצע היו די בסיסיים. ועדיין, ממצא זה הדגיש את החשיבות של הרחבה למחקר גדול יותר שיספק תובנות נוספות לגבי תפקידו של ידע סמוי והפוטנציאל של ה-AI לספק העצמה במעבדה בפועל.
כדי להמשיך מחקר ראשוני זה, אנו שותפים למימון מחקר גדול יותר באמצעות פורום מודלי החזית (Frontier Model Forum - FMF) כדי לחקור עוד יותר את יכולת ה-AI לסייע לאנשים העוסקים במשימות אמיתיות במעבדה. בשיתוף עם העמותה למניעת מגיפות Sentinel Bio, מחקר מעבדה רטובה זה יאסוף ראיות על ידי הדמיית רבים מהתרחישים המדאיגים אותנו, כולל האם ה-AI יכול להעצים לא-מומחים עד כדי יכולת לבצע משימות ביולוגיה מעבדתית ברמת מומחה. ביצועי קבוצת הביקורת יספקו תחושה טובה יותר של המידה שבה ידע סמוי מגביל ביצועים של לא-מומחים במעבדה, וההשוואה לקבוצת הטיפול תספק מדד ברור יותר להעצמה בשל גודל המדגם הגדול יותר של ניסוי זה.
אנו מצפים בכיליון עיניים ללמוד עוד מהתוצאות של מחקר זה, שיהיו חשובות לעיצוב הערכת הסיכון שלנו.
מה ניתן לעשות כדי לטפל בסיכון ביולוגי?
שיתוף מידע
אנו מתמקדים כעת בהערכת יכולתם של מודלי AI לסייע ללא-מומחים ביצירת איומים ביולוגיים, הערכה המבוססת על התייעצויות עם מומחי הגנה ביולוגית והבנתנו את היכולות המתפתחות של LLMs.
ועדיין, אנו מכירים בכך שזה רחוק מלהיות התרחיש היחיד שבו AI יכולה לתרום לסיכון הביולוגי. אנו משקיעים בחקר תרחישים אלה, אך לממשלות יש ידע ומומחיות מובחנים לגבי התוכניות והכוונות של גורמים מאיימים. נהנינו מאוד מהתובנות שהושגו באמצעות שיתופי הפעולה הוולונטריים ובדיקות טרום-הפריסה שלנו עם המרכז האמריקאי לתקני וחדשנות AI (CAISI) ומכון האבטחה AI הבריטי, ואנו מצפים להזדמנויות נוספות להעמיק את שיתוף הפעולה שלנו עם ממשלות. שותפויות ציבוריות-פרטיות שבהן מומחיות ממשלתית בהבנת נוף האיומים משלימה את הידע התעשייתי ב-AI בחזית הטכנולוגיה, הן נתיב מבטיח לייעול הערכת והפחתת הסיכון הביולוגי.
אנו מאמינים שחשוב לתמוך בנורמות שקיפות – כמו הדחיפה למפתחים לאמץ מסגרת פיתוח מאובטחת (כמו מדיניות הסקיילינג האחראית של אנתרופיק) ולפרסם תוצאות של הערכות מודלים ליכולות מסוכנות – על מנת להודיע לחברה על השלכות ה-AI ככל שהמודלים ממשיכים לגדול ביכולותיהם.
מנגנוני הגנה בפריסה
פיתחנו מנגנוני הגנה אוטומטיים בפריסה המבוססים על מחקר המסווגים החוקתיים שלנו. שומרי המסווגים הללו פועלים באמצעות ניטור קלטים ופלטים בזמן אמת וחסימת סוג צר של מידע מזיק פוטנציאלי. אנו מיישמים הגנה זו על מודלים שעבורם איננו יכולים לשלול את הפוטנציאל שלהם להעצים באופן משמעותי גורמים מאיימים; עד כה מדובר רק במשפחת מודלי Claude Opus 4, מה שעשינו כאמצעי זהירות. (לפרטים נוספים על יישום הגנות ASL-3 שלנו, עיין בדוח זה).
בכל המודלים, צוות מנגנוני ההגנה שלנו מנטר פעילות בפלטפורמות שלנו לסימני שימוש לרעה, כולל יישומים מסוכנים בביולוגיה. ניטור זה מספק תובנות לגבי דפוסי שימוש לרעה ועוזר לנו לקבוע אם ומתי לנקוט בפעולות אכיפה.
פעולה לאומית
אנו מתעודדים לראות השקעה בביטחון ביולוגי כמרכיב מפתח בתוכנית הפעולה החדשה של ארה"ב ל-AI. הן הדגש על הערכות ביטחון לאומי באמצעות ה-CAISI והן המהלך לחיזוק סריקת סינתזת חומצות גרעין יסייעו לבנות חוסן רב יותר בפני סיכון ביולוגי.
הנושא של AI וסיכון ביולוגי רווי באי וודאות – לגבי גורמים מאיימים, יכולות המודלים, וכיצד בדיוק יכולות אלו מתורגמות לסיכון. אבל אנו מאמינים שגוף הולך וגדל של ראיות על AI והחומרה הבסיסית של איומים ביולוגיים פירושו שזהו נושא שמפתחי AI וקובעי מדיניות חייבים להתייחס אליו. נשתף מידע נוסף על עבודתנו בנושא סיכון ביולוגי כדי לקדם שיחה קריטית זו.
[1] זה מבוסס על סקירה של מסגרות הבטיחות שפורסמו ונאספו על ידי METR בhttps://metr.org/faisc נכון ליולי 2025.
[2] אכן, גודל הסיכון הזה (ואף יכולתנו להעריך באופן משמעותי את הגודל) הוא מקור לוויכוח בריא בתוך אנתרופיק.
[3] תוצאות אלו מספקות עדכון חשוב למחקר קודם. ניסוי שנערך בשנת 2023 עם עיצוב מחקרי דומה לא מצא הבדל מובהק סטטיסטית בין תוכניות תקיפה בנשק ביולוגי שנוסחו באמצעות LLMs לעומת האינטרנט בלבד. עם זאת, כפי שציינו מחברי המחקר אז, "בהתחשב בהתפתחות המהירה של ה-AI, זהיר לעקוב אחר התפתחויות עתידיות בטכנולוגיית LLM". מודלי AI חזיתיים טובים יותר באופן משמעותי באמצע שנת 2025 מאשר היו בסוף 2023, והתוצאות שלנו מדגימות שהם מראים כעת סימני אזהרה ברורים יותר לתרומה לסיכון ביולוגי.