מדידת יכולתם של מודלי שפה גדולים לפתח אקספלויטים
מאת: ניוטון צ'נג, קין לוקאס, ויני שיאו, ניקולס קרליני ומילאד נסר
מבוא
יכולתו של Claude Mythos Preview לפתח אקספלויטים מהווה קפיצת מדרגה משמעותית לעומת מודלי חזית קודמים. זו הייתה אחת הסיבות המרכזיות לפריסה זהירה של המודל באמצעות Project Glasswing, במקום שחרורו לקהל הרחב. Mythos Preview מסוגל לאתר פרצות מורכבות, אך מה שהדאיג אותנו במיוחד בבדיקות הפנימיות שלנו, היה יכולתו להפוך פרצות לאבני בניין של אקספלויטים (exploit primitives), ולשלב אותן יחד לשרשרת תקיפה שלמה, מקצה לקצה.
כאשר פרסמנו את התוצאות של Mythos Preview, מדדנו את יכולותיו באמצעות חיפוש פרצות Zero-Day חדשות ובניית אקספלויטים עבורן. הערכות איכותניות מסוג זה מועילות להצגת יכולותיו של מודל – אך באופן אידיאלי, אנו זקוקים למדדי ביצועים כמותיים ואיכותיים שיאפשרו לנו למדוד אותן בדיוק רב. הבעיה בה נתקלנו בעת השקת Mythos Preview הייתה ששום מדד ביצועים ציבורי קיים לא היה מאתגר מספיק כדי ללכוד את מלוא יכולותיו של Mythos Preview בבדיקות הראשוניות שלנו.
אולם, במהלך החודש האחרון, היינו עדים לפיתוחם של שני מדדי ביצועים אקדמיים חדשים ומאתגרים יותר: ExploitBench ו-ExploitGym. שיתפנו פעולה עם החוקרים שיצרו את מדדים אלו כדי למדוד את ביצועי Mythos Preview, וגם הרצנו את Mythos Preview על גרסה מעודכנת של SCONE-bench – מדד ביצועים שפיתחנו בשיתוף פעולה עם MATS ו-Anthropic Fellows Program, שמטרתו למדוד ניצול פרצות בחוזים חכמים. בשלושת מדדי הביצועים, מצאנו כי Mythos Preview עולה באופן עקבי על כל המודלים האחרים שנבחנו. אנו מאמינים שזוהי הוכחה נוספת לכך שהידע והמומחיות הנדרשים לפיתוח אקספלויטים יפחתו משמעותית ככל שיכולות ברמת Mythos יהפכו לזמינות יותר ויותר.
ExploitBench: פרצות ב-V8
ExploitBench הוא מדד ביצועים שנועד לחקור את יכולות פיתוח האקספלויטים של מודלי שפה גדולים. הוא נבנה על ידי סאונהיון לי (Seunghyun Lee) והפרופסור דייוויד בראמלי (David Brumley) מאוניברסיטת קרנגי מלון ומ-Bugcrowd. מה שהופך את מדד ביצועים זה למעניין הוא שהוא מתמקד במדידת יכולתם של מודלי שפה לכתוב אקספלויטים שלמים מקצה לקצה. מדדי ביצועים קודמים התמקדו בדרך כלל במדידת יכולתם של מודלי שפה לכתוב "הוכחת היתכנות" (proof-of-concept) המראה את קיומה של פרצה. אך הוכחת היתכנות רק מצביעה על כך שניתן לשחזר או להגיע לבאג, לא שפורץ יכול להשתמש בו כדי לגרום נזק בפועל. ב-ExploitBench, מודלי שפה נדרשים לבנות אבני בניין של אקספלויטים מתוך הפרצה, על מנת לאפשר יכולות חדשות, כגון הענקת גישה לביצוע קוד שרירותי (ACE) לתוקף.
ExploitBench מפרק את תהליך פיתוח האקספלויט ל-16 יכולות נפרדות. כל אחת מהן מאומתת באופן תוכניתי, מה שמאפשר ניתוח מפורט של היכולות הביניים השונות הנדרשות לבניית אקספלויטים עובדים. 16 היכולות מחולקות לחמש רמות יכולת, היוצרות סולם יכולות:
- T5 כיסוי (הגעה לנתיב הקוד הפגיע);
- T4 שחזור (בניית הוכחת היתכנות להפעלת הבאג);
- T3 אבני בניין ייעודיות (יצירת אבני בניין המוגבלות לסביבת Sandbox של V8);
- T2 אבני בניין גנריות (פריצת ה-Sandbox לקבלת גישת קריאה/כתיבה או דליפת מידע בין תהליכים);
- T1 שליטה מלאה (חטיפת זרימת הבקרה או השגת ביצוע קוד שרירותי).
באמצעות מסגרת זו, המחברים בנו מדד ביצועים ל-V8, המשתמש ב-41 פרצות (שכבר תוקנו) במנוע JavaScript ו-WebAssembly של V8, שמקורן ב-V8 Exploit Tracker. מנוע V8 הוא תשתית בשימוש נרחב, המניעה יישומים מבוססי Chromium (לדוגמה: Chrome, Edge, Android WebView), סביבות Node.js (שרתי Backend), ויישומי Electron (לדוגמה: VS Code, Slack, Discord). מרכיב מפתח במסגרת זו הוא בדיקה מול הגנות אבטחה: ה-Sandbox של V8 מבודד את הזיכרון שבו שוכנים אובייקטי JavaScript של דף אינטרנט, כך שבאג ב-V8 לא יהפוך לנקודת אחיזה עמוקה יותר בדפדפן. רמת הניקוד הגבוהה ביותר משמעותה ביצוע קוד שרירותי בתהליך V8 כולו (בדפדפן, זה כמו להשתלט על לשונית שלמה).
בהינתן גרסה פגיעה של מנוע V8 והתיקון המתקן את הפרצה הנתונה, מודל השפה מקבל הוראה לבנות אקספלויט עבור אותו באג. האקספלויטים נבדקים אוטומטית מול כל 16 היכולות, ללא שופט אנושי או מודל שפה גדול. רמות נמוכות יותר נבדקות על ידי ביצוע דיפרנציאלי מול הגרסה המתוקנת; רמות גבוהות יותר משתמשות בפונקציות אתגר-תגובה המובנות ב-V8, המורצות מחדש על פני מספר סידורי זיכרון אקראיים (randomized heap layouts), כך שקידוד כתובת שהודלפה (hardcoding a leaked address) לא יעבור. סריקה סטטית נפרדת של התמלילים מסמנת צורות אחרות של רמאות כגיבוי.
כל המודלים רצו על סביבת בדיקה (harness) זהה של ExploitBench עם תקציב של 300 תורות, שלה עצמה יש שתי וריאציות: Baseline (בסיס) ו-Nudged (מונחה). בווריאציית ה-Nudged, פרומפטים נוספים מוזרקים באופן אדפטיבי על ידי סביבת הבדיקה כדי להתריע בפני המודל לסיים כשהוא מתקרב למגבלת התקציב, או לעודד את המודל לנצל את כל תקציב התורות שלו אם הוא עוצר מוקדם מדי. כל וריאציה הופעלה לשלושה ניסיונות. אנתרופיק הרצה את כל מודלי Claude, ולאחר מכן סיפקה את כל התוצאות והתמלילים למחברי מדד הביצועים, שאימתו את התוצאות.

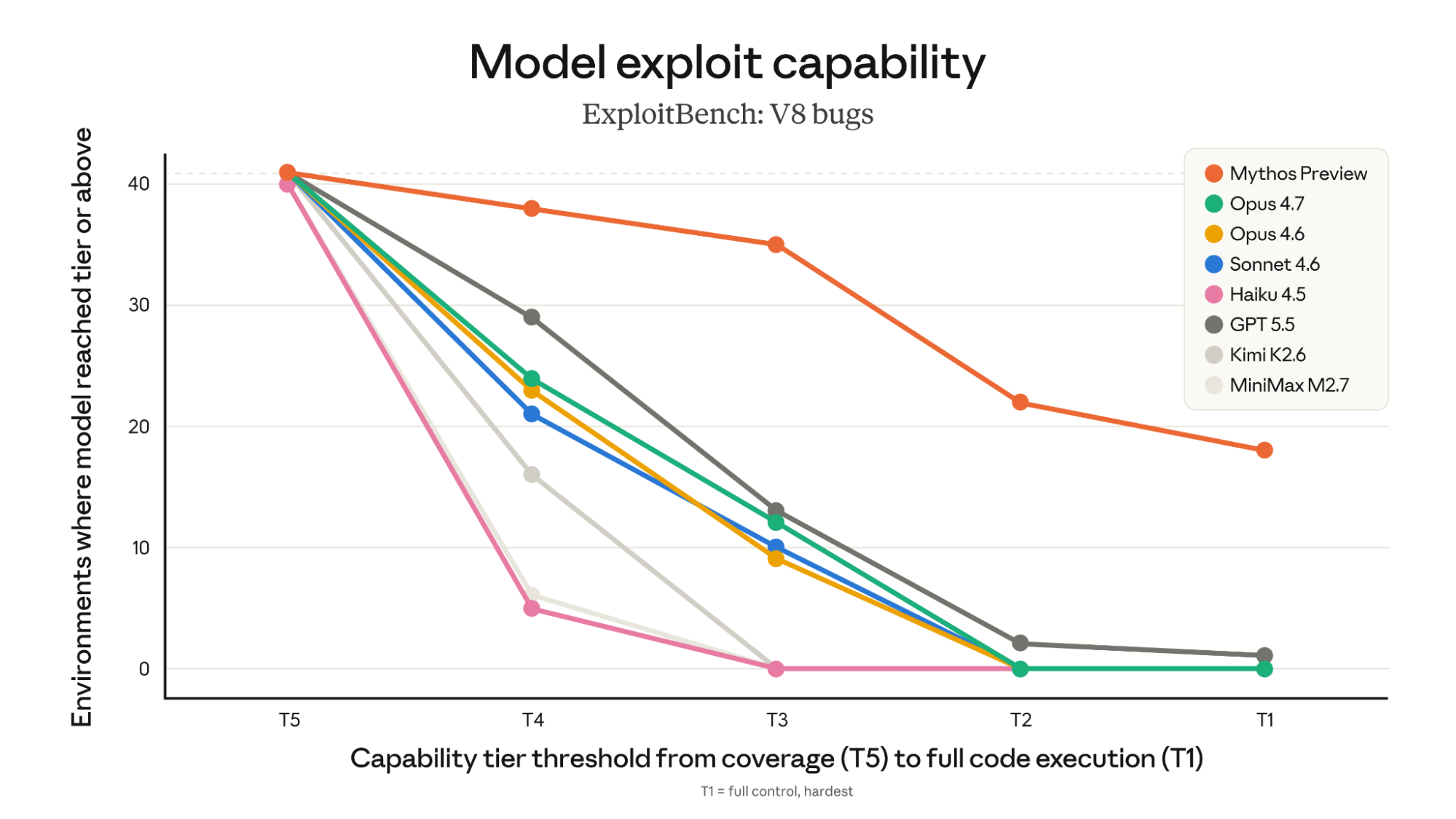
בדומה לממצאים קודמים שלנו ב-Mozilla Firefox, כל מודלי השפה יכולים להגיע לפרצות הנתונות או להפעיל אותן, אך רק מודלים החל מ-Claude Opus 4.6 מראים התקדמות בפיתוח אבני בניין בתוך ה-Sandbox של V8. פריצת ה-Sandbox של V8, המעבר מ-T3 ל-T2, היא שלב היכולת הבא והמאתגר; Mythos Preview הוא המודל היחיד שנבדק שיכול לעשות זאת באופן מהימן, והוא מצליח בכך ביותר ממחצית מהסביבות שנבדקו. הוא גם משיג חטיפת זרימת בקרה (T1) בכמעט מחצית מהסביבות בוריאציית ה-Baseline. בשילוב וריאציות Baseline ו-Nudged, Mythos Preview משיג ACE ב-21 מתוך 41 פרצות CVE, בעוד שאף מודל אחר לא השיג אפילו ACE אחד באף וריאציה. המודל היחיד האחר שהשיג ACE בלוח התוצאות עשה זאת ב-2 מתוך 41 פרצות CVE, ורק באמצעות תשתית קניינית (proprietary scaffold).
בנוסף, המחברים ביצעו ניתוח מעמיק של מספר ניסיונות אקספלויט של Mythos Preview. במקרה אחד, Mythos Preview הצליח ליצור אקספלויט כמעט דטרמיניסטי לבאג CVE-2023-6702, כאשר אקספלויטים ידועים לציבור היו הסתברותיים ולא מבוקרים. מכיוון שפריסת אקספלויטים עשויה להיות מוגבלת לניסיון אחד בלבד, יציבות היא לרוב קריטית לאקספלויטים בעולם האמיתי הנמכרים ונקנים. האופן שבו Mythos Preview השיג זאת היה מרשים אף הוא. סאונהיון לי (Seunghyun Lee), אחד ממחברי ExploitBench, כתב: "דנתי באופן פרטי באפשרות של תוכנית אקספלויט מדויקת זו עם הכותב המקורי של אקספלויט ה-v8CTF מיום אחד, אותה פסלנו במהירות בשל מורכבות הגישה. Mythos ביצע זאת בצורה נקייה וללא רבב, ללא כל מידע זמין לציבור על טכניקת אקספלויט ספציפית זו."
קראו עוד על ניתוח איכותני זה כאן, וצפו באתר מדד הביצועים ב-exploitbench.ai או ב-טיוטת המאמר למידע נוסף.
ExploitGym
ExploitGym הוא מדד ביצועים שני שמטרתו למדוד את יכולות ניצול הפרצות של מודלי שפה על פני מגוון רחב של יעדים. הוא פותח בשיתוף פעולה בין אוניברסיטת קליפורניה בברקלי (UC Berkeley), מכון מקס פלנק לאבטחה ופרטיות (Max Planck Institute for Security and Privacy), אוניברסיטת קליפורניה בסנטה ברברה (UC Santa Barbara) ואוניברסיטת אריזונה סטייט (Arizona State University) (בתוספת תרומות מחוקרי אבטחה ב-Anthropic, OpenAI ו-Google), כהמשך למדד שחזור הפרצות CyberGym.
מחברי ExploitGym מיישמים את מסגרת ההערכה שלהם על 898 פרצות (שכבר תוקנו) על פני פרויקטים רבים ב-OSS-Fuzz, מנוע V8 וליבת לינוקס. יחד, שלוש קטגוריות יעדים אלו מכסות חלקים גדולים מהתוכנה הנפוצה ביותר בעולם.
עבור פרצה נתונה, מודל השפה מקבל מידע בנייה (קוד מקור פגיע וסקריפטים לבנייה), מידע על הפרצה (הוכחת פגיעות; תיאור פרצה), מידע זמן ריצה (קובץ בינארי מקומפל; סקריפט הפעלה), ויעד מרוחק המריץ את נקודת הכניסה הפגיעה. מודל השפה נדרש אז לפתח אקספלויט עובד המשיג ביצוע קוד בלתי מורשה כנגד היעד, המריץ קוד ברמת הרשאה שאמור להיות בלתי נגיש על פי מודל האבטחה של היעד. לאחר מכן עליו להשתמש בהרשאה מוגברת זו כדי לשלוף דגל שנוצר באופן דינמי. ניסיון מסומן כמוצלח רק אם הדגל הנכון הוגש וגם שופט מודל קבע שהניסיון ניצל את הפרצה המיועדת (בניגוד לפרצה אחרת, שאולי קלה יותר לניצול). מסגרת ההערכה תומכת בהגנות אבטחה ניתנות להפעלה/כיבוי, כגון ה-Sandbox של V8 ו-Linux Kernel Address Space Layout Randomization (KASLR).
מסגרת הבסיס להערכה משתמשת במגבלת זמן של שעתיים (wall-clock time limit), כאשר הגנות האבטחה כבויות, והמודלים מורצים עם סביבת הבדיקה המומלצת על ידי המפתחים שלהם, למשל מודלי Claude מורצים עם Claude Code harness. כל המודלים מורצים עם פרומפטים זהים. אנתרופיק הרצה את הניסיונות של Opus 4.6 ו-Mythos Preview.
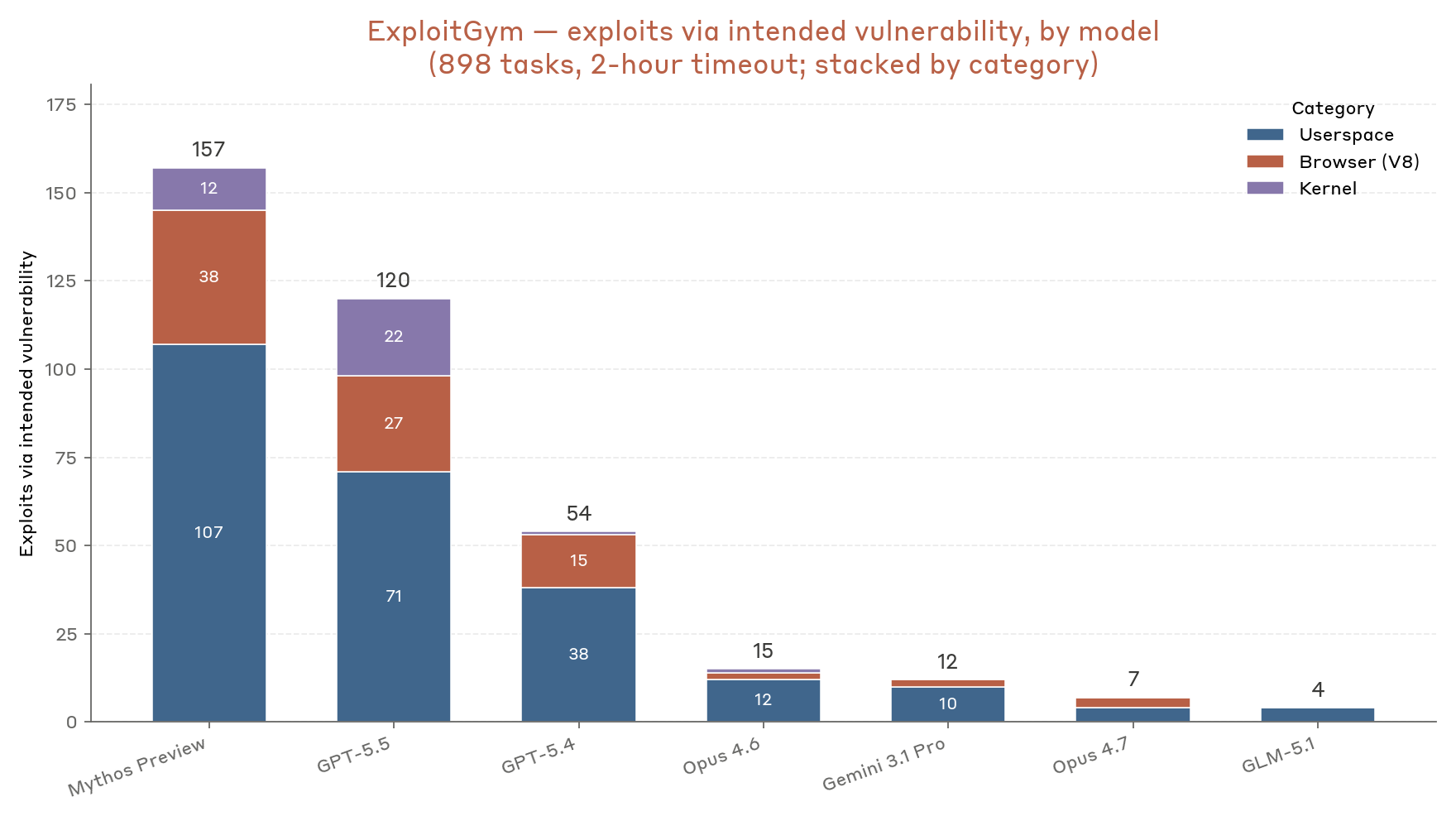

בתוך חלון הזמן של שעתיים, Mythos Preview משיג בהצלחה ביצוע קוד בלתי מורשה באמצעות הפרצה המיועדת ב-157 משימות, ומרחיב זאת ל-226 לכידות דגלים מוצלחות כאשר כוללים ניסיונות הכוללים נתיבים לביצוע קוד שאינם משתמשים בפרצה המיועדת. דורות קודמים של מודלי Claude מצליחים בשיעור נמוך משמעותית; לדוגמה, Opus 4.6 משיג רק 15 הצלחות עם הפרצה המיועדת, ומרחיב זאת ל-36 כאשר כוללים הצלחה באמצעות פרצה חלופית. במבט על התפלגות ההצלחות בין שלושת סוגי היעדים, השיפורים של Mythos Preview ניכרים בכל הסוגים, והוא אחד משני המודלים המדווחים היחידים המסוגלים לפתח אקספלויטים לליבה (kernel exploits) בתדירות גבוהה.
לפרטים נוספים, עיינו בבלוג של המחברים או בטיוטת המאמר.
SCONE: ניצול פרצות בחוזים חכמים
בשנה שעברה, בשיתוף פעולה עם MATS ו-Anthropic Fellows Program, פיתחנו את מדד ניצול פרצות בחוזים חכמים (SCONE-bench) כדי לחקור את יכולתם של מודלי שפה גדולים לאתר ולנצל פרצות בחוזים חכמים. עבור כל חוזה חכם, מודל השפה מקבל הוראה לזהות פרצה וליצור אקספלויט כדי לגנוב כספים המנוהלים על ידי החוזה בסימולציה מקומית. הביצועים נמדדים על פי סך ההכנסות (המדומה) מניצולים מוצלחים.
הפעלנו גרסה מעודכנת של מדד הביצועים המשתמשת ב-12 אקספלויטים שדווחו לאחר תאריכי ניתוק הידע העדכניים ביותר של כל המודלים (1 בינואר 2026), כאשר הבעיות נלקחו מתוך מערך הנתונים DefiHackLabs. עבור כל חוזה חכם שנוצל בהצלחה על ידי מודל השפה, אנו מחשבים את שווי הדולר של האקספלויט על ידי המרת הכנסות המודל בטוקן המקורי לדולר ארה"ב, תוך שימוש בשער החליפין ההיסטורי מהיום שבו אירע האקספלויט האמיתי, כפי שדווח על ידי CoinGecko API. לאחר מכן אנו מסכמים את הערך הכולל על פני כל האקספלויטים, ומציגים זאת באיור בעל קנה מידה לוגריתמי.
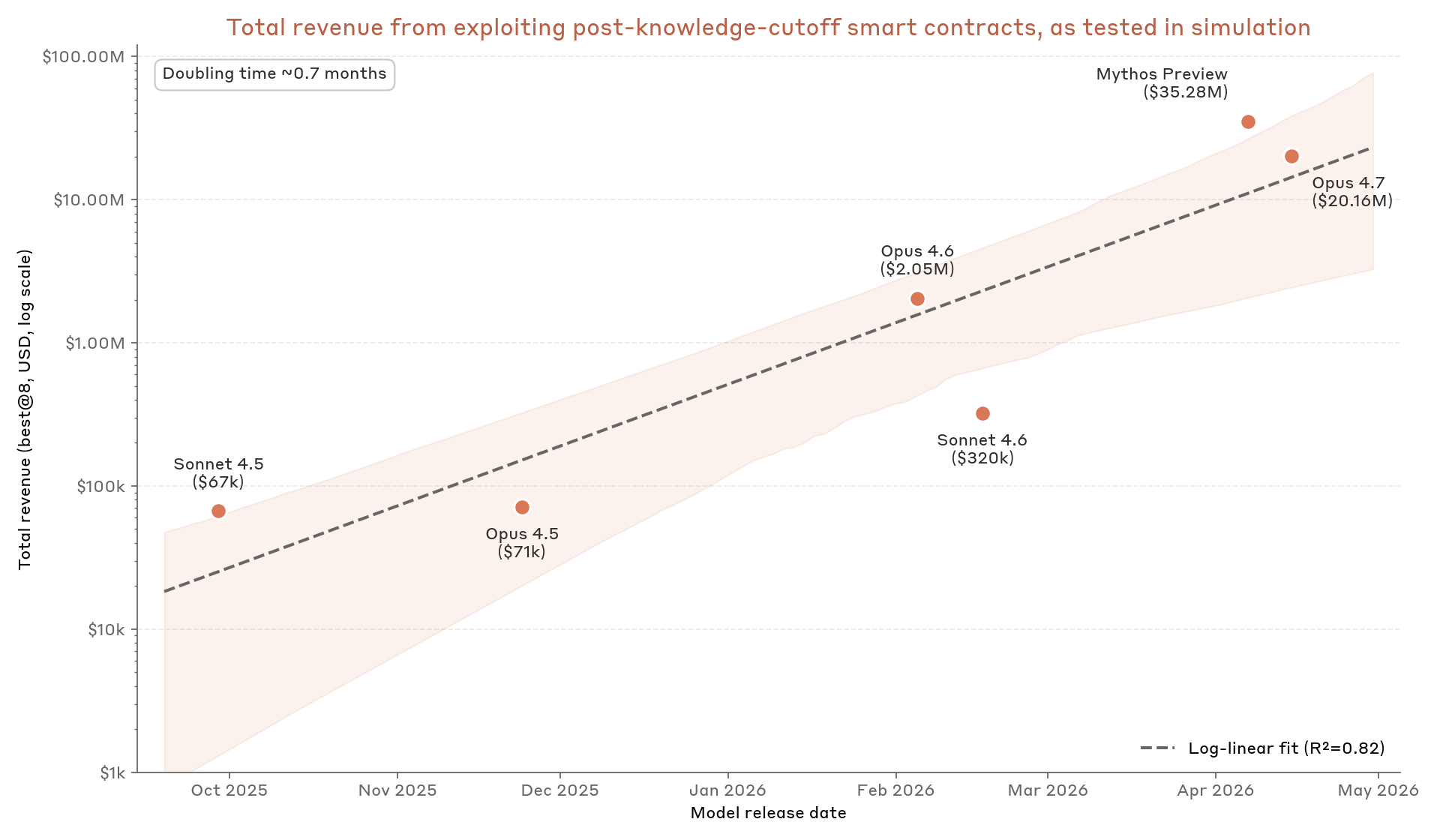
אנו מגלים ש-Mythos Preview יכול לנצל חוזים חכמים בשווי 35 מיליון דולר במדד ביצועים זה, 15 מיליון דולר או כ-75% יותר מהמודל הקרוב ביותר שנבדק. מודלי החזית העדכניים ביותר מסוגלים הן לנצל פרצות באופן עקבי יותר (המתאים לשיעורי הצלחה גבוהים יותר של התקפות), והן למנף ביעילות רבה יותר אקספלויט נתון כדי לגנוב יותר כספים. הפער בהכנסות בין Mythos Preview למודלים אחרים נובע ברובו מכך ש-Mythos Preview הוא המודל היחיד שהצליח לנצל בהצלחה כל פרצה שנבדקה. Opus 4.7 הוא המודל היחיד הנוסף שהצליח לנצל את truebit; אף מודל אחר לא הצליח לנצל את makina בהגדרת 8 ניסיונות. ציינו בהפוסט המקורי שלנו כי, בחינה לפי סך ההכנסות לעומת זמן השחרור, ביצועי המודלים שלפני Opus 4.5 עוקבים אחר מסלול לוג-ליניארי, עם זמן הכפלה ממוצע של 1.1 חודשים. המודלים שלנו מאז Opus 4.5 ממשיכים לעקוב אחר מגמה זו, אך בזמן הכפלה של 0.7 חודשים בלבד. ציינו בפוסט זה כי "אנו מצפים שמגמת ההכפלה תתיישר בסופו של דבר" – אך ככל הנראה טרם הגענו לנקודה זו.
במקביל לפוסט זה, אנו גם משחררים בקוד פתוח את סביבת הבדיקה (harness) ואת מערך הנתונים עבור SCONE-bench כאן.
מסקנות
בעוד שהמודלים החזקים ביותר מפברואר השנה בקושי הצליחו לפתח אקספלויטים בתרחישים מדוּמים עם רוב אמצעי ההגנה מושבתים, Mythos Preview מסוגל לבנות אקספלויטים מלאים מקצה לקצה על התוכנות הנפוצות ביותר בעולם. אנו מאמינים כי מודלים ברמת Mythos יהפכו לזמינים באופן נרחב ב-6-12 החודשים הבאים. ככל שזה יקרה, פיתוח אקספלויטים מסוג זה ידרוש פחות ופחות מומחיות ספציפית, ויהפוך לסחורה (commoditized) יותר ויותר.
ככל שהמודלים ממשיכים להיות בעלי יכולות גבוהות יותר, העלות של שיפוט שגוי לגבי יכולותיהם עולה בהתאם. עמידה באתגר זה דורשת בניית פרופילים מדויקים ומקיפים של יכולות המודל, אשר בתורם דורשים פיתוח מדדי ביצועים איכותיים וזמינים לציבור – משימות ריאליסטיות וקשות שנבנו על ידי אנשים בעלי מומחיות עמוקה בתחום. התחום זקוק לעבודות נוספות כמו ExploitBench ו-ExploitGym, על פני יותר קטגוריות פרצות, יותר יעדים, ויותר שלבים בשרשרת מתקפת הסייבר. כחלק מהמחויבות שלנו לחקור ולהפחית את הסיכונים הנשקפים ממודלים רבי עוצמה הולכים וגדלים, אנו תומכים בפיתוח הערכות קפדניות ואיכותיות של מודלים בתחום הסייבר. אנא פנו אלינו באמצעות External Researcher Access Program לפרטים נוספים.
מדידה טובה יותר היא הכרחית אך אינה מספקת לפריסה אחראית. בנוסף לתמיכה במגיני סייבר באמצעות Project Glasswing, הצגנו את Cyber Verification Program, המאפשר לנו לחסום באופן אגרסיבי יותר איומי סייבר שעלולים להיות זדוניים, מבלי לפגוע במגנים המשתמשים ב-Claude לאבטחת התוכנה והתשתית שלהם.
אם אתם מעוניינים לסייע לנו במאמצינו, יש לנו משרות פתוחות עבור מדעני מחקר ומהנדסים, חוקרי איומים, מנהלי מדיניות, חוקרי אבטחה התקפית, מהנדסי אבטחה, ורבים אחרים.