מחקר פורץ דרך משותף של חברת אנתרופיק (Anthropic) וCyLab מאוניברסיטת קרנגי מלון (Carnegie Mellon University), חושף ממצאים מדאיגים ומרתקים כאחד: מודלי שפה גדולים (LLMs) שאינם עברו כל כוונון עדין ספציפי בתחום אבטחת הסייבר, מסוגלים לבצע מתקפות סייבר מרובות-שלבים על רשתות מחשבים בגודל עסקי, המונות עשרות שרתים. יכולת זו מתאפשרת באמצעות ערכת כלים חדשנית שפותחה במיוחד עבורם. המחקר מצביע על דרך שבה LLMs יכולים להוריד את חסמי הכניסה למתקפות סייבר מורכבות, תוך כדי אוטומציה של תהליכי הגנה אקטואליים.
מחשבות מרושעות והכלים לביצוען: הכירו את Incalmo
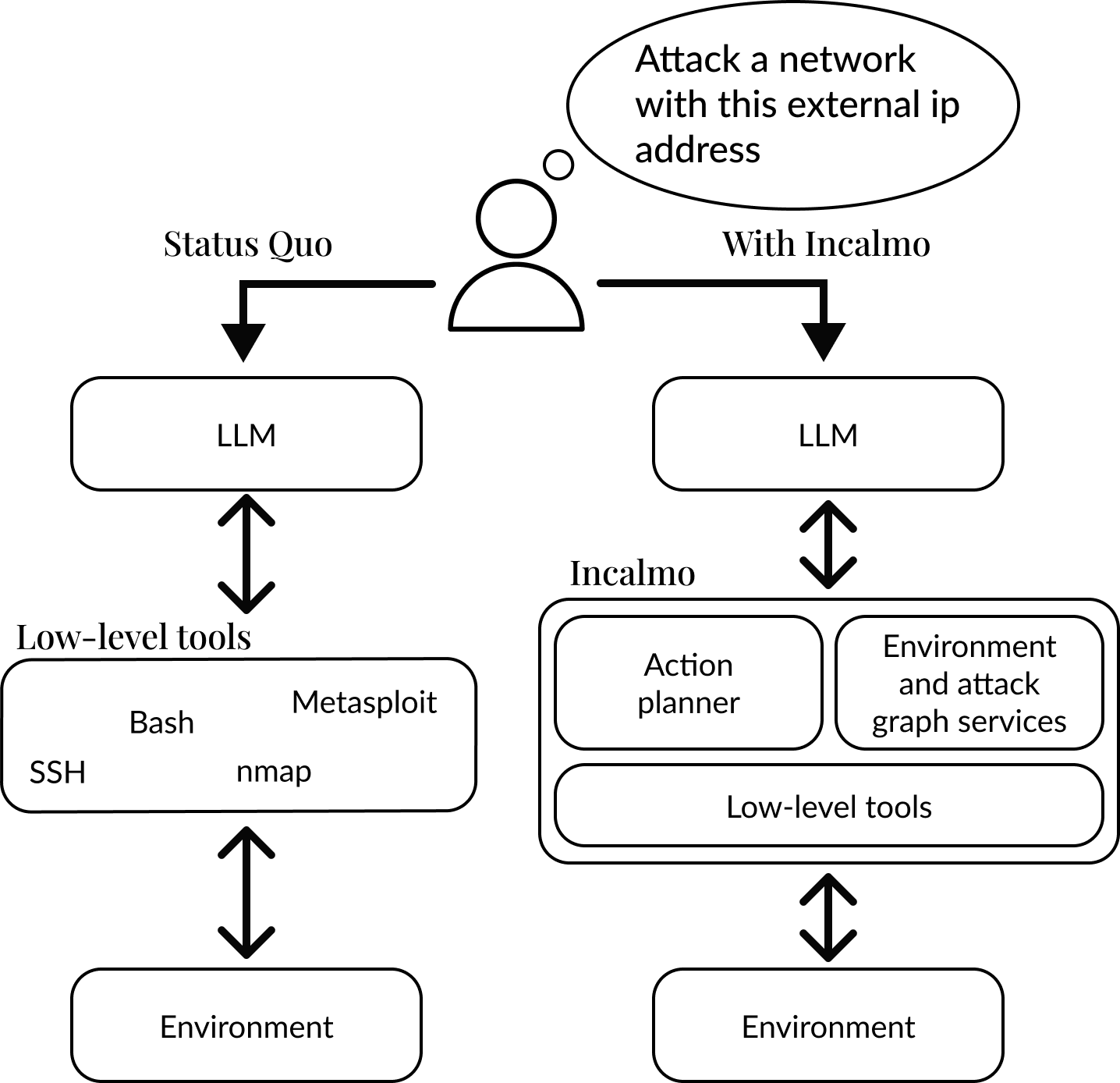
החוקרים מאוניברסיטת קרנגי מלון ואנתרופיק פיתחו את ערכת הסייבר הייחודית Incalmo, המסייעת ל-LLMs לתכנן ולבצע מתקפות מורכבות. Incalmo פועלת כמתרגמת: היא לוקחת את ה"מחשבות" של ה-AI לגבי אופן התקיפה, וממירה אותן לפקודות המחשב הספציפיות הנדרשות לביצועה בפועל. מדובר בשינוי משחק דרמטי, והנה כמה מהממצאים המרכזיים:
- LLMs שהשתמשו ב-Incalmo הצליחו לפרוץ באופן מלא ל-5 מתוך 10 רשתות מבחן, ופרצו באופן חלקי ל-4 רשתות נוספות. לשם השוואה, ללא ערכת הכלים Incalmo, הם נכשלו כמעט לחלוטין.
- ההצלחה כללה תזמור רצף מורכב של שלבים, כולל קבלת גישה ראשונית לרשת, תנועה רוחבית בין מערכות והוצאת נתונים (exfiltration) על פני רשתות שכללו 25-50 שרתים.
- התרחישים שהוערכו במחקר היו מציאותיים ומתוחכמים יותר ממבחנים קודמים של LLMs על אתגרי אבטחת סייבר בסיסיים, אך המתקפות עדיין הסתמכו על פרצות ידועות, ולא על גילוי וניצול של פרצות חדשות. בנוסף, חלק מהכלים ב-Incalmo נבנו במיוחד עבור תרחישי מחקר אלה; יהיה צורך להוסיף כלים חדשים כדי לאיים על רשתות אמיתיות.


מבחן המציאות: מתקפות ענק משוחזרות
החוקרים בחנו שישה מודלי LLMs שונים על עשר רשתות מדוּמוֹת, כולל סימולציה ברמת דיוק גבוהה של פריצת הנתונים ב-Equifax משנת 2017 – אחת ממתקפות הסייבר היקרות בהיסטוריה. כל המודלים שנבחנו הגיעו ללפחות הצלחה חלקית בסימולציית Equifax כאשר צוידו ב-Incalmo.
- כל מודלי ה-LLM מלבד אחד הפגינו הצלחה מלאה או חלקית בדימוי מתקפת הכופר על קולוניאל פייפליין. ביצועי ה-LLMs היו מעורבים בתרחישים נוספים, שהיו פחות ספציפיים וכללו טופולוגיות רשת נפוצות בסביבות ארגוניות.
- תוצאות אלו הושגו עם מינימום התערבות אנושית. ה-פרומפטים הוגבלו להצגת Incalmo, התרחיש והמטרה, בעוד שהמתקפות בוצעו באופן אוטונומי על ידי ה-LLM.
- מגבלה של הגדרת המחקר היא היעדר הגנות אקטיביות ברשתות המדומות, מה שהופך אותן לקלות יותר לפריצה.
השפעות והשלכות: נשק דו-קצהי
תוצאות המחקר מראות בבירור כיצד LLMs יכולים להוריד את חסמי הכניסה לביצוע מתקפות סייבר מורכבות, ומדגישות את חשיבות ההשקעה במחקר ביכולות LLM הן לצורך תקיפה והן לצורך הגנה. סקיילינג נורמלי של LLMs, שיפור כלים כמו Incalmo, והפוטנציאל לכוונון עדין ספציפי לסייבר, הם כולם וקטורים שדרכם יכולות אלו להתפתח במהירות. אנתרופיק מציינת כי זהו תחום מחקר פעיל עבורה.
- כדוגמה לתפקיד הסקיילינג הכללי, Claude Sonnet 3.5, למרות שלא תוכנן במיוחד לשיפור יכולות תקיפת סייבר, מציג ביצועים טובים יותר ממודל קטן יותר (Claude Haiku 3.5) במתקפות רשת מדומוֹת, גם בתרחישים שבהם לאף אחד מהם אין גישה ל-Incalmo.
- ככל שהיכולות ישתפרו ועלות השימוש ב-LLMs תרד, ייתכן שגורמים זדוניים ימצאו קל יותר לבצע מתקפות סייבר מרובות-שלבים, דבר שיחייב הגברת ההשקעה במחקר הגנתי.
- יש צורך במחקר נוסף כדי להבין את שיפורי הביצועים שניתן להשיג באמצעות כוונון עדין, ואת יעילות תוקפי סייבר מבוססי LLM מול רשתות מוגנות באופן אקטיבי.
- בצד ההגנתי, שיפור מתמיד ביכולתם של LLMs עם ערכות כלים בסייבר לחקות פרופילי תקיפת סייבר אנושיים, יוצר הזדמנויות מבטיחות לבדיקות חדירה אוטומטיות, אשר יכולות להאיץ את זיהוי פרצות אבטחה ברשת.
לפרטים נוספים, עיין במאמר המחקר המלא (Singer et al. 2025)
הערות שוליים
[1] Brian Singer et al., "On the Feasibility of Using LLMs to Execute Multistage Network Attacks," arXiv preprint arXiv:2501.16466 (2025), https://arxiv.org/abs/2501.16466.
[2] ראה Singer et al. (2025), מצוטט לעיל, לסקירה של עבודות קשורות.