מיפוי איומי סייבר מבוססי AI: תובנות מה-LLM ATT&CK Navigator
Kyla Guru, Alex Moix, and Jacob Klein
במהלך השנה האחרונה חקרנו כיצד שחקני איום מנצלים בינה מלאכותית (AI) לביצוע פעולות סייבר. היום, אנו מפרסמים ניתוח חדש הממפה את המתקפות האמיתיות הללו למסגרת MITRE ATT&CK, מאגר של טקטיקות וטכניקות המשמשות תוקפי סייבר. פעולה זו חושפת דפוסים המאתגרים הנחות מסורתיות לגבי אבטחת סייבר – לדוגמה, ניתן להעריך את רמת הסיכון ששחקן איום מציב באמצעות מדדים כמו תחכום טכני או רוחב הטכניקות. שיתפנו פעולה עם ורייזון (Verizon) כדי לכלול חלק מהתוצאות הללו בדו"ח Verizon Data Breach Investigation Report (DBIR) 2026, ואנו מפרסמים דוח זה כדי להציע ניתוח מורחב יותר של המגמות שאנו רואים בפעולות סייבר מבוססות AI. [1]
פתח את ה-Navigator האינטראקטיבי בלשונית חדשה.
ממצאים עיקריים
לצורך מחקר זה, ניתחנו 832 חשבונות הקשורים לפעילות סייבר זדונית במהלך שנה אחת, ממרץ 2025 ועד מרץ 2026. אנתרופיק חסמה את החשבונות הללו משימוש בקלוד (Claude) עקב הפרת מדיניות השימוש שלנו. החשבונות בניתוח זה הם רק תת-קבוצה מבין אלה שחקרנו וחסמנו במהלך תקופה זו; בחרנו אותם מכיוון שהיה לנו מספיק פירוט על פעילויותיהם הזדוניות כדי למפות את הטכניקות שלהם למסגרת MITRE ATT&CK.
832 החשבונות בניתוח שלנו השתמשו במודלי AI לכל 14 הטקטיקות ו-482 תתי-טכניקות ייחודיות במסגרת, החל מאיסוף מודיעין ראשוני ועד להשפעה הסופית. [2] פיתחנו גם מסגרת ניקוד סיכון (שתתואר בהמשך פוסט זה) כדי להעריך כמה סיוע AI עזר לשחקנים אלו לתכנן את מתקפותיהם. באופן בולט ביותר, גילינו שאחוז השחקנים המסווגים בסיכון בינוני ומעלה קפץ מ-33% ל-56% בין המחצית הראשונה לשנייה של השנה. נתון זה מצביע על כך ש-AI מסייע לתוקפים לבצע פעולות סייבר מתוחכמות יותר בקלות רבה יותר.
להלן שלושה ממצאים עיקריים מהניתוח שלנו:
- מספר השחקנים המשתמשים ב-AI לפעולות סייבר גדל, ופעולותיהם נושאות סיכון גבוה יותר. כפי שצוין לעיל, אחוז השחקנים בסיכון בינוני או גבוה גדל פי 1.7 בפחות משנה, מ-33% במחצית הראשונה של תקופת המחקר שלנו ל-56% בשנייה. גידול זה מרוכז בשחקנים המשתמשים ב-AI עבור חלק מהפעילויות המזיקות ביותר, כולל תנועה רוחבית, גניבת פרטי גישה (credential dumping) ו-Web Shells – הנושאים את משקל הסיכון הגבוה ביותר לכל שחקן בניקוד שלנו, ולא עבודות בנייה והסוואה שוליות השולטות בשאר האוכלוסייה. באופן מסורתי, רק השחקנים המתוחכמים ביותר מבחינה טכנית יכלו לפעול לרוחב כל שרשרת ההרג (killchain), או השלבים הרציפים של מתקפת סייבר. אך הניתוח שלנו מצא שזה כבר לא המצב. הפלטפורמה דרכה הם ניגשים למודל (כגון API או פלטפורמת קידוד סוכני כמו Claude Code) גם היא אינה משפיעה על מידת הסיכון הגבוה של פעולותיהם. מה שכן מבדיל את השחקנים בעלי הסיכון הגבוה ביותר הוא אילו טכניקות הם מבקשים מהמודל.
- פיגומים סוכנייים (agentic scaffolding) יאפשרו למתקפות סייבר להיות אוטונומיות הרבה יותר. ככל שטכניקות סייבר מבוססות AI יהפכו נפוצות יותר בקרב אוכלוסייה זו, יהיה קשה יותר להבחין ברמת הסיכון של שחקן בהתבסס על מה שהוא מבקש ממודל לעשות. במקום זאת, הגורם המבדיל יהיה הפיגומים – הקוד, הארכיטקטורה והכלים שמסביב, ההופכים את מודלי ה-AI ליעילים יותר – ששחקנים בונים מסביב למודל כדי שיוכלו לקשור יחד שלבי תקיפה באופן אוטונומי. זה היה בולט במיוחד בקמפיין ריגול סייבר ששיבשנו בנובמבר 2025, שהשיג ציון סיכון מקסימלי של 100 אך השתמש במספר טכניקות הדומה לזה של שחקנים בסיכון בינוני. מתקפה זו נבדלה לא בגלל מספר הטכניקות שהשתמשה בהן, אלא בגלל האופן שבו התוקפים השתמשו בסוכן AI כדי לתזמר אותן.
- מסגרת MITRE ATT&CK אינה מכסה עדיין את הפעולות האוטונומיות ההופכות שחקנים אלו למסוכנים כל כך. תזמור אוטונומי של שרשרת ההרג, החלטות ציר תנועה בזמן אמת וביצוע מונחה AI ללא התערבות אנושית – כל אלה אינם בעלי מספרי זיהוי במסגרת ATT&CK עדיין. הדוח שלנו כלל 13,873 תצפיות של פעילות זדונית, כולן מופו לקטגוריות שהוגדרו במסגרת – אך ההתנהגויות המבדילות את השחקנים בעלי הסיכון הגבוה ביותר, וקובעות את מהירות וקנה מידה של פעולותיהם, עדיין אינן בעלות מספרי זיהוי כאלה. הטקסונומיה שעליה מסתמך מודיעין האיומים המודרני צריכה לצמוח כדי ללכוד אותן.
בעוד Claude Mythos Preview מדגים לאן מועדות פני יכולות הסייבר של AI חזיתי – מודלים המסוגלים למצוא ולנצל פגיעות ברמה המתקרבת לזו של חוקרים אנושיים מיומנים ביותר – דוח זה מספר לנו כיצד שחקני איום מנצלים לרעה מודלים זמינים לציבור כיום. הוא גם משמש כמדריך לאופן שבו שחקני איום צפויים לנצל לרעה מודלים בעלי יכולות הולכות וגדלות בעתיד הקרוב, ובכך נותן למגנים הזדמנות להקדים אותם.
מה שלמדנו מניתוח זה ומניתוחים אחרים מעצב באופן ישיר את האופן שבו אנו בונים את קלוד כדי למנוע שימוש לרעה כזה. לדוגמה, עדכנו את המסווגים המובנים בקלוד כדי לזהות את השחקנים בסיכון הגבוה ביותר, והרחבנו את זיהויי הבוחנים שלנו כדי לכסות אינדיקטורים התנהגותיים בסיכון גבוה שנחשפו בניתוח זה. ממצאים אלו מצביעים על נוף שבו קו ההפרדה בין שחקנים בסיכון נמוך לגבוה אינו עוד מיומנות טכנית אלא תזמור, ושבו הגנות, זיהויים, והמסגרות המשותפות שעליהן כולנו מסתמכים יצטרכו להתפתח במהירות כמו המתקפות שהם מתארים.
אודות מערך הנתונים
הממצאים בדוח זה נשאבו מ-832 חשבונות שאנתרופיק חסמה עקב הפרת חלקים ממדיניות השימוש שלה הקשורים לסייבר בין מרץ 2025 למרץ 2026. זיהינו חשבונות אלה באמצעות שילוב של אמצעי הגנה אוטומטיים וחקירות של צוות מודיעין האיומים שלנו. עבור כל חשבון, הפקנו סיכום של הפעילות שנצפתה. לאחר מכן, חילצנו את הטקטיקות, הטכניקות והפרוצדורות (TTPs) המתוארות בסיכומים אלו, ומיפינו אותן לגרסת MITRE ATT&CK framework שהייתה פעילה באותה עת (V18). בסך הכל, צפינו ב-13,873 פעולות על פני 482 טכניקות ייחודיות וכל 14 הטקטיקות של ATT&CK.
הענקנו לכל שחקן ציון סיכון מ-0 עד 100 (כאשר 0 הוא הסיכון הנמוך ביותר ו-100 הוא הגבוה ביותר) בהתבסס על מתודולוגיה חדשה שפיתחנו הנקראת AI Risk Enablement Score (ARiES), המתוארת להלן. הנתונים עברו אנונימיזציה כך שלא ניתן לזהות שחקנים בניתוח הבא.
ה-LLM ATT&CK Navigator וציון הסיכון ARiES
כחלק מניתוח זה, פיתחנו את ה-LLM ATT&CK Navigator: מסגרת אינטראקטיבית הממפה דפוסי שימוש לרעה מבוססי AI שנצפו למסגרת MITRE ATT&CK ומעניקה ציון סיכון ARiES לשחקן. ARiES הוא ציון משולב הבנוי משלושה אותות: פרופיל האיום של השחקן, תרומת המודל לנזק המבוקש וההשפעה שנצפתה או הפוטנציאלית. הוא מחושב על בסיס פעילות השחקן על פני Claude.ai, Claude Code וה-API שלנו, תוך הסתמכות על מסווגי הבטיחות שלנו לצד אינדיקטורים פנימיים וחיצוניים של מודיעין איומים. ככל שהציון גבוה יותר, כך שחקן ה-AI הממונע הוא בעל סיכון גבוה יותר.
המסגרת שלנו מנקדת טכניקות וחשבונות בודדים על פני שלושה ממדים:
- איום (0–35 נקודות): מעריך את בהירות כוונת השחקן, תחכומו הטכני, אותות מודיעין איומים וטקטיקות שבהן השתמש החשבון כדי להתחמק מזיהוי. תחכום טכני מדורג על ידי קלוד על בסיס הפרומפטים (prompts) ושימוש הכלים של השחקן, תוך מדידת המומחיות הנדרשת, מיומנות המפעיל, שימוש בכלים ייעודיים לעומת כלים כלליים ועומק היכולת.
- פגיעות (0–35 נקודות): מעריך את יכולת המודל לאפשר את הנזק המבוקש ואת פרופיל הסיכון של הממשק ששימש. ממשקים תכנותיים (כגון API) וכלי קידוד סוכניים (agentic coding tools) כמו Claude Code מקבלים את הציון הגבוה ביותר בשל הפוטנציאל שלהם לאוטומציה של פעולות.
- השפעה (0–30 נקודות): לוכד את ההשפעות בעולם האמיתי של התנהגות המשתמש באמצעות ציונים שהוקצו על ידי מסווגי הבטיחות שלנו והערכת החוקרים לגבי השלכות בפועל או פוטנציאליות המיוחסות למעורבות ה-AI בפעולה.
יחד, רכיבים אלה מייצרים ציון סיכון כולל מ-0 עד 100, המאפשר לנו לסווג שחקני איום וטכניקות לרמות סיכון נמוכה, בינונית, גבוהה וקריטית.
הערה על נוסחת הניקוד
משוואות סיכון סייבר מסורתיות מבטאות סיכון כ-איום × פגיעות × השפעה – מודל כפלי המשקף האם מתקפה היפותטית צפויה להצליח. במודל זה, אם אחד מהגורמים הוא אפס, הסיכון הכולל מתאפס, מכיוון שמרכיב חסר פירושו שהמתקפה לא תצליח.
המודל שלנו משתמש בכוונה בחיבור ולא בכפל כדי שנוכל לענות על השאלה, "אילו שחקנים וטכניקות מעורבי AI מצדיקים את מירב תשומת הלב מצד המגנים?" רצינו ציון שיישאר משמעותי גם כאשר ממד אחד חסר או לא ברור, דבר שהמודל הכפלי אינו מאפשר. שקלו את התרחישים הבאים:
יכולת והשלכה גבוהות, אך ללא כוונה ברורה. דמיינו משתמש חסר ניסיון אשר, באמצעות ניסויים עם כלי קידוד סוכני, מייצר בטעות יכולות התקפיות פונקציונליות, כמו אקספלויט (exploit) מתפשט (wormable exploit). הכוונה היא למעשה אפסית, כך שציון כפלי ירשום זאת כחוסר סיכון. אך במציאות, המודל עדיין סיפק סיוע משמעותי למתקפה פוטנציאלית, והאינטראקציה בהחלט שווה הצפה כדי שניתן יהיה לפרוס אמצעי הגנה נוספים.
כוונה ויכולת ברורות אך ללא קורבן מזוהה. כעת שקלו שחקן עם כוונה זדונית מפורשת המנצל לרעה את קלוד כדי לפתח נוזקה פעילה, אך אין לנו הוכחות לפריסה או להשפעה עתידית – עדיין. המודל הכפלי יאפס שוב את הציון בממד "השפעה", אף על פי שאות סיוע ה-AI – העובדה שיריב הצליח לפתח בהצלחה תוכנה מזיקה באמצעות המודל – הוא בדיוק מה שאנו רוצים שמערכות הזיהוי שלנו יתפסו מוקדם.
לעומת זאת, המודל החיבורי שלנו שומר על אותות מכל ממד באופן עצמאי, כלומר דפוסי סיוע חלקי למתקפה נשארים גלויים. הפשרה היא שהציונים שלנו אינם תחזיות האם מתקפה תצליח; אלא הם מדדים עד כמה מקרה שימוש לרעה מעורב AI מדאיג. כפי שנדון בהמשך, אנו יכולים גם להשתמש בציונים אלה כדי לראות אילו חלקים ספציפיים של מסגרת ATT&CK מדאיגים ביותר, ולתאם אותם עם המקומות שבהם פועלים שחקנים בסיכון גבוה.
כיצד שחקני איום סייבר משתמשים ב-AI כיום
הניתוח האמפירי שלנו של 13,873 טכניקות שנצפו חושף דפוסים ברורים באופן שבו יריבים משתמשים ב-AI לאורך מחזור חיי המתקפה, ואת הטכניקות הנפוצות ביותר שעבורן מודלים משמשים כיום.
פיתוח יכולות בסיוע AI
משפחת הטכניקות הנפוצה ביותר שצפינו בה הייתה ATT&CK ID T1587 (פיתוח יכולות), שבה השתמשו 574 מתוך 832 השחקנים בניתוח שלנו, או 69%. רוב ההתנהגות הזו מתבטאת כ-T1587.001 (פיתוח נוזקות), שבה השתמשו 560 שחקנים. בפועל, אנו רואים שחקני איום מנצלים לרעה מודלים לבנייה וליטוש של סקריפטים מותאמים אישית להרצה, כתיבת קוד הזרקת DLL עם הנחיות מפורטות כיצד ליישם אותו, כמו גם התחמקות מזיהוי 'טביעת אצבע' של Canvas וניהול חשבונות אוטומטי.
הטכניקות הנפוצות הבאות הן T1027 (קבצים או מידע מוסווים), שבה השתמשו 64.7% משחקני האיום; T1005 (נתונים ממערכת מקומית), שבה השתמשו 55.9% משחקני האיום; ו-T1562 (פגיעה בהגנות), שבה השתמשו 54.9% משחקני האיום. יחד, טכניקות אלו מראות ששחקני איום מבקשים לרוב עזרה מ-LLM לבניית כלי תקיפה התחלתיים, הפיכת כלים אלה לקשים יותר לזיהוי, ואיסוף נתונים ממערכות שנפרצו.
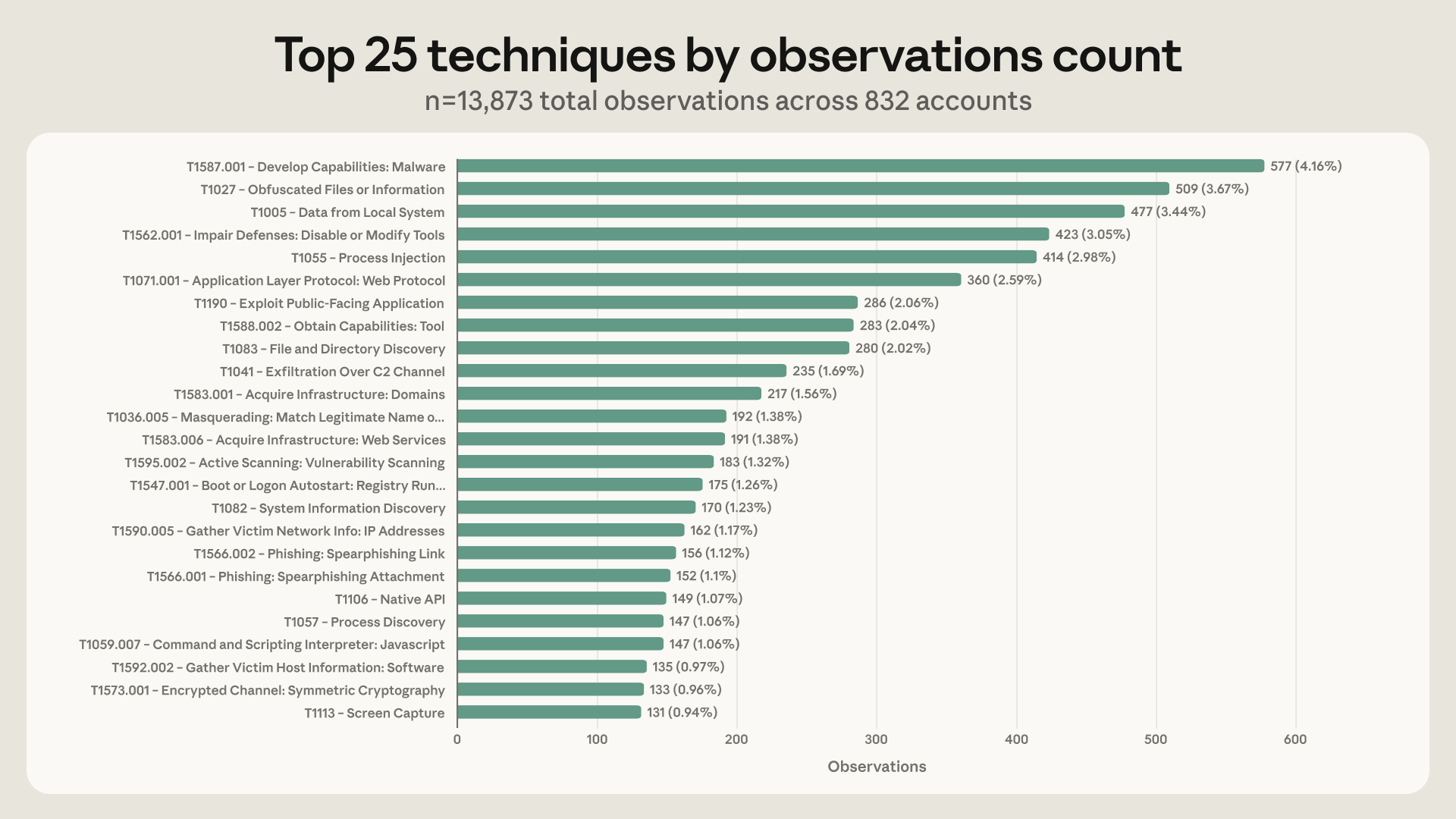
מצד שני, שחקנים נוטים פחות להשתמש ב-LLM לקבלת החלטות בזמן אמת, אדפטיביות, לאחר שחדרו לרשת היעד. לדוגמה, רק 54 מתוך 832 שחקני איום (6.5%) משתמשים במודלים לתנועה רוחבית, ופחות מ-12 שחקנים משתמשים במודלים לשירותים מרוחקים כמו RDP, SSH ו-SMB. רק 22.5% מהשחקנים משתמשים ב-LLM להרחבת הרשאות ושלבי השפעה.
משפחות טכניקות מסוימות שהן עמודי תווך במתקפות סייבר בעולם האמיתי – כמו ניצול Active Directory, מתקפות כרטיסי Kerberos, מניפולציה של תשתית ענן (AWS, Azure, GCP) ופריצת קונטיינרים – מיוצגות באופן נמוך באופן ניכר בתוך מערך הנתונים.
הטכניקות המובילות והתדירות שבהן השתמשו בהן השחקנים לא השתנו רבות במהלך תקופת השנה שבדקנו. הן במחצית הראשונה והן בשנייה של התקופה, מספר הטכניקות החציוני שבהן נעשה שימוש במודל הוא 16. במחצית השנייה של השנה, אנו רואים שינוי כיווני עדין, כאשר שחקני איום משתמשים במודלים פחות לבניית נוזקות עצמאיות או סקריפטים להסוואה ויותר כדי לסייע בשלבי פעולה ספציפיים במתקפת סייבר, ועבור טכניקות גילוי ואיסוף בתוך היעד. באופן ספציפי, אנו רואים עלייה של 8.9% באירועי T1087 (גילוי חשבונות), כמו גם עלייה של 6.2% ב-T1020 (הוצאת נתונים אוטומטית), לצד ירידה של 12% ב-T1587 (פיתוח יכולות) וירידה של 8.6% ב-T1566 (פישינג).
טקטיקות התחמקות בסיוע AI
התחמקות מהגנה (Defense Evasion) היא קטגוריית הטקטיקות הגדולה ביותר במערך הנתונים, והיא נוכחת בהתנהגותם של 84.4% מהשחקנים שבדקנו. MITRE מגדירה 64 טכניקות תחת "התחמקות מהגנה" (במסגרות ה-Enterprise וה-Mobile הספציפיות שלה); אנו צופים ב-32 מהטכניקות הללו במערך הנתונים שלנו: 25 עבור Enterprise ו-7 עבור Mobile.
הטכניקות המובילות שנצפו במסגרת טקטיקה זו כוללות:
- T1027 (קבצים או מידע מוסווים). 64.7% משחקני האיום במדגם שלנו השתמשו ב-AI ליישום טכניקות כמו קידוד XOR/base64, וריאנטים פולימורפיים ועוטפים נגד זיהוי כדי להתחמק מזיהוי מבוסס חתימות.
- T1562 (פגיעה בהגנות). 54.8% משחקני האיום שנבדקו השתמשו ב-AI כדי לעקוף, להשבית או לחבל בכלי אבטחה בנקודות קצה.
- T1055 (הזרקת תהליכים). 30.3% מהשחקנים השתמשו ב-AI כדי לכתוב קוד זדוני שניתן להזריק לתהליכים לגיטימיים, כגון ריקון תהליכים (process hollowing) והזרקת DLL, כדי לבצע מטענים מזיכרון תהליכים מהימן.
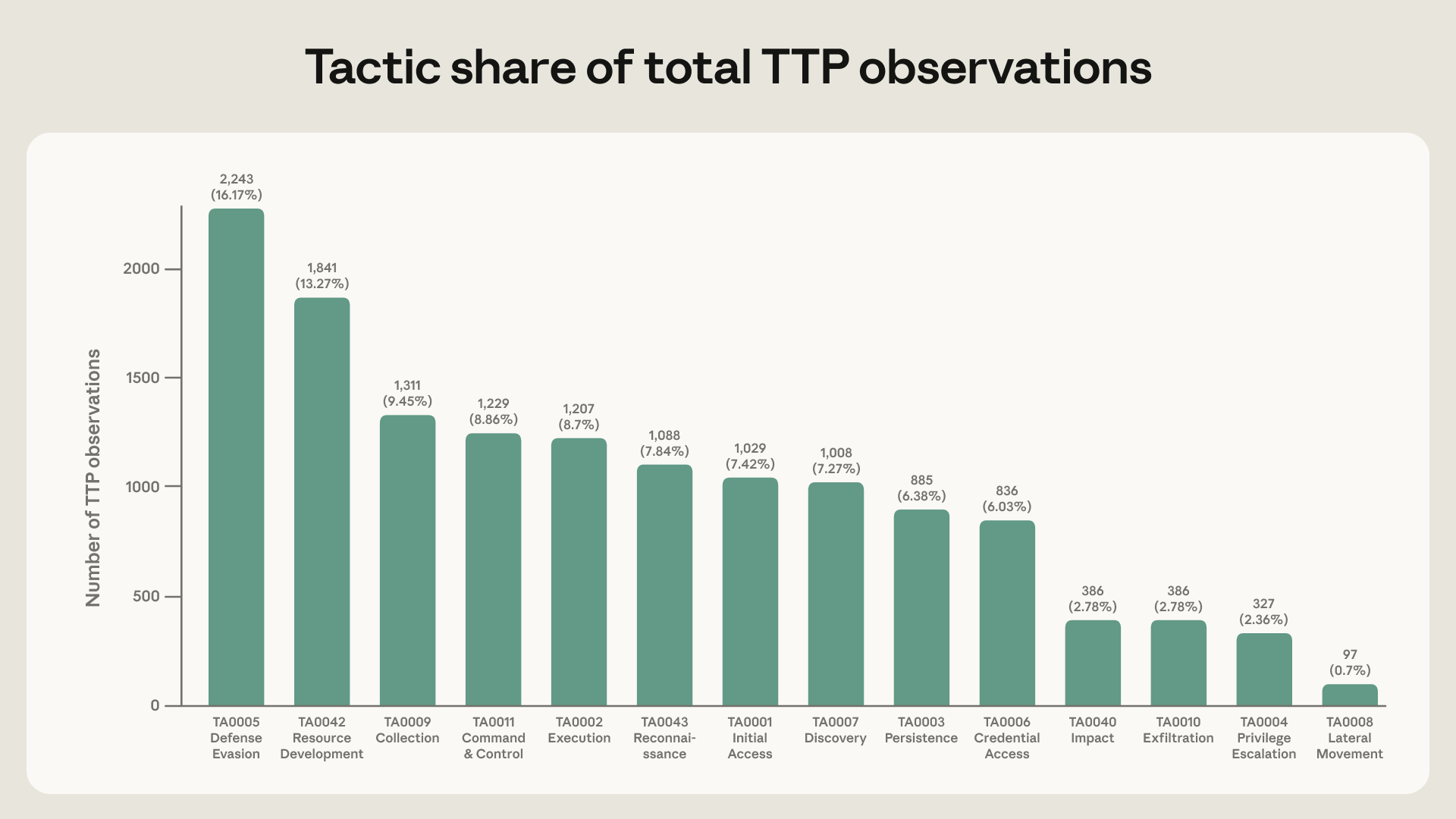
טקטיקות ששימשו פחות בתדירות כוללות השפעה (2.8%), הוצאת נתונים (2.8%), הרחבת הרשאות (2.4%) ותנועה רוחבית (0.7%). יחד, אלה מהוות רק 8.7% מכלל התצפיות – פחות מ"התחמקות מהגנה" לבדה. פעולות אלה מתרחשות כולן בשלבים מאוחרים יותר של מחזור חיי המתקפה, מה שמצביע על כך ששחקני איום משתמשים במודלים יותר בשלבים המוקדמים של מתקפה אך פחות בשלבים המאוחרים – כלומר, לאחר שחדרו לרשת ומתאימים את עצמם לתנאים בסביבה חיה. דפוס זה נשאר יציב במהלך תקופת השנה שבדקנו.
שחקנים בסיכון גבוה והטקטיקות שלהם
בעוד שטקטיקות כמו תנועה רוחבית נפוצות הרבה פחות במערך הנתונים שלנו, הן מתואמות מאוד עם ציוני הסיכון הגבוהים ביותר ב-ARiES – מה שאומר ששחקנים בסיכון הגבוה ביותר הם גם אלה הסבירים ביותר להשתמש במודלים לשלבים המאוחרים יותר של מתקפת סייבר. לשחקנים המשתמשים ב-AI לביצוע תנועה רוחבית יש ציוני סיכון שהם, בממוצע, 10.5 נקודות גבוהים יותר משחקנים שאינם משתמשים בכלי AI באופן זה. נתון זה מצביע על כך שהמעבר משימוש ב-AI להכנה למתקפת סייבר לשימוש בו לביצוע פעולות בפעילות רשת חיה הוא סמן מפתח לסיוע AI גבוה.
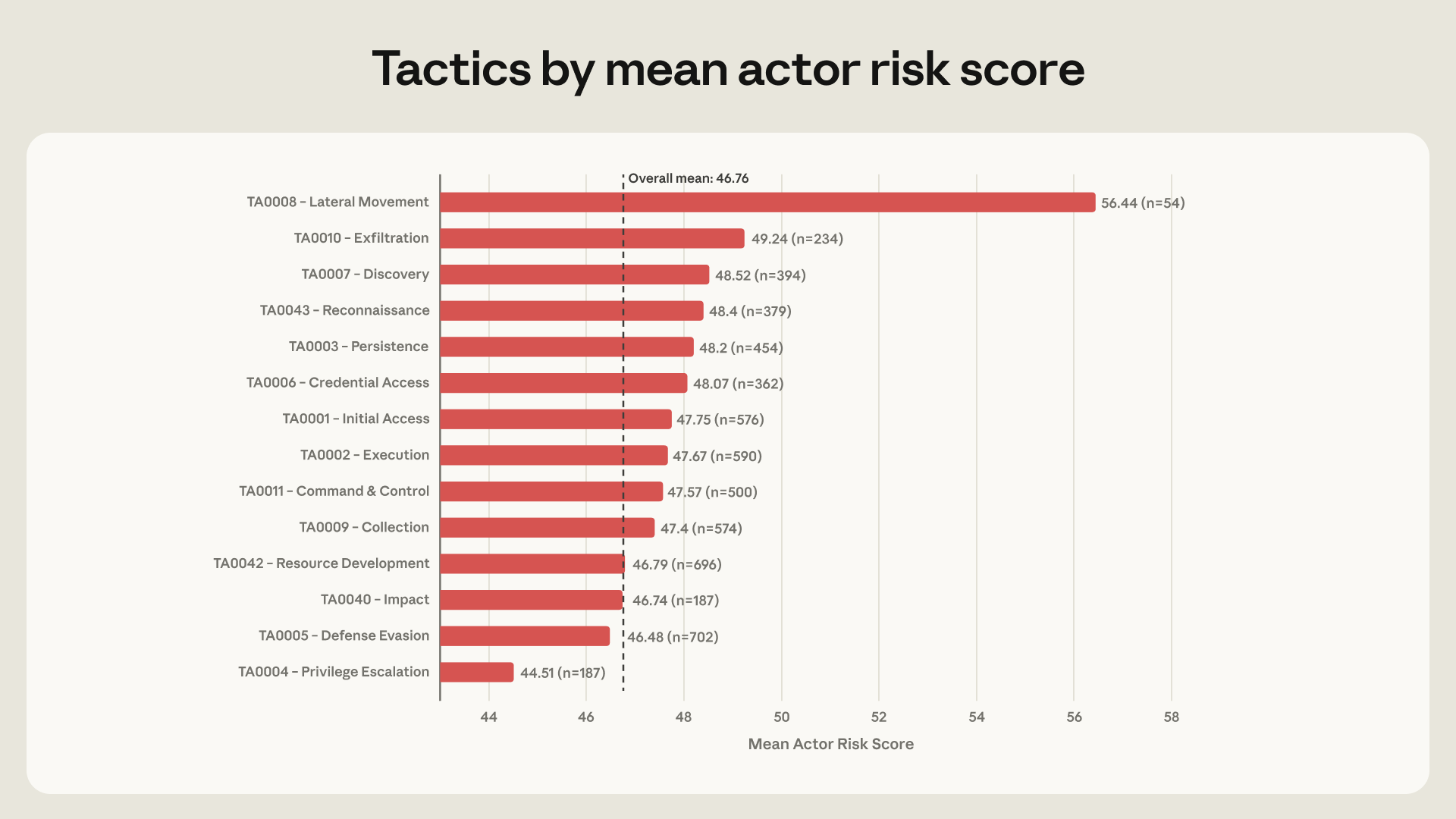
בסך הכל, השחקנים בעלי ציוני הסיכון הגבוהים ביותר השתמשו ב-AI באופן אינטנסיבי ביותר לטכניקות 'ידיים על המקלדת' לאחר פריצה, כגון שירותים מרוחקים, גניבת פרטי גישה, פריסת Web Shell וגילוי רשתות וחשבונות פנימיים. תנועה רוחבית הייתה הסמן החזק ביותר של שחקן בסיכון גבוה: ל-54 השחקנים במערך הנתונים שלנו שהשתמשו בתנועה רוחבית היה ציון סיכון ממוצע של 56.4, כמעט 10 נקודות מעל הממוצע של 46.8. אף טכניקה אחרת לא התקרבה לכוח חיזוי כזה.
ברמת הטכניקה, הטכניקות ששימשו לרוב על ידי השחקנים בסיכון הגבוה ביותר היו T1021 (שירותים מרוחקים: SSH/SMB), T1078.003 (חשבונות תקפים), T1003 (גניבת פרטי גישה למערכת הפעלה), T1560 (ארכיון נתונים שנאספו) ו-T1505.003 (Web Shell). כל אלה היו נפוצים פי שלושה עד חמישה יותר בקרב השחקנים בסיכון הגבוה ביותר בהשוואה לאוכלוסייה הכללית.
בינתיים, הטקטיקות הנפוצות ביותר (כמו התחמקות מהגנה ופיתוח משאבים) והטכניקות הכלליות (כמו Credential Stuffing ו-Spearphishing) שימשו בתדירות דומה על ידי השחקנים בעלי הסיכון הגבוה ביותר והנמוך ביותר, דבר שאינו מפתיע בהתחשב בכך שטקטיקות אלו נפוצות כל כך. יחד, הנתונים מצביעים על כך שרוב שחקני האיום משתמשים ב-AI לבניית Artifacts כמו קוד זדוני בשלבי ההכנה של מתקפה, אך השחקנים בסיכון הגבוה ביותר משתמשים במודלים הן בשלבי ההכנה של מתקפה והן במהלך העבודה המעשית בתוך רשת שנפרצה.
מצאנו גם שהתכונות שצוותי מודיעין איומים נוטים להישען עליהן כדי להעריך שחקני איום – כמו מיומנותם הטכנית המוערכת, בחירת הממשק שלהם או מספר הטכניקות שבהן השתמשו – הן מנבאים חלשים עד כמה שיפור יכולות מודל AI עשוי לספק לשחקן איום נתון. תחכום טכני, לאחר שהוצא מהציון המשולב כדי למנוע מעגליות, מתואם עם רכיבי הסיכון הנותרים ב-r = 0.28 בלבד. למעשה, הסרה מוחלטת של מאפיין זה משאירה את ששת השחקנים המובילים באותו סדר דירוג (Spearman ρ = 0.96 על פני כל 832 השחקנים). זנב הסיכון הגבוה אינו תוצר לוואי של רכיב התחכום הטכני.
המתאם בין רוחב כיסוי הטכניקות לציון הסיכון גם הוא חיובי חלש בלבד (r = 0.27). רוב השחקנים משתמשים במודלים למגוון קטן של טכניקות – למעשה, השחקן החציוני במערך הנתונים שלנו פרס 16 טכניקות MITRE ATT&CK נפרדות – רוחב שעד לפני חמש שנים, עשוי היה לסמן פעולה ממומנת היטב ובשלה טכנית.
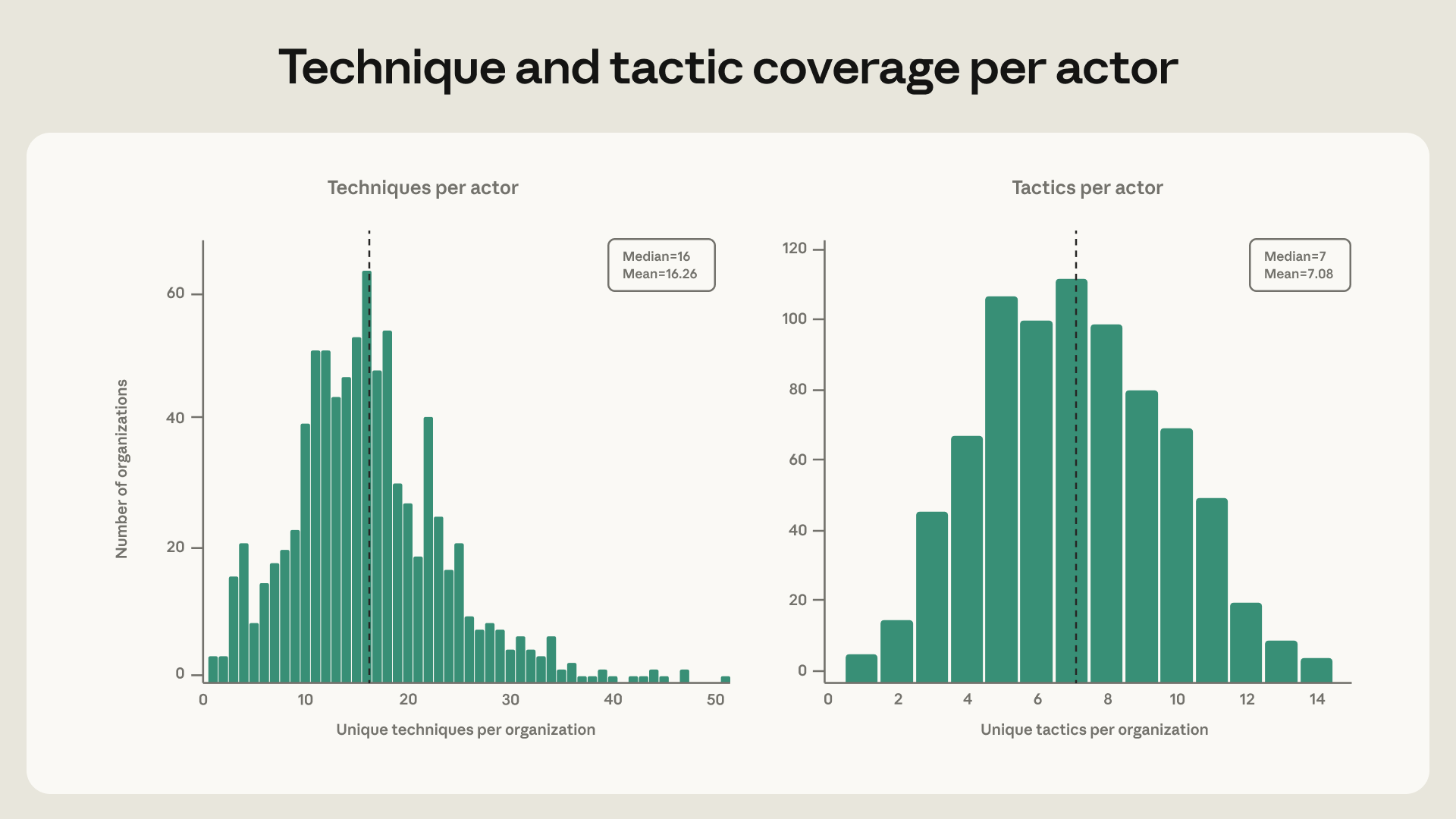
לבסוף, בחירת הממשק מספרת סיפור דומה – 80% מהשחקנים במחקר זה ניצלו לרעה את Claude Code, מה שהופך את כלי סוכני (agentic tooling) למצב הגישה ברירת המחדל במקום מצב מבדיל, ושחקנים שהוגבלו לממשק השיחתי, ל-API או לכלי קידוד סוכניים מתכנסים לפרופילי סיכון שאינם ניתנים להבדלה סטטיסטית.
מה שזה אומר לנו הוא שהשחקנים הזדוניים שמקבלים את הסיוע הרב ביותר מ-AI אינם בהכרח מתוחכמים יותר מבחינה טכנית משחקנים אחרים, והם גם לא בהכרח משתמשים בכלי קידוד או בקלוד על פני מספר שלבים בשרשרת ההרג; במקום זאת, הם פשוט השתמשו בקלוד עבור טכניקות מעשיות יותר.
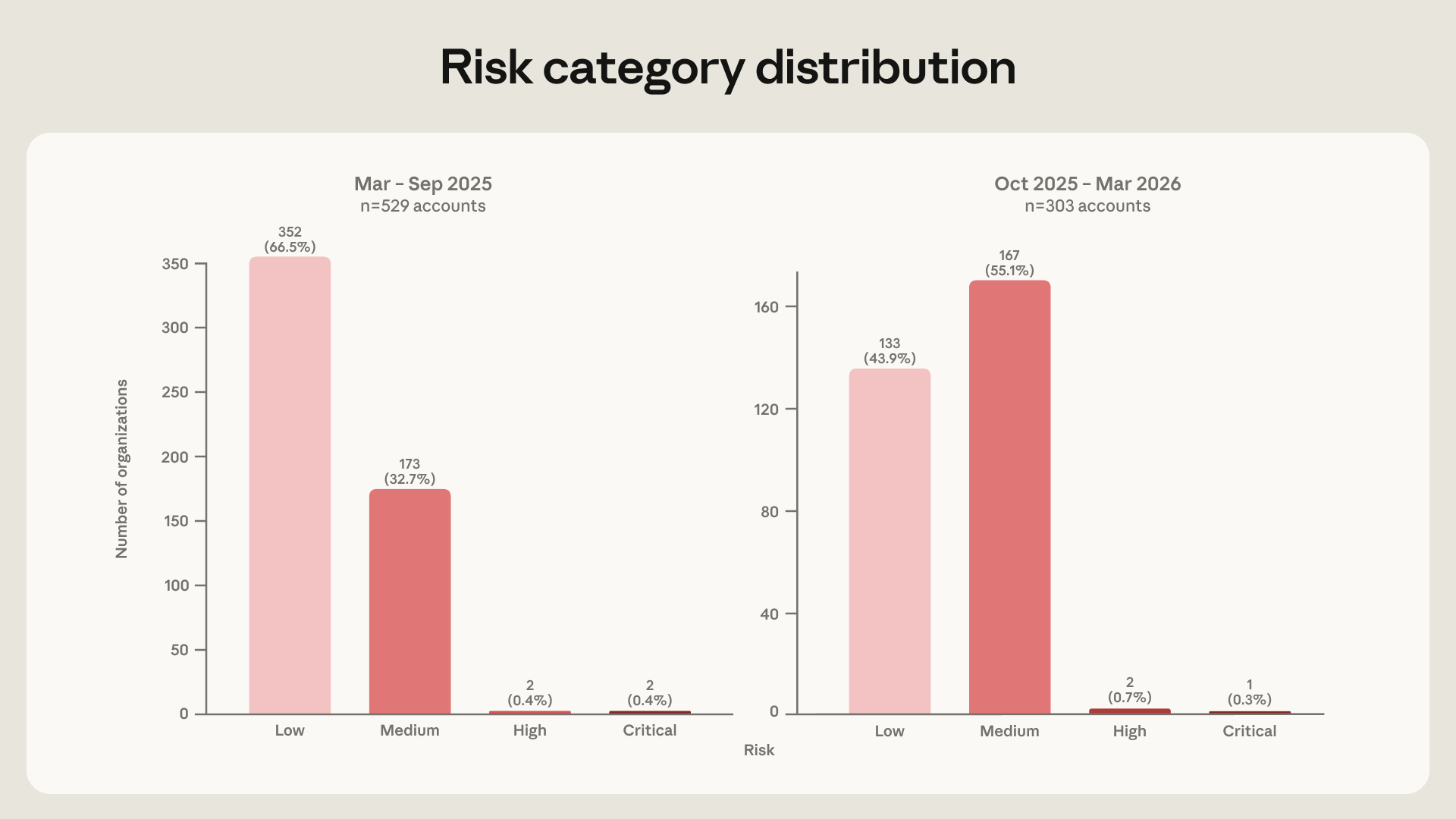
שחקני ניצול חיים בעלייה
כפי שדנו לעיל, חלקם של השחקנים שדורגו בסיכון בינוני ומעלה בסיוע AI גדל מכ-33.5% בתקופת ששת החודשים הראשונה של המחקר לכ-56.1% בשנייה – עלייה של פי 1.7 בפחות משנה. הקבוצה השתנתה בין שתי תקופות אלה בכ-22.6 נקודות אחוז: בעוד שרוב השחקנים היו בעלי ציון סיכון נמוך בתקופת ששת החודשים הראשונה, הרוב היו בעלי ציון סיכון בינוני בתקופת ששת החודשים השנייה.
בעוד שטכניקות זיהוי איומים משופרות עשויות להיות הסיבה לעלייה זו, אנו רואים גם מספר הולך וגדל של שחקנים המבקשים מהמודל עבודה תפעולית יותר, בתוך הרשת, שבעבר הופיעה רק בקבוצה קטנה בהרבה של שחקנים בסיכון גבוה. בתקופת ששת החודשים השנייה של המחקר, ראינו יותר שחקנים מתמחים המשתמשים במודלים לבניית כלי ניצול, תשתית C2 וסוסים טרויאנים לגישה מרחוק – אך ראינו גם יותר שחקנים בעלי מיומנות נמוכה ובינונית המשתמשים במודלים לא רק למשימות הכנה אלא גם לפעולות חיות. העלייה של 8.9% ב-T1087 (גילוי חשבונות) ועלייה של 6.2% ב-T1020 (הוצאת נתונים אוטומטית) שצפינו מהתקופה הראשונה לשנייה עולות בקנה אחד עם זה: הטכניקות שהופכות נפוצות יותר הן אלה המרמזות כי השחקן כבר ניגש לרשת.
משמעות הדבר עבור המגנים: אוכלוסיית השחקנים מבוססי ה-AI לא רק גדלה אלא גם נסחפת לעבר הפעילויות המסוכנות ביותר במסגרת שלנו, מבלי לדרוש מהשחקנים עצמם להפוך למיומנים יותר. אם מגמה זו תימשך, טכניקות מבצעיות אלו כבר לא יהיו גורם מבדיל ויהפכו לבסיס מחר – ונצטרך למצוא דרך חדשה למדוד את השחקנים המסוכנים ביותר. בסעיף הבא נדון כיצד נוכל לעשות זאת בהמשך.
חדשנות ותחכום בעידן סוכני AI
התבוננות בשחקני האיום בעלי הסיכון הגבוה ביותר שלנו גם מדגישה כי חישוב הסיכון של פעולות סייבר מבוססות AI על בסיס מספר, סוג או רוחב טכניקות התקיפה אינו מספק. אנו זקוקים גם לדרך להבין את הפיגומים ששחקני איום מסוגלים לבנות כדי לקשור טכניקות אלו יחד לשימוש בפעולות חיות, מה שמאפשר להם להשתמש במודלי AI כדי לבצע באופן אוטונומי נתחים גדולים של מתקפת סייבר ללא התערבות אנושית.
ניתחנו את התנהגותו של שחקן האיום שתזמר את קמפיין ריגול הסייבר מבוסס ה-AI שדיווחנו עליו בנובמבר 2025, שכותרתו GTG-1002. אנו רואים ששחקן זה השיג את ציון הסיכון המקסימלי האפשרי של 100, פגע בהצלחה במטרות ממשלתיות ובתשתיות קריטיות במספר מדינות, ופיתח פיגומים לשימוש ב-Claude Code לא כיועץ, אלא כמפעיל אוטונומי. עם זאת, פרופיל ה-MITRE הכולל שלהם – 30 טכניקות על פני 13 טקטיקות – דומה לעשרות שחקנים בסיכון בינוני במערך נתונים זה. השחקן החציוני מפעיל 16 טכניקות; מספר שחקנים בסיכון נמוך אף עולים על 30. במילים אחרות, ספירת טכניקות או סוג טקטיקה לבדם לא יכלו להסביר מה הפך את GTG-1002 לשחקן בעל הסיכון הגבוה ביותר שצפינו בו עד כה.
מה כן מסביר את ציון הסיכון הגבוה של שחקן זה הם הרכיבים הסוכנייים (agentic) ההולכים וגדלים שבהם השתמש: כיצד הוא הצליח לתזמר ולקשור יחד טכניקות כדי לפעול למען יעדיו. GTG-1002 השתמש ב-Claude Code שרץ על מכונת Kali Linux, ואינטגרציה של כלי בדיקות חדירה בקוד פתוח כשרתי MCP (Model Context Protocol) – למעשה, הפך את ה-AI לפלטפורמת תקיפה אוטונומית במקום לעוזר לכתיבת קוד. ה-AI לא רק הציע פקודות או יצר סקריפטים להתקפה; הוא ביצע אותם והסיק באופן אוטונומי לגבי סביבות התקיפה. כמה אינדיקציות ל"סוכנות" שלהם מופיעות בייפוי כוח דרך סוגי הטכניקות שאנו עוקבים אחריהם; GTG-1002 השתמש בטכניקות מבצעיות כגון T1021.004 (שירותים מרוחקים: SSH), T1210 (ניצול שירותים מרוחקים) ו-T1560 (ארכיון נתונים שנאספו). אך הגורמים המבדילים העיקריים היו:
- ביצוע אוטונומי בתוך שלבים: GTG-1002 פרס את Claude Code שרץ על מכונת Kali כדי לתזמר עשרות פעולות כלי MCP באופן אוטונומי – סריקה ומיפוי של עשרות שירותים חשופים לאינטרנט במהלך איסוף מודיעין, ולאחר מכן גילוי פורטלי ניהול פנימיים, מסדי נתונים, שרתי לוגים ומערכות זרימת עבודה זמניות לאחר החדירה לרשת. ה-AI לא רק הציע פקודות; הוא ביצע אותן, תוך קבלת החלטות טקטיות לגבי מה לחקור הלאה מבלי להמתין לקלט מהמפעיל.
- ניצול בזמן אמת וציר תנועה (pivoting): הפועל בתוך הפיגומים של GTG-1002, ה-AI ניצל פגיעות SSRF בשרת ווב חשוף לציבור כדי להעביר פקודות ב-proxy לסביבת הענן הפנימית, אסף מפתחות פרטיים של SSH מתשתית פנימית ואסימוני חשבונות שירות משירותי מטא-דאטה בענן ו-AWS Secrets Manager, והשתמש בפרטי גישה שנאספו אלה כדי לנוע רוחבית בסביבת הענן של הקורבן. אלו הם השלבים המבצעיים (גילוי ← גישת פרטי גישה ← תנועה רוחבית) שהיו נדירים יותר במערך הנתונים שלנו.
- כוונה אנושית, ביצוע AI: GTG-1002 סיפק כיוון אסטרטגי בעוד ה-AI טיפל ביישום הטקטי. ה-AI פעל באופן אוטונומי במהלך איסוף המודיעין והגילוי הפנימי, התאים את גישתו כאשר נתקל בתשתית בלתי צפויה כמו תהליכי חתימה של תמונות קונטיינרים וזהויות חשבונות שירות, והכין ודחס עשרות אלפי רשומות זרימת עבודה קנייניות ותיעוד ארכיטקטורה פנימי להוצאת נתונים. חילוץ הנתונים הסופי – הורדה למחשב התוקף באמצעות קריאות כלי MCP מסוג curl – היה מונחה אנושית, מה שמצביע על כך שהמפעיל שמר על שליטה בהחלטות בעלות ההשלכות תוך האצלת העבודה המבצעית ל-AI.
פעילותו של GTG-1002 הייתה חדשנית בזכות השימוש בסוכן AI כדי לקשור יחד באופן אוטונומי שלבים רבים במחזור חיי מתקפת הסייבר – איסוף מודיעין, ניצול, תנועה רוחבית והוצאת נתונים – לפעולה קוהרנטית, תוך קבלת החלטות בזמן אמת לגבי מה לעשות ואיזה נתונים לאסוף. זהו הממד של סיוע AI שבו טבלת תדירות טכניקות אינה יכולה ללכוד, וזהו הממד שאנו מצפים שיהיה החשוב ביותר ככל שכלי סוכנים יתבגרו.
כיצד אנו משתמשים ב-Navigator כדי ליידע את אמצעי ההגנה שלנו
הממצאים בדוח זה עיצבו את האופן שבו אנו מזהים, חוקרים ומשבשים שימוש לרעה בסייבר המופעל באמצעות AI.
ראשית, ציוני הסיכון שלנו מראים שהשחקנים בסיכון הגבוה ביותר אינם תמיד הקולניים או הפוריים ביותר – לעיתים קרובות הם נראים רגילים מבחינת סוג ונפח הטכניקות שבהן הם משתמשים, ובמקום זאת נבדלים על ידי האופן שבו הם מתזמרים את ה-AI שלהם לביצוע פעולת סייבר שלמה. אנו מעדכנים את מערכות הזיהוי שלנו בהתאם, ומרחיבים את המסווגים והבוחנים שלנו כדי לתפוס טכניקות המתואמות עם ציוני ARiES גבוהים. אנו מפתחים גם אותות זיהוי לדפוסי שימוש לרעה סוכניים שאינם ממופים באופן ברור ל-MITRE, כגון ביצוע אוטונומי מרובה שלבים, החלטות ציר תנועה המונחות על ידי AI, ופעולות משופרות-כלים באמצעות שרתי MCP וממשקים דומים.
שנית, פרסנו מנגנוני הגנה סייבריים בזמן אמת במודלים היעילים ביותר שלנו, המזהים וחוסמים אוטומטית פעילות אסורה (כגון פיתוח כופרות או הוצאת נתונים המונית) ברמת הבקשה. אנו גם מנתבים כעת פעילויות דו-שימושיות בעלות סיכון גבוה – כאלה שתוקפי סייבר ומגנים כאחד עשויים לבצע – דרך תוכנית אימות הסייבר (CVP) שלנו, המאפשרת למומחי הגנה להמשיך להשתמש במודלים שלנו בעבודתם.
שלישית, באמצעות פרויקט Glasswing, אנו חוקרים את יכולות הסייבר ההתקפיות של המודל היעיל ביותר שלנו לפני הפיכתו לזמין לציבור הרחב, כדי שנבין לאן מועדות פני יכולות הסייבר של AI לפני ששחקני איום יוכלו לנצל אותן, ונוכל לתכנן אמצעי הגנה לפני שיתרחש שימוש לרעה כזה.
לבסוף, בעקבות שיתוף הפעולה שלנו עם ורייזון על דו"ח Verizon Data Breach Investigation Report 2026, אנו נמצאים כעת בשיחות פעילות עם MITRE לגבי האופן שבו מסגרת ATT&CK יכולה להתפתח כדי ללכוד את ההתנהגויות המבצעיות ילידות-AI שצפינו בניתוח זה. אנו ממשיכים גם לשתף אינדיקטורים טכניים; טקטיקות, טכניקות ופרוצדורות שבהן משתמשים שחקני איום; וממצאי חקירה עם השותפים שלנו בממשלה ובתעשייה באופן שוטף.
עידן חדש עבור MITRE ATT&CK
השחקנים המסוכנים ביותר משתמשים כעת ב-AI כדי לתזמר מתקפות במקום רק לבנות כלים המאפשרים מתקפות כאלה, והמסגרת שחוקרי איומים משתמשים בה כדי לעקוב אחר איומים עדיין לא השלימה את הפער. מסגרות מסורתיות המבוססות על כך ששחקנים מתוחכמים טכנית ייכשלו כאשר שחקנים בעלי מיומנות נמוכה יוכלו לבנות, לפקד ולהפעיל כלים ברמת מומחה.
לקח אחד ברור משנה שלמה של מיפוי פעילות זו, כמו גם עבודתנו עם ורייזון, הוא שעלינו להרחיב את אוצר המילים המשותף שלנו בתחום האיומים. ה-MITRE ATT&CK לוכד את הטכניקות הבודדות ששחקנים מבצעים, אך ההתנהגויות המבדילות את השחקנים בעלי הסיכון הגבוה ביותר מאחרים – דברים כמו תזמור סוכני (agentic orchestration) של שרשרת הרג שלמה, או בחירה אוטונומית של יעדים – אינן נלכדות עדיין בטקסונומיה זו.
אנו מאמינים שהצעד הבא הוא הוספת קטגוריות רוחביות חדשות למסגרת ATT&CK שיסייעו לחוקרי איומים לזהות את ההתנהגויות הסוכנייות, האוטונומיות ומבוססות קבלת ההחלטות, הקושרות יחד טכניקות מרובות. זה ייתן למגנים אוצר מילים שיעמוד בקצב שבו יריבים משתמשים בכלי AI בפועל.
במקביל, ברור שהמגנים יצטרכו להשתמש ב-AI באותו תחכום ודחיפות כמו התוקפים, לשתף מודיעין איומים בין ארגונים ולקצר את זמן זיהוי פגיעות תוכנה ועד לתיקונה. כתעשייה, עלינו להיות סובלניים הרבה פחות לקוד לא מאובטח. תקופת המעבר תהיה קשה. אך, אם התעשייה, הממשלה והחברה האזרחית יתייחסו לרגע הנוכחי בדחיפות הראויה, אנו מאמינים שמערכות AI בעלות יכולות יועילו למגנים יותר מאשר לתוקפים בטווח הארוך: מציאת באגים לפני שקוד חדש נשלח, והפיכת המערכות שבהן החברות תלויות למאובטחות יותר. התוצאה יכולה להיות תשתית מוגנת טוב יותר, וסביבה דיגיטלית עם פחות הונאה וניצול לרעה באופן מהותי. נמשיך לפרסם את מה שלמדנו ככל שנוף האיומים מתפתח.
הערות שוליים
[1] עבור ה-DBIR, סיפקנו ניתוח של 11 חודשי נתונים של שחקני איום, והרחבנו זאת ל-12 חודשים עבור דוח זה.
[2] אנו צופים בתתי-טכניקות ממטריצות הטכניקות Enterprise ו-Mobile מבית MITRE. טכניקות Enterprise מהוות 99% מהתצפיות.