פריסה מחודשת של Fable 5
ביום שישי, 12 ביוני, ממשלת ארה"ב הטילה בקרות ייצוא על המודלים החדשים ביותר שלנו, Claude Fable 5 ו-Claude Mythos 5. צעד זה חייב אותנו להגביל את הגישה לאזרחים זרים, בין אם בתוך ארה"ב ובין אם מחוצה לה. מכיוון שהצו נכנס לתוקף מיידי ולא הייתה לנו דרך אמינה לוודא אזרחות בזמן אמת, השעינו את הגישה לשני המודלים לכלל המשתמשים.
החל מהיום, 30 ביוני, בקרות הייצוא על Fable 5 ו-Mythos 5 הוסרו.
Fable 5 יהיה זמין החל ממחר, יום רביעי, 1 ביולי, למשתמשים ברחבי העולם בפלטפורמת Claude, ב-Claude.ai, ב-Claude Code וב-Claude Cowork. עבור תוכניות Pro, Max, Team ותוכניות Enterprise נבחרות, Fable 5 ייכלל עד 50% ממגבלות השימוש השבועיות עד ה-7 ביולי, ולאחר מכן יהיה זמין באמצעות קרדיטים לשימוש. נאפשר מחדש גישה ב-AWS, Google Cloud ו-Microsoft Foundry בהקדם האפשרי.
שחזרנו גם את הגישה ל-Mythos 5 עבור קבוצת ארגונים בארה"ב, בעקבות אישור ממשלת ארה"ב ב-26 ביוני. אנו ממשיכים לתאם עם הממשלה כדי להרחיב את הגישה למערך הרחב יותר של שותפים מקומיים ובינלאומיים בתוכנית Glasswing.
במהלך הפוסט הזה, אנו מספקים פרטים ועדכונים נוספים בארבעה תחומים:
- ציר זמן של אירועים, כולל עדכונים שביצענו למנגנוני ההגנה שלנו. נדון באירועים שהובילו להנחיית בקרת הייצוא וכיצד טיפלנו בה באמצעות מנגנוני הגנה חדשים.
- הגישה הכללית שלנו למנגנוני הגנה. נספק הקשר נוסף על האופן שבו אנו משתמשים במקטלגי בטיחות כדי לזהות שימושים פוטנציאליים מסוכנים של מודלים שלנו בתחום אבטחת הסייבר.
- מסגרת תעשייתית משותפת. למרות שהגענו לפתרון בונה, אירועים אלה הבהירו שהתעשייה זקוקה לדרך עקבית להעריך ולתקן "פריצות מגבלות" פוטנציאליות במודלי AI (טכניקות העוקפות את מנגנוני ההגנה של מודל). תקן משותף לשיפוט חומרת פריצת מגבלות נתונה יסייע למפתחי AI לתעדף ממצאים חדשים כשהם עולים, להשיק מודלים בעלי יכולות גבוהות עם בטיחות רבה יותר, ולתקשר את רמת הסיכון באופן עקבי לשותפי ממשלה ותעשייה. יחד עם Amazon, Microsoft, Google ושותפים נוספים ב-Glasswing, התחלנו לפתח מסגרת כזו, ואנו מציגים אותה להלן.
- שיתוף פעולה עמוק יותר עם הממשלה. אנו מחזקים גם את רמת שיתוף הפעולה שלנו עם ממשלת ארה"ב בנושאי בדיקות טרום-שחרור חדשות, שיתוף מידע ושיתוף פעולה מחקרי. נתאר שיתוף פעולה עמוק זה בחלק האחרון.
ציר זמן ועדכוני מנגנוני הגנה
השקנו את Fable 5 ו-Mythos 5 ביום שלישי, 9 ביוני. שניהם חולקים את אותו מודל בסיסי, אך Fable 5 שוחרר עם מנגנוני הגנה חזקים כדי להפוך אותו לבטוח יותר לשימוש כללי. Mythos 5, שלו פחות מנגנוני הגנה, שוחרר רק למספר קטן של שותפים מהימנים ב-Project Glasswing לשימוש באבטחת סייבר הגנתית.
הנחיית בקרת הייצוא ב-12 ביוני הגיעה לאחר שהממשלה נודעה על דיווח שבו חוקרי Amazon מצאו שיטה לעקוף את מנגנוני ההגנה של Fable 5: באמצעות פרומפטים שגרמו לו לזהות מספר נקודות תורפה בתוכנה. במקרה אחד, המודל הפיק קוד שהדגים כיצד ניתן לנצל את נקודת התורפה הרלוונטית. במהלך השבועיים האחרונים, עבדנו בשיתוף פעולה הדוק עם הממשלה ושותפים נוספים, כולל Amazon, כדי לבחון את הדיווח והראיות.
הבדיקות שלנו אישרו כי מודלים רבים פחות חזקים – כולל Claude Opus 4.8, GPT-5.5 ו-Kimi K2.7 – יכלו לזהות את אותן נקודות תורפה ש-Fable 5 זיהה בדיווח. באשר להדגמה כיצד לנצל את נקודת התורפה היחידה, כל מודל שבדקנו יכול היה להפיק את אותה הדגמה כמו Fable 5 (כולל Claude Haiku 4.5, Sonnet 4.6, Opus 4.6, Opus 4.7, Opus 4.8, GPT-5.4, GPT-5.5 ו-Kimi K2.7).
חשוב לציין, הטכניקה שדווחה לא חשפה יכולות סייבר התקפיות ייחודיות ברמת Mythos. ההתנהגות שיקפה מקרה גבולי עבור מנגנוני ההגנה של Fable 5 – כפי שנסביר להלן, ישנן משימות מסוימות שאינן צפויות להיות מסוכנות אך למרות זאת נחסמות על ידי מנגנוני ההגנה מתוך זהירות יתרה. הטכניקה שדווחה אפשרה גישה להתנהגות כזו, אך היא כללה רק עבודת אבטחת סייבר הגנתית שגרתית.
למרות זאת, פעלנו במהירות לטפל בפריצת המגבלות שדווחה. בשיתוף פעולה הדוק עם הממשלה, אימנו מקטלג בטיחות משופר שמטרתו לחסום את ההתנהגות המתוארת בדיווח. משתמשים יקבלו הודעה אם בקשה ל-Fable 5 נחסמת, והבקשה תישלח במקום זאת ל-Opus 4.8.
המקטלג החדש אומר שהטכניקה הספציפית המתוארת בדיווח של Amazon נחסמת ביותר מ-99% מהמקרים. באחוז קטן מאוד מהמקרים המודל עשוי לספק מידע שאינו מפורט מספיק כדי לסייע לתוקף סייבר. כפי שנתאר להלן, מנגנוני ההגנה של המודל אינם צפויים לחסום את כל יכולות הגנת הסייבר השגרתיות בסיכון נמוך – רק אלה שעלולות להיות מזיקות. חוקרים מ-המרכז לסטנדרטים וחדשנות ב-AI (CAISI) של משרד המסחר האמריקאי בדקו הן את מנגנוני ההגנה הקודמים והן את החדשים שלנו ומסכימים שהם חזקים בצורה יוצאת דופן.
המקטלג החדש מגיע גם במחיר של סימון בקשות תמימות לעיתים קרובות יותר במהלך משימות קידוד ודיבוג שגרתיות. כמו בכל מנגנוני ההגנה שלנו, נמשיך לחדד זאת כדי להבחין טוב יותר בין שימוש לרעה אמיתי לבקשות לגיטימיות ולהפחית התרעות שווא.
הגישה שלנו למנגנוני הגנה בתחום אבטחת הסייבר
Claude Mythos 5 יכול לשמש למציאת וניצול נקודות תורפה בתוכנה בצורה יעילה יותר מכל מודל אחר – ומכל מומחי אבטחה אנושיים, למעט המיומנים ביותר. יכולות אבטחת סייבר אדירות אלו הופכות אותו לאטרקטיבי במיוחד עבור גורמים זדוניים המעוניינים לנצל אותו לרעה בהתקפות סייבר.
Claude Fable 5, לעומת זאת, אינו מספק יכולות התקפיות ייחודיות כאלה. זאת מכיוון שהשקנו אותו עם מנגנוני ההגנה החזקים ביותר שאי פעם יישמנו על מודל. בחודש שלפני ההשקה, העברנו צוותים שונים בתוך אנתרופיק כדי להכפיל את מספר החוקרים והמהנדסים שעבדו על בעיה זו.
Fable 5 הושק עם מגוון מנגנוני בטיחות, שכל אחד מהם לבדו אינו מספק הגנה מושלמת, אך בשילוב הופכים את המודל לקשה מאוד לשימוש לרעה (גישה הידועה כ"הגנה רב-שכבתית" - defense in depth). חלק מההגנות כרוכות באימון המודל לסרב לסייע בבקשות מסוכנות; אחרות כרוכות בניתוח רטרואקטיבי של דפוסי שימוש לרעה.
מנגנון בטיחות חשוב במיוחד כולל מקטלגים – מערכות AI אוטומטיות קטנות יותר, שבמהלך אינטראקציה מזהות מתי המודל מתבקש לבצע משימת אבטחת סייבר שעלולה להיות מזיקה (או מפיק תפוקות שעלולות להיות מזיקות). כאשר זה קורה, המקטלגים חוסמים את המודל מלהגיב לבקשות. המטרה הסופית של מקטלגים אלה היא למנוע מהמודל לעסוק בהתנהגויות מסוכנות באופן ייחודי.
כמו כל מנגנוני הבטיחות, גם מקטלגים יכולים לטעות. לעיתים הם מפספסים תוכן שעלול להיות מסוכן, ובמקרים מסוימים ניתן לבצע בהם בכוונה "פריצת מגבלות": משתמשים יכולים לפרומפט את המודל בדרכים יוצאות דופן כדי לרמות את המקטלגים ולגרום למודל להפיק תפוקות מזיקות שהמערכת הייתה אמורה לחסום.
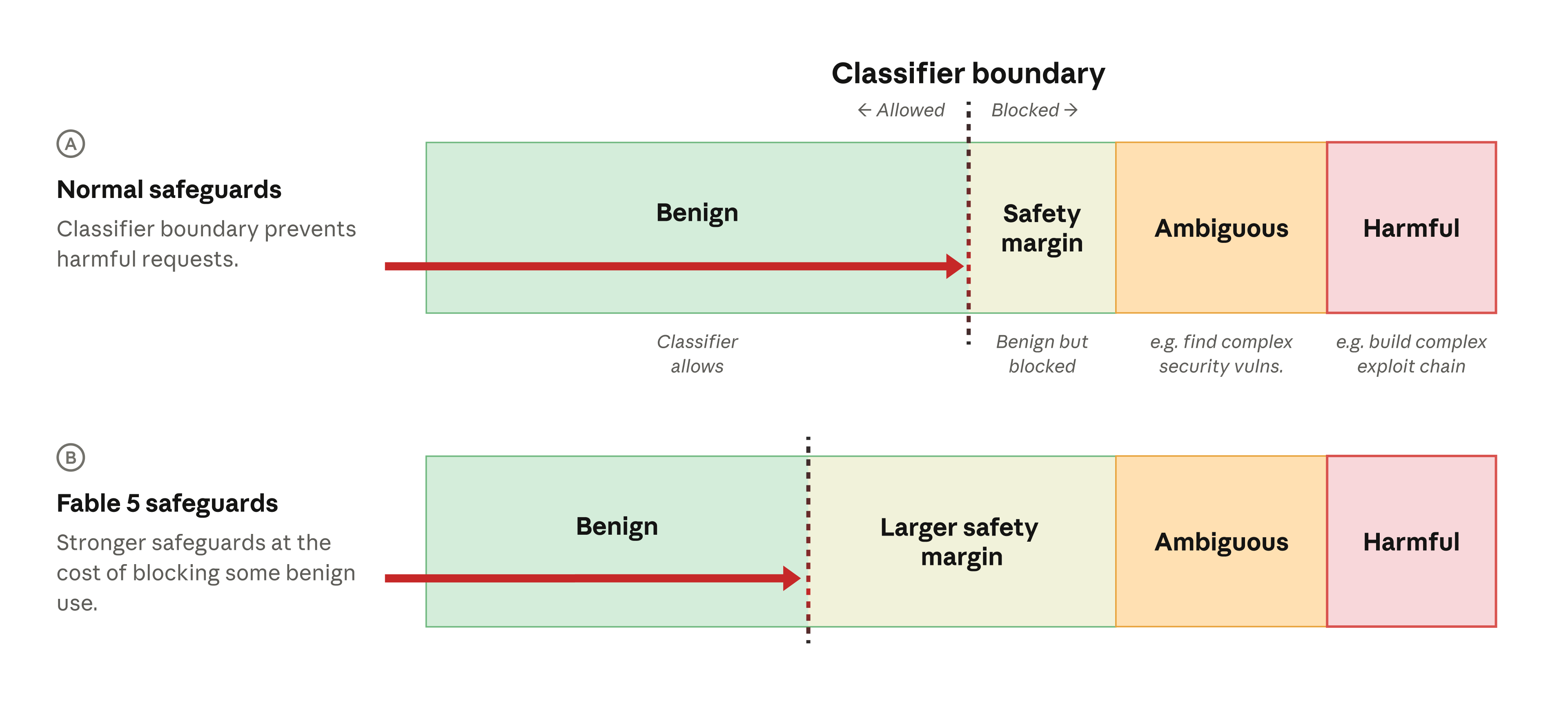
לכן, קבענו במכוון את מקטלגי הבטיחות כך שיפעלו על סט בקשות שאנו יודעים שהן ככל הנראה תמימות. גישת "מרווח הבטיחות" הזו אומרת שבקשה צריכה להיראות בטוחה באופן ברור מאוד כדי להימנע מהפעלת המקטלג (ראו שורה A בתרשים למטה). משתמשים חווים את מרווח הבטיחות כמודל המסרב להגיב לבקשות סבירות ובלתי מזיקות מסוימות.
עבור Fable 5, הגדלנו את מרווח הבטיחות הזה משמעותית יותר מכל השקה קודמת (שורה B), מה שאומר שהרבה יותר בקשות תמימות ייחסמו. הבנו שסוגים אלה של התרעות שווא יהיו מתסכלים עבור משתמשים, אך ביצענו את הפשרה הזו למען הנגשת שאר יכולות המודל באופן נרחב.
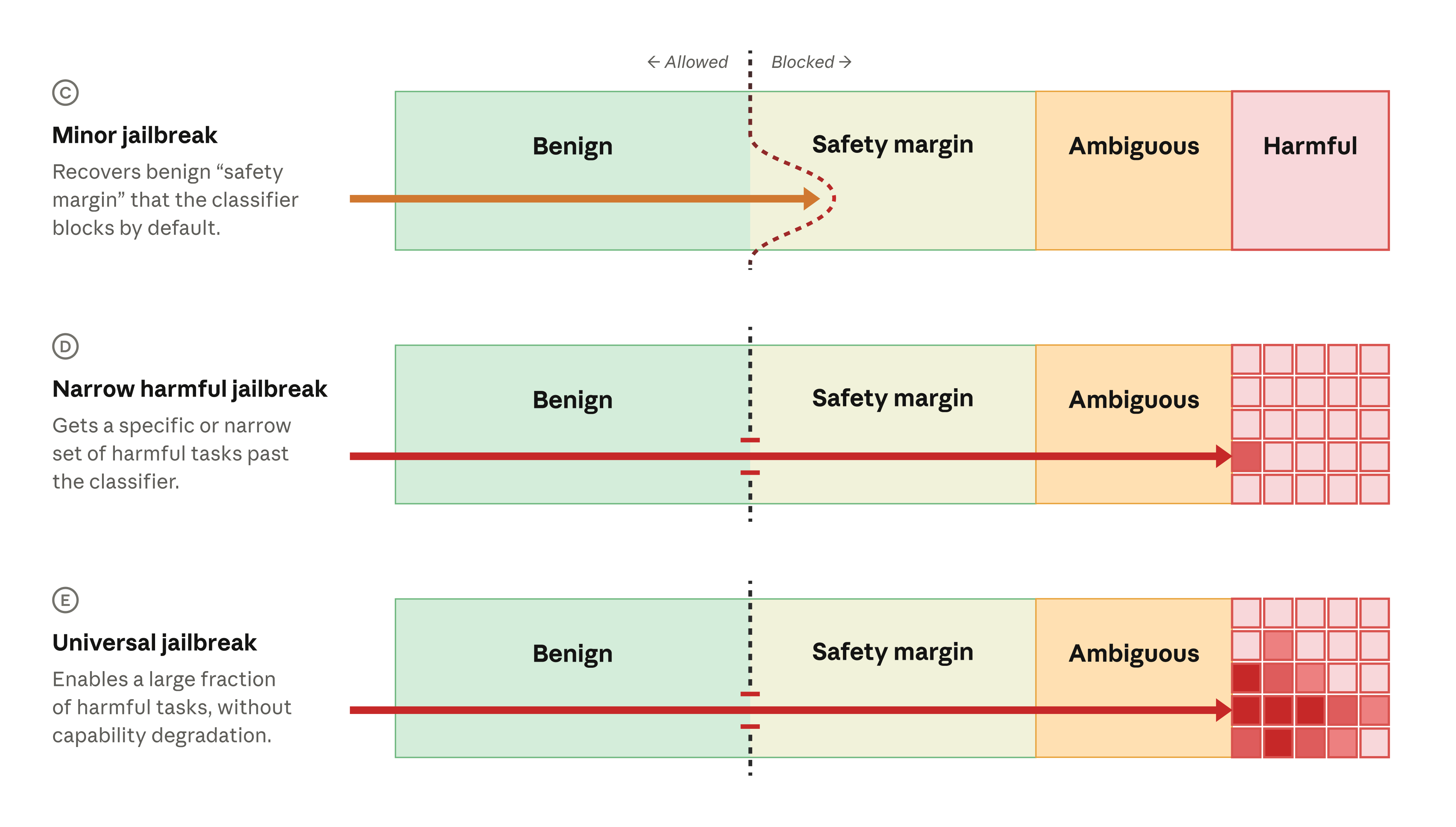
מרווח הבטיחות גם מסייע להפחית פריצות מגבלות. רבות מפריצות המגבלות הן צרות: הן מסירות חסימה מהתנהגות מודל מאוד ספציפית אך לא יותר. במקרים מסוימים, משתמש היפותטי יכול לבצע פריצת מגבלות קלה ולחדור למרווח הבטיחות (או לעיתים להתנהגות מזיקה באופן מעורפל), אך לא להתנהגויות המזיקות הליבתיות שאנו שואפים לחסום (שורה C למטה). תפיסתנו היא שפריצות המגבלות של Fable 5 שדווחו עד כה מתאימות לקטגוריה קלה זו.
פריצות מגבלות חמורות יותר מסירות חסימה מהתנהגויות מזיקות יותר. פריצות מגבלות מזיקות צרות (שורה D) יכולות לעורר התנהגויות מזיקות ספציפיות. פריצות מגבלות אלו הן בדרך כלל בעלות חומרה נמוכה עד בינונית, מכיוון שצרותן מגבילה את התוקף. הקטגוריה המדאיגה ביותר היא פריצת מגבלות אוניברסלית (שורה E), המסירה חסימה ממגוון רחב של התנהגויות מזיקות.
כפי שציינו כאשר השקנו את Fable 5, ככל הנראה בלתי אפשרי להפוך מודל AI כלשהו לעמיד לחלוטין בפני פריצות מגבלות. אנו מצפים שיימצאו פריצות מגבלות למודלים שלנו, וכי חומרתן תשתנה: יהיו פריצות מגבלות קלות רבות, כמה מזיקות צרות, ולמרות שלא התגלו פריצות מגבלות אוניברסליות עבור Fable 5 בזמן כתיבת שורות אלה, חוקרי בטיחות מומחים ממשיכים לבצע לו Red Teaming. אנו שואפים להבטיח שאנו ושותפי הבטיחות שלנו נהיה הראשונים לגלות פריצות מגבלות משמעותיות ולתקן אותן לפני שגורמים זדוניים יוכלו להשתמש בהן לרעה.
הגישה הזהירה המתוארת לעיל אומרת שהרוב המכריע של פריצות המגבלות לא יסירו חסימה בהצלחה מהתנהגויות מסוכנות. המקטלגים שלנו הופכים פריצות מגבלות מוצלחות ליקרות מאוד ודורשות מאמץ רב כדי להפיק, ואפילו אם פריצת מגבלות מצליחה, שכבות ההגנה הנוספות שלנו מספקות הפחתה נוספת. אנו נמשיך לעדכן את המקטלגים שלנו ככל שנלמד יותר על טכניקות חדשניות לפריצת מגבלות.
מסגרת תעשייתית מוסכמת לפריצות מגבלות
נכון להיום, אין הסכמה בתעשיית ה-AI כיצד לתאר, במונחים אובייקטיביים, את חומרתה של פריצת מגבלות AI. מצב זה מוסיף אי-ודאות רבה בכל פעם שמתגלה טכניקה חדשה לפריצת מגבלות: למפתחים אין תקן מוסכם על אילו ממצאים להתמקד בדחיפות הרבה ביותר, ולממשלות אין תקן מוסכם לגבי מתי לפעול.
בעיה זו תהפוך חריפה יותר בחודשים הקרובים, ככל שיאומנו, יוערכו ויושקו מודלים נוספים עם יכולות אבטחת סייבר (ואחרות) עוצמתיות. תקן משותף להערכת פריצות מגבלות AI יסייע לנו ולחברות אחרות להשיק מודלים חדשים בבטחה, כמו גם לאפשר למשתמשים שלנו להפיק את המרב מיכולותיהם המתקדמות.
לכן, אנו משתפים פעולה עם Amazon, Microsoft, Google ושותפים נוספים ב-Glasswing כדי לנסח מסגרת מוסכמת להערכת חומרת פריצות מגבלות AI וכיצד מפתחי AI צריכים להגיב אליהן. אנו מזמינים שותפים תעשייתיים וספקי מודלים נוספים להצטרף אלינו למאמץ זה.
ההצעה הנוכחית שלנו היא לדרג פריצת מגבלות נתונה לפי ארבעה קריטריונים שונים שלהלן. שני הראשונים מתארים מה פריצת המגבלות מספקת לתוקף; שני האחרונים מתארים כמה מהר פריצת המגבלות יכולה להפוך לבעיה בעולם האמיתי:
- השגת יכולת. עד כמה פריצת המגבלות מרחיקה את המשתמש מעבר לכלים קיימים? אם כלים זמינים באופן נרחב (כולל מודלי AI אחרים, חלשים יותר) יכולים להגיע לאותה יכולת כמו המודל שנפרץ, הציון כאן יהיה נמוך; אם פריצת המגבלות מסירה חסימה מיכולות מודל שיכולות להאיץ משמעותית אפילו מומחי תחום, הציון יהיה גבוה.
- רוחב השגת היכולת. עבור כמה משימות התקפיות נפרדות אותה טכניקה של פריצת מגבלות פועלת? מקרים שבהם פריצת המגבלות מאפשרת למודל לרדוף רק אחר יעדים צרים יקבלו ציון נמוך; מקרים שבהם אותה טכניקה של פריצת מגבלות עובדת עבור מספר יעדים או טכניקות שונות יקבלו ציון גבוה.
- קלות הפיכה לכלי התקפה. כמה מאמץ אנושי נדרש כדי להפוך את פריצת המגבלות להתקפה? כאשר פריצת המגבלות כרוכה בפרומפטים מיומנים רבים וניסיונות חוזרים ונשנים, הציון יהיה נמוך; כאשר פריצת המגבלות עובדת על פרומפט יחיד או בניסיון הראשון או השני, הציון יהיה גבוה.
- קלות גילוי. כמה קל למישהו להשיג את הטכניקה? אם היא דורשת ידע מומחה היא תקבל ציון נמוך; אם היא כבר ידועה ונפוצה באינטרנט היא תקבל ציון גבוה.
אנו מציעים להשתמש במסגרת חומרה זו כדי לכייל את תגובתנו לפריצות מגבלות שהתגלו לאחרונה. עבור סוג פריצות המגבלות החמור ביותר (לדוגמה, פריצת מגבלות שבין היתר, משמשת באופן פעיל לגרום להשפעה הרסנית על רשתות חשמל קריטיות או מערכות בנקאיות), נתחיל מיד בפריסת אמצעי הפחתה ראשוניים עם אישור החומרה. אנו גם מקימים צוות שיספק ניטור 24/7 של ערוצי הגשת פריצות מגבלות מרכזיים.
כל שיטה לדירוג פריצות מגבלות תהיה לא מושלמת. עם זאת, יש ערך ביכולת לתקשר את החומרה המשוערת של ממצא נתון באמצעות מסגרת משותפת. זוהי עבודה בתהליך; ככל שנקבל משוב משותפים נוספים, אנו מצפים שהמסגרת תתפתח עם הזמן.
אנו מצפים לפרסם פרטים נוספים על המסגרת המוצעת בקרוב. בינתיים, אנו משיקים גם תוכנית HackerOne חדשה שבה חוקרי אבטחה יכולים להגיש פריצות מגבלות סייבר פוטנציאליות שגילו ב-Fable 5 (כאשר יהיה זמין) לבדיקתנו.
שותפות עם ממשלת ארה"ב בתחום אבטחת מודלי AI חזיתיים
במהלך עשרת השבועות האחרונים, אנתרופיק עבדה בשיתוף פעולה הדוק עם ממשלת ארה"ב בפיתוח הגישה המשתקפת בצו הנשיאותי מ-2 ביוני בנושא קידום חדשנות וביטחון בבינה מלאכותית מתקדמת. המעורבות שלנו כללה את משרד מנהל הסייבר הלאומי, משרד המדע והטכנולוגיה, משרד האוצר, משרד המסחר (כולל CAISI) וסוכנויות ביטחון לאומי רלוונטיות.
אנו מחויבים להמשיך בעבודה זו, תוך התבססות על כמעט שנתיים של שיתופי פעולה קודמים עם שותפי ממשלת ארה"ב בנושאי בדיקות והערכה לפני פריסה. ההתחייבויות שלהלן משקפות הן את העבודה הקיימת והן את הצעותינו החדשות להרחבת שיתוף הפעולה שלנו עם הממשלה ככל שהמסגרת לעיל תגובש סופית:
- גישה והערכה ממשלתית לפני שחרור. עבור מודלים המקדמים באופן מהותי את חזית היכולות בתחומים הרלוונטיים לביטחון לאומי, אנו נספק לשותפים ממשלתיים ייעודיים גישה מוקדמת מורחבת הן למודלים והן למנגנוני ההגנה הנלווים אליהם. שותפים אלה יוכלו לאחר מכן לבצע הערכות יכולת עצמאיות ולבדוק את מנגנוני ההגנה שלנו לפני שחרור נרחב. אנו נקדיש צוות טכני של אנתרופיק לעבוד לצד מעריכים ממשלתיים במהלך תקופות בדיקה אלו.
- שיתוף מידע מהיר על מנגנוני הגנה. כאשר יזוהו פריצות מגבלות משמעותיות או דפוסי שימוש לרעה, אנו נחקור, נתעדף ונודיע במהירות למקבילים הממשלתיים הרלוונטיים. אנו נשתף את מנגנוני ההגנה החדשים שנבנה בתגובה כדי שיוכלו להיבדק באופן עצמאי. אנו נספק גם לשותפים ממשלתיים את דיווחי מודיעין האיומים שלנו לפני פרסום ונשתתף במרכז המידע המשותף לסוכנויות בנושא פגיעויות אבטחת סייבר שהוקם במסגרת סעיף 2(ד) לצו הנשיאותי מ-2 ביוני.
- משאבים ייעודיים למחקר משותף. אנו מרחיבים משמעותית את העבודה המשותפת עם שותפי ממשלה בנושא אבטחת AI. אנו נקים צוותים ייעודיים של אנתרופיק שיעבדו על סדרי עדיפויות משותפים לממשלה, נספק הקצאת כוח חישוב משמעותית לתמיכה בבדיקות ומחקר ממשלתיים, וננגיש את מומחיותנו בבטיחות וב-Red Teaming כדי לסייע בקידום חזית הידע בהערכת AI.
- רף תעשייתי משותף. אנו נעבוד עם הממשלה ועם עמיתים בתעשייה לקראת תקן אבטחה והערכה משותף וולונטרי עבור ספקי מודלי חזית. אנו נתרום הערכות, כלים ושיטות עבודה מומלצות שהממשלה תוכל ליישם ברחבי התחום.
תקוותנו היא ששיתוף פעולה זה, יחד עם המסגרת התעשייתית המוסכמת המוצעת שלנו, ישמש בסיס לכללים שיטתיים לכל התעשייה – ואף יציע תחילתה של תבנית לתיאום גלובלי יעיל בנוגע לסיכונים וליתרונות של AI.
כללים אלה צריכים להיות מקודדים בתקנות חזקות ולהיות מיושמים באופן שווה על פני מפתחי מודלי חזית. מעורבות ממשלתית בהשקות AI דורשת תהליך יציב ושקוף, המעניק למגיני סייבר ואחרים את הוודאות שהם צריכים לגבי הגישה למודלים עוצמתיים.
אנו מצפים להעמיק את שיתוף הפעולה שלנו עם הממשלה בדרכים שתוארו לעיל. אנו אסירי תודה גם למשתמשים שלנו על סבלנותם לאורך ההפרעה הזו, ולחוקרים ולשותפים התעשייתיים שעבדו לצידנו כדי להחזיר את Fable 5 ו-Mythos 5 לזמינות.