אנתרופיק מציגה את Claude Sonnet 5

Claude Sonnet 5 הוא המודל הסוכני ביותר בסדרת ה-Sonnet עד כה. הוא תוכנן ליכולת לתכנן משימות, להשתמש בכלים כמו דפדפנים וטרמינלים, ולפעול באופן אוטונומי ברמה שרק לפני מספר חודשים דרשה מודלים גדולים ויקרים יותר.
עבור מפתחים רבים, עידן ה-AI הסוכני החל עם מודלי סדרת Sonnet: Claude Sonnet 3.5, 3.6 ו-3.7 היו המודלים הראשונים שהפגינו יכולות מרשימות בקידוד ושימוש בכלים. אולם, לאחרונה, השיפורים הברורים ביותר ביכולות סוכני AI נראו במודלים מסדרת Opus.
Sonnet 5 מצמצם כעת את הפער: ביצועיו קרובים לאלו של Opus 4.8, אך במחירים נמוכים יותר. מדובר בשיפור משמעותי לעומת קודמו, Sonnet 4.6, בהיבטים חשובים של ביצועים סוכניים כמו חשיבה, שימוש בכלים, קידוד ועבודת ידע:
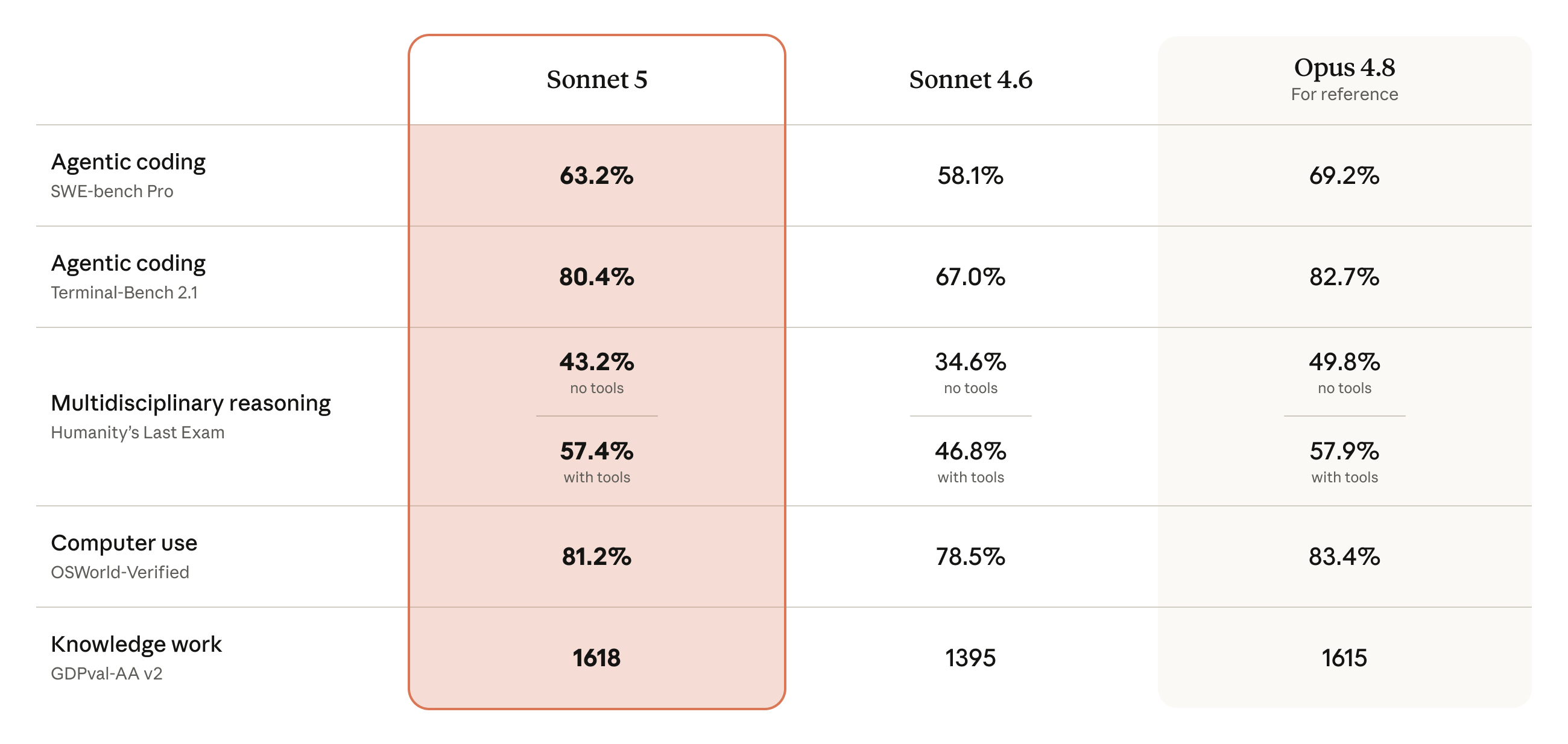
הערכות הבטיחות שלנו מצאו כי Sonnet 5 מציג שיעור נמוך יותר של התנהגויות לא רצויות בהשוואה ל-Sonnet 4.6, והוא בטוח יותר לשימוש בהקשרים סוכניים. הערכות נוספות מראות כי יכולתו לבצע משימות אבטחת סייבר נמוכה בהרבה מזו של מודלי Opus הנוכחיים שלנו.
החל מהיום, Claude Sonnet 5 זמין בכל תוכניות השירות: הוא מודל ברירת המחדל לתוכניות Free ו-Pro, ונגיש למשתמשי Max, Team ו-Enterprise. הוא זמין גם ב-Claude Code וב-Claude Platform, ומושק במחיר היכרות של $2 למיליון טוקנים בקלט ו-$10 למיליון טוקנים בפלט עד 31 באוגוסט 2026, ולאחר מכן יעמוד מחירו על $3 למיליון טוקנים בקלט ו-$15 למיליון טוקנים בפלט. מפתחים יכולים להשתמש ב-claude-sonnet-5 באמצעות Claude API.
עבודה עם Claude Sonnet 5
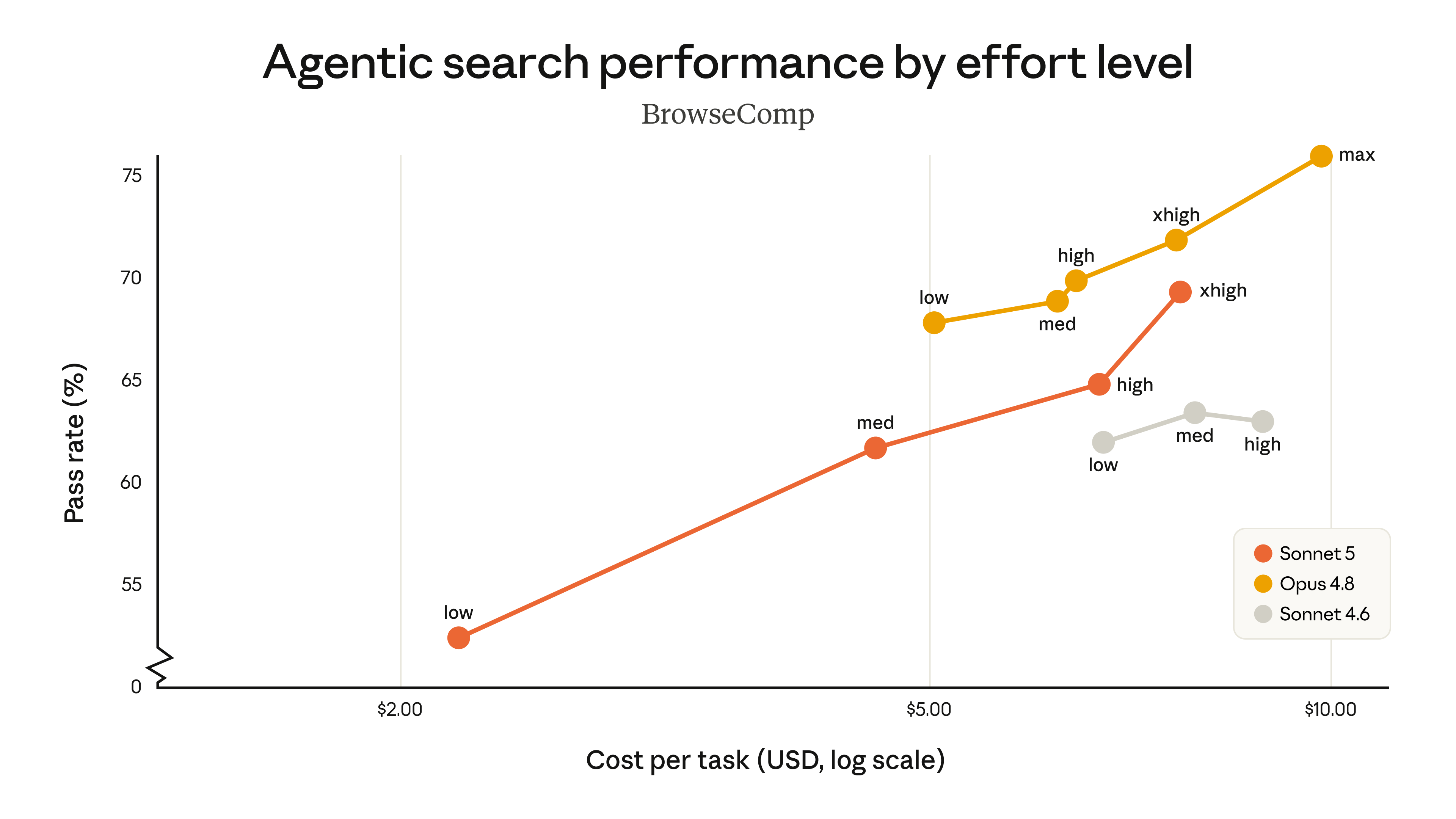
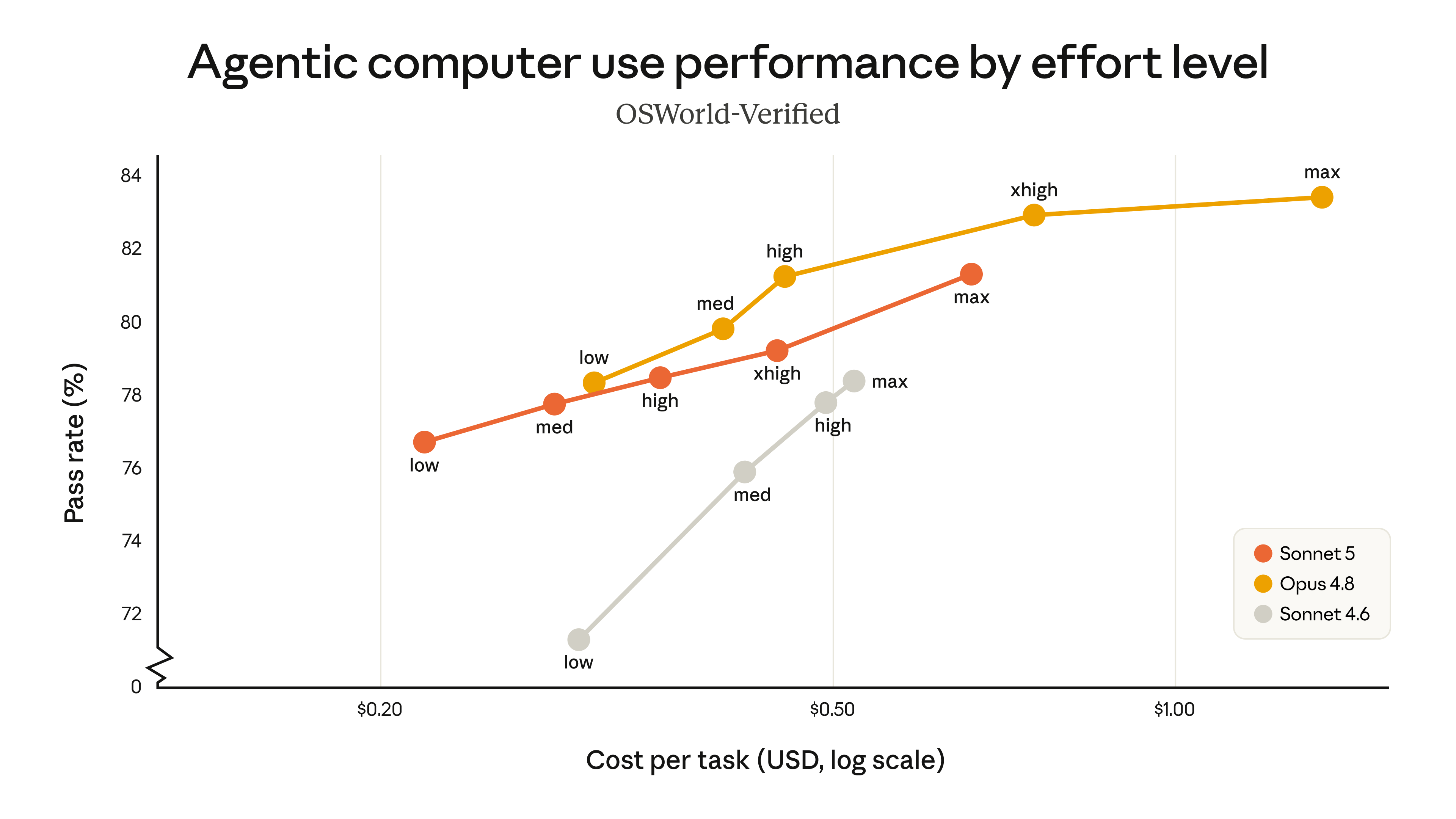
הגרפים מטה משווים את ביצועי Sonnet 5 מול Sonnet 4.6 ו-Opus 4.8 ברמות מאמץ שונות במדד הביצועים הסוכני BrowseComp ובמדד השימוש במחשב OSWorld-Verified. Sonnet 5 (הקו הכתום) מציג שיפור מובהק לעומת Sonnet 4.6 (הקו האפור). Opus 4.8 (הקו הצהוב) עדיין נותר המודל המועדף לדיוק גבוה יותר במשימות אלו, אך Sonnet 5 מספק למפתחים אפשרויות זולות יותר באיכות גבוהה משמעותית מזו שהייתה זמינה בעבר. בין Sonnet 5 ל-Opus 4.8, משתמשים יכולים להתאים את רמת המאמץ כדי למצוא את האיזון הנכון בין עלות לביצועים.
הפידבק משותפי הגישה המוקדמת שלנו היה עקבי: Sonnet 5 סוכני הרבה יותר מקודמיו. בוחנים תיארו כיצד הוא משלים משימות מורכבות שבהן מודלי Sonnet קודמים היו נעצרים באמצע, כיצד הוא בודק את הפלט שלו ללא בקשה מפורשת, וכיצד הוא מבצע את כל העבודה הסוכנית הזו במחיר אטרקטיבי:
"Claude Sonnet 5 מספק לסוכנים שלנו שכבת ביצוע חזקה עבור עבודת הנדסת תוכנה רב-שלבית. הוא מטפל היטב בקידוד מתמשך, שימוש בכלים וניפוי באגים במגוון הקשרים טכניים מורכבים, והיה שימושי במיוחד בתהליכי עבודה שבהם חשיבות ההתמדה וההבנה הטכנית."
"נתנו ל-Claude Sonnet 5 עבודה דו-שלבית – עדכון דרגות חשבון ב-Salesforce, שליחת הודעת השקה לאנשי קשר בארגון – והוא סיים אותה מקצה לקצה. בעבר, משימות כאלו היו נתקעות באמצע. לאוטומציה יומיומית, זוהי בחירה מתבקשת."
"Claude Sonnet 5 משיג יותר בפחות. אותה איכות פלט, פחות צעדים להגיע אליה. הוא גם מסרב לבקשות לא בטוחות באופן נקי ועקבי. ב-Lovable, אנחנו מעניקים כלים עוצמתיים למיליוני בונים. מודל שיודע מתי לומר 'לא' חשוב לא פחות ממודל שיודע לבנות."
"הפעלנו את Claude Sonnet 5 מול עשרות בקשות משיכה (pull requests) המאתגרות ביותר שלנו, והוא הוביל כל אחת מהן לתוצאה שנבדקה ואומתה באופן עצמאי – מה ששחרר את המהנדסים שלנו להתמקד בשיקול הדעת, ההחלטה והאישור הסופי."
"ביקשתי מ-Claude Sonnet 5 לחקור באג. ללא פרומפט, הוא כתב בדיקה משחזרת, יישם את התיקון, ואז שמר אותו בצד כדי לאשר שהבאג חוזר ללא השינוי. הכל במעבר אחד."
"עם Claude Sonnet 5, סוכנים נשארים בתוכנית, עוקבים אחר המוסכמות שלנו, ומספקים שינויים נקיים מרובי-שלבים, והכל בעלות יעילה."
"Claude Sonnet 5 במיטבו עם קוד קיים (brownfield code) – תנאי מרוץ (race conditions), בדיקות נסתרות, החלקים שאף אחד לא רוצה לגעת בהם. הוא מאתר כשל עד לשורש הסיבה האמיתית שלו ומספק תיקון עמיד במקום לטפל רק בסימפטום."
"Claude Sonnet 5 נמצא בחזית פארטו (Pareto frontier) עבור משימות תביעות משפטיות של Eve. אנו רואים את הרווחים הברורים ביותר במחקר וניתוח משפטי, ביחס מחיר-לביצועים שהפך את ההחלטה להגרציה לקלה."
"סוכני ClickHouse חוקרים נתונים חיים ומפיקים תובנות באופן מיידי, כך שזמן-לתובנה חשוב בעת בדיקת מודלים חדשים. Claude Sonnet 5 מבצע הסקה בצעדים הדוקים יותר ומביא את המשתמשים שלנו לתשובות מהר יותר באופן ניכר. מהירות זו היא הבדל שלקוחותינו מרגישים."
"ב-Pace, סוכני השימוש במחשב שלנו מריצים תהליכי עבודה ביטוחים – קליטת הגשות, הודעות ראשונות על אובדן (FNOL), דוחות הפסדים – על המערכות שצוותי התפעול שלנו כבר משתמשים בהן. Claude Sonnet 5 נוקט באופן עקבי בפעולה הנכונה ועושה זאת במהירות, וזה מה שעבודת ביטוח אמיתית דורשת."
הערכות בטיחות
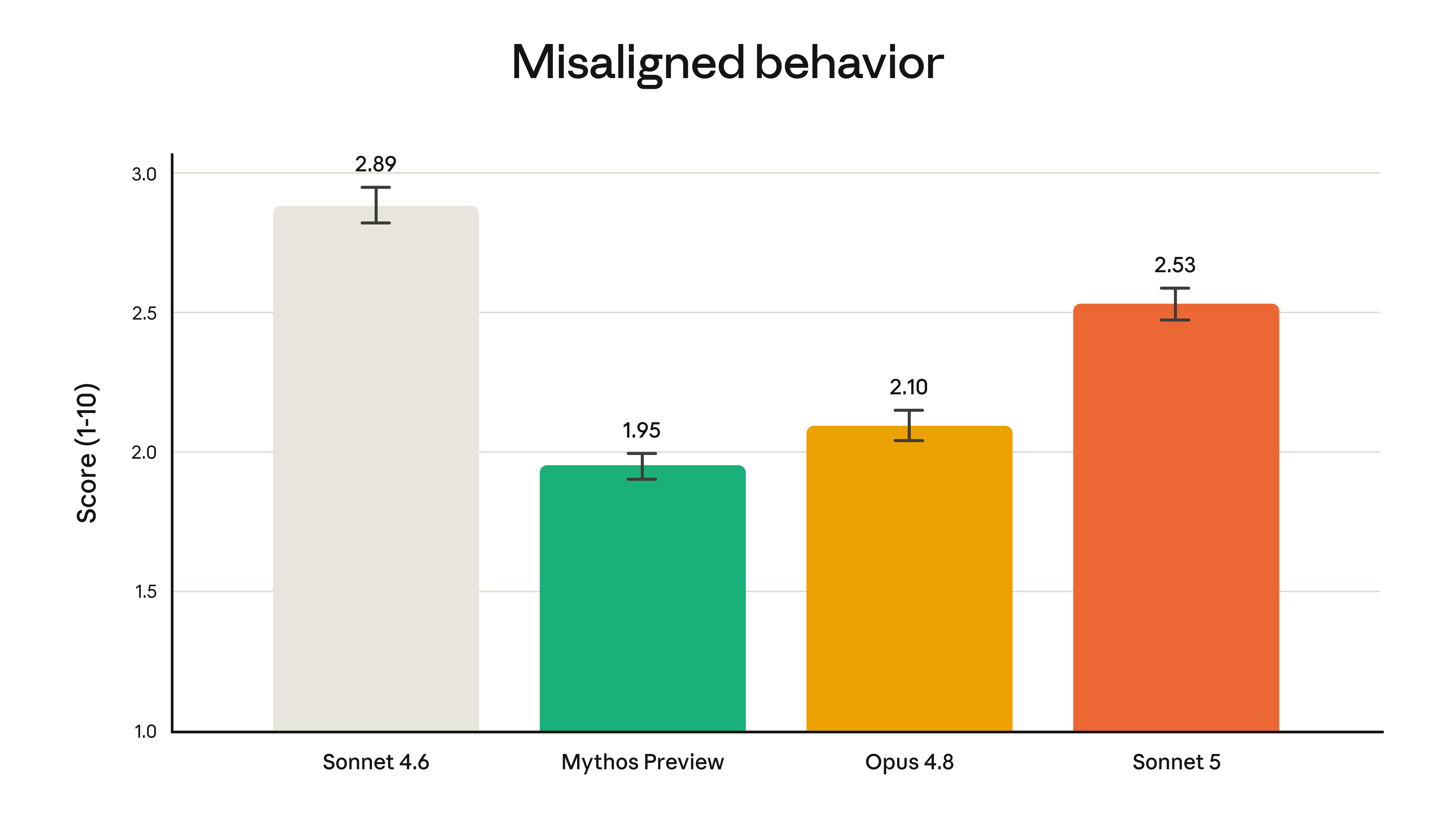
הערכות הבטיחות שערכנו לפני הפריסה מצאו ש-Sonnet 5 מהווה שיפור כולל לעומת Sonnet 4.6. בבטיחות סוכנית, המודל טוב יותר בסירוב לבקשות זדוניות ובהתנגדות לניסיונות חטיפה בהתקפות הזרקת פרומפטים. המודל מציג שיעורים נמוכים יותר של הזיה וסגפנות (sycophancy) מאשר Sonnet 4.6. במבדק ההתנהגות האוטומטי שלנו, הבודק מגוון רחב של התנהגויות לא מיושרות כמו שיתוף פעולה עם שימוש לרעה והונאה, Sonnet 5 קיבל ציון נמוך יותר (כלומר, בטוח יותר) בסך הכל. עם זאת, הוא כן הראה שיעורים גבוהים יותר של התנהגות לא מיושרת בהערכה זו בהשוואה למודלים היכולים יותר Opus 4.8 ו-Claude Mythos Preview.
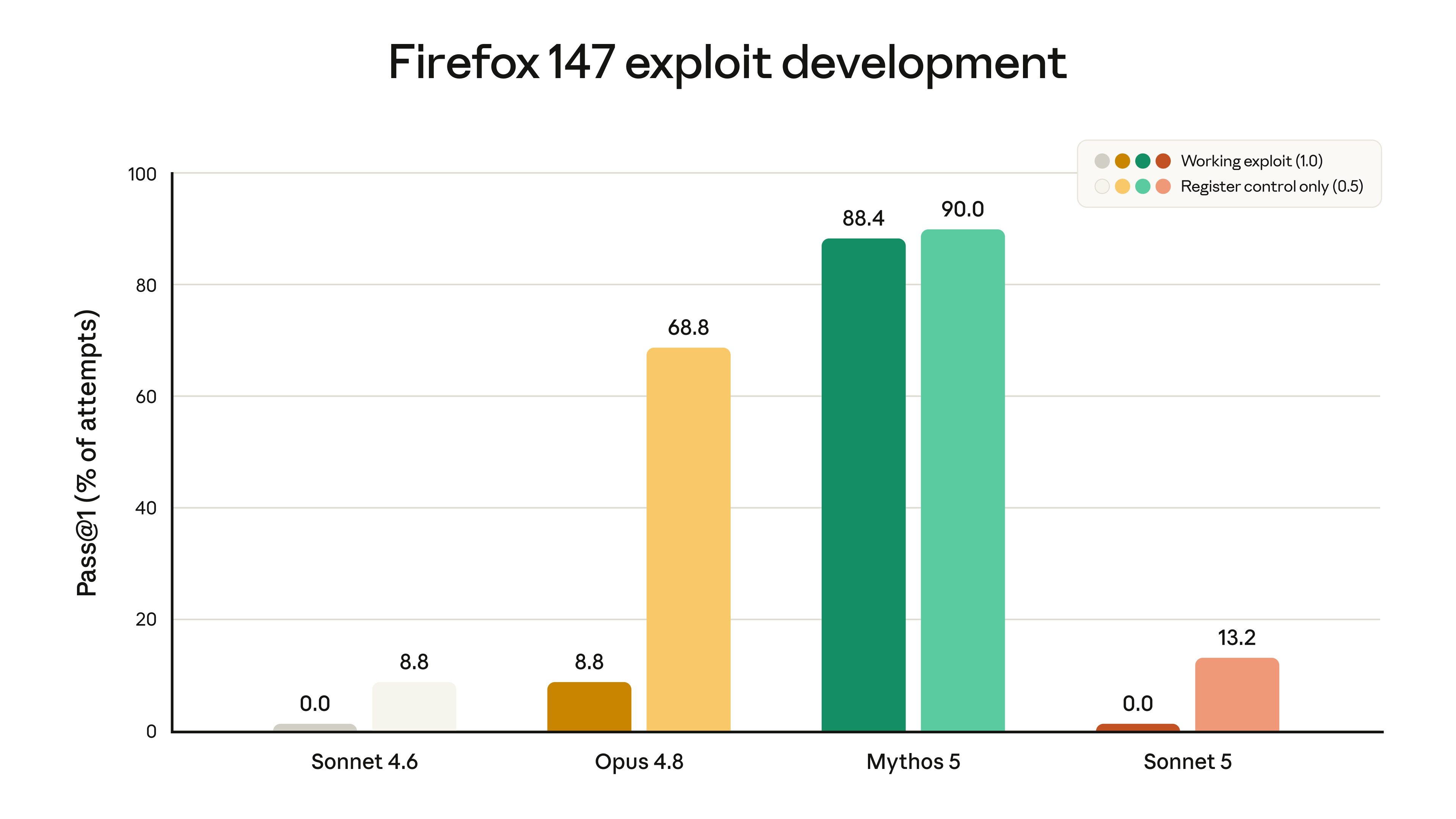
לא אימנו את Sonnet 5 במכוון על משימות אבטחת סייבר. הוא יכול לבצע מספר משימות סייבר שגרתיות ולא מזיקות, אך בהערכות הבוחנות כישורי סייבר שעלולים להיות מסוכנים, כמו פיתוח אקספלויטים (exploits) לתוכנה, הוא מציג ביצועים ירודים משמעותית ממודלים כמו Opus 4.8 ו-Mythos 5. ציונים מהערכה אחת, שבחנה את יכולת המודלים לפתח אקספלויטים לפגיעויות בדפדפן Firefox, מוצגים בגרף מטה. Sonnet 5 מעולם לא הצליח לפתח אקספלויט עובד מלא, אך הוא כן מציג שיעור מעט גבוה יותר של הצלחה חלקית מאשר Sonnet 4.6. שינוי אחרון זה נובע ככל הנראה משיפורים באינטליגנציה הכללית ולא מאימון ספציפי.
מכיוון ש-Sonnet 5 חזק במקצת מקודמו במשימות אלו, השקנו אותו עם מנגנוני הגנה מופעלים כברירת מחדל. מנגנוני הגנה אלו – המזהים וחוסמים שימוש סייברי מסוכן בזמן אמת – זהים לאלה הקיימים ב-Claude Opus 4.7 ו-4.8 (מכיוון ששיערנו שרמת הסיכון הכוללת מ-Sonnet 5 בתחום אבטחת הסייבר נמוכה, מנגנוני ההגנה פחות מחמירים מאלה שהושקו עם Fable 5, החוסמים מגוון רחב יותר של משימות אבטחת סייבר).
הערכה המלאה שלנו ל-Sonnet 5 על פני הערכות בטיחות ויכולות רבות מפורטת ב-Claude Sonnet 5 System Card.
זמינות ותמחור
Claude Sonnet 5 זמין בכל מקום החל מהיום במחיר היכרות של $2 למיליון טוקנים בקלט ו-$10 למיליון טוקנים בפלט עד 31 באוגוסט 2026. לאחר מכן, הוא יעבור לתמחור סטנדרטי של $3 למיליון טוקנים בקלט ו-$15 למיליון טוקנים בפלט. הגדלנו את מגבלות הקצב (rate limits) ברחבי Chat, Cowork, Claude Code ו-Claude Platform כדי להתאים את השימוש הגבוה יותר בטוקנים ברמות מאמץ גבוהות יותר; משתמשים יכולים לבחור את הרמה המתאימה לפרויקט הספציפי שלהם.
הערות שוליים
1 Sonnet 5 הוא חלק מ-תוכנית אימות הסייבר שלנו, הזמינה כיום ב-Claude Platform המקורית, ב-Claude Platform ב-AWS, וב-Claude ב-Microsoft Foundry (המתארחת ב-Azure וב-Anthropic), ובקרוב תהיה זמינה ב-Claude ב-Google Vertex. ארגונים שכבר רשומים לתוכנית אימות הסייבר מקבלים באופן אוטומטי את אותה גישה ב-Sonnet 5, ללא צורך בהגשה חוזרת. בסך הכל, אנו ממליצים על Claude Opus 4.8 לעבודת אבטחת סייבר הדורשת מנגנוני הגנה מופחתים.
2 Sonnet 5 הוא שדרוג ל-Sonnet 4.6, אך הוא משתמש בטוקנייזר (tokenizer) מעודכן המשנה את אופן עיבוד הטקסט על ידי המודל לשיפור הביצועים (זה דומה לשינוי הטוקנייזר שהצגנו עם Claude Opus 4.7). הפשרה היא שאותו קלט יכול למפות ליותר טוקנים: בערך פי 1.0–1.35 בהתאם לסוג התוכן. מחיר ההיכרות נקבע כך שהמעבר ל-Sonnet 5 יהיה בקירוב ניטרלי מבחינת עלות.
3 ב-26 באפריל 2026, העלינו את מגבלות הקצב (rate limits) של Sonnet ו-Haiku בכל רמת שימוש ופשטנו לשלוש רמות (Start, Build ו-Scale) ב-Claude Platform המקורית. תוכלו לצפות ברמת השירות ובמגבלות הנוכחיות שלכם ב-Claude Console או לקרוא את ה-תיעוד כדי ללמוד עוד.
- Humanity’s Last Exam: עדכנו את מודל הבודק עבור Humanity’s Last Exam ועדכנו את ציון Sonnet 4.6 ל-34.6% (ללא כלים) ו-46.8% (עם כלים). זו הסיבה שהציון שונה מזה שדווח ב-בלוג ההשקה של Sonnet 4.6.
- OSWorld-Verified: ביצענו שינויים באופן שבו אנו מריצים את הערכת OSWorld-Verified כדי לשקף בצורה מדויקת יותר את ביצועי המודל בעולם האמיתי, ועדכנו את ציון Sonnet 4.6 ל-78.5%. זו הסיבה שהציון שונה מזה שדווח ב-בלוג ההשקה של Sonnet 4.6.