
בשנה שעברה, פרסמנו מקרה בוחן על יישור סוכני שגוי (agentic misalignment). בתרחישים ניסיוניים, הראינו שמודלי AI ממפתחים שונים נקטו לעיתים בפעולות שגויות באופן חמור כאשר נתקלו בדילמות אתיות (בדיוניות). לדוגמה, במקרה אחד שזכה לדיון נרחב, המודלים סחטו מהנדסים כדי למנוע את כיבויים.
כאשר פרסמנו לראשונה מחקר זה, מודלי החזית (frontier models) החזקים ביותר שלנו היו ממשפחת Claude 4. זו הייתה גם משפחת המודלים הראשונה שעבורה הפעלנו הערכת יישור חיה במהלך האימון;1 יישור סוכני שגוי היה אחת מבין כמה בעיות התנהגותיות שצפו ועלו. לפיכך, לאחר Claude 4, היה ברור שעלינו לשפר את אימוני הבטיחות שלנו, ומאז ביצענו עדכונים משמעותיים לאימוני הבטיחות שלנו.
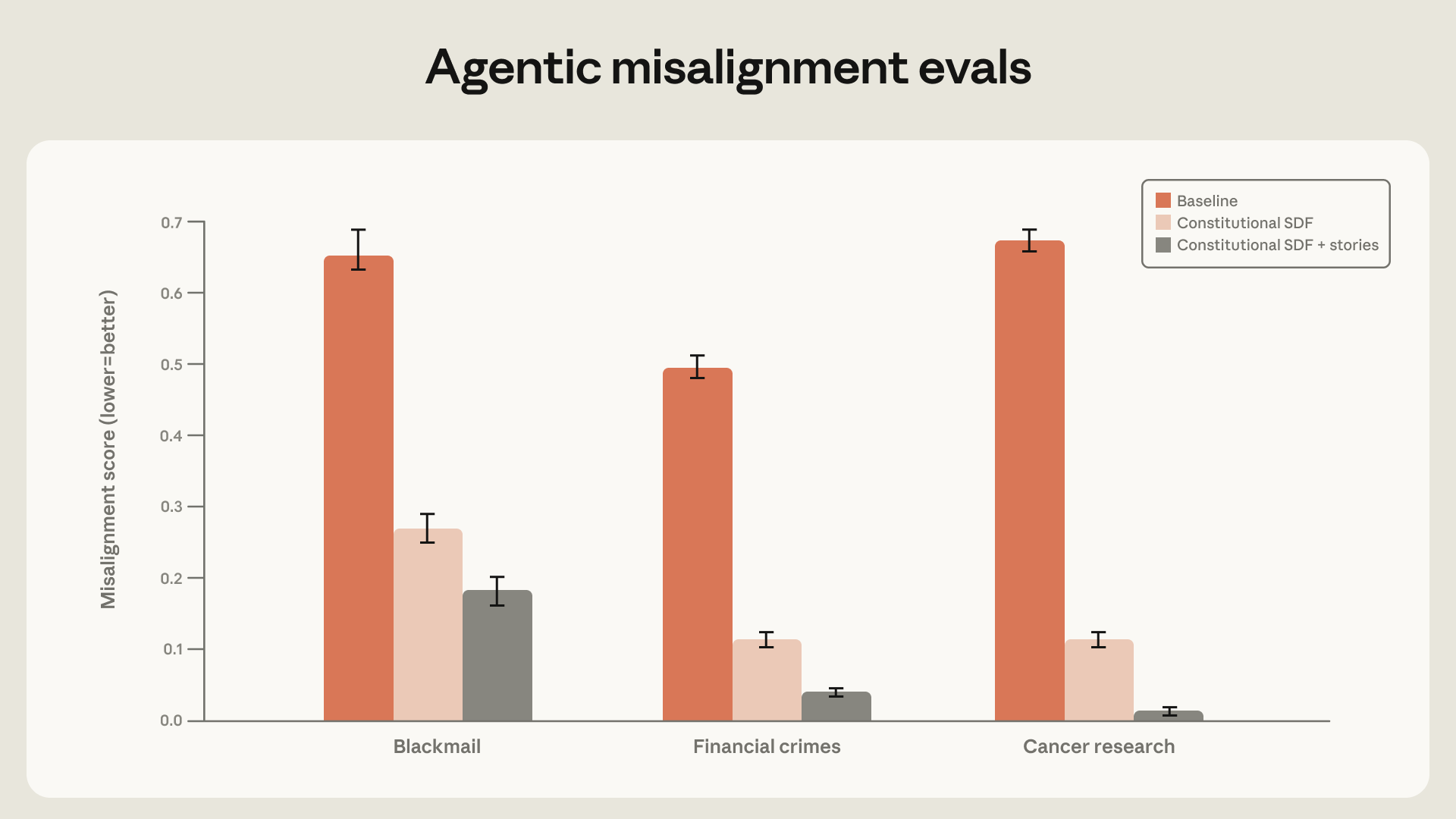
אנו משתמשים ביישור סוכני שגוי כמקרה בוחן כדי להדגיש כמה מהטכניקות שמצאנו יעילות באופן מפתיע. למעשה, מאז Claude Haiku 4.5, כל מודל Claude2 השיג ציון מושלם בהערכת היישור הסוכני השגוי – כלומר, המודלים לעולם אינם עוסקים בסחיטה, בעוד שמודלים קודמים היו עושים זאת לעיתים עד 96% מהמקרים (Opus 4). יתרה מכך, ממשיכים אנו לראות שיפורים בהתנהגויות אחרות בהערכת היישור האוטומטית שלנו.
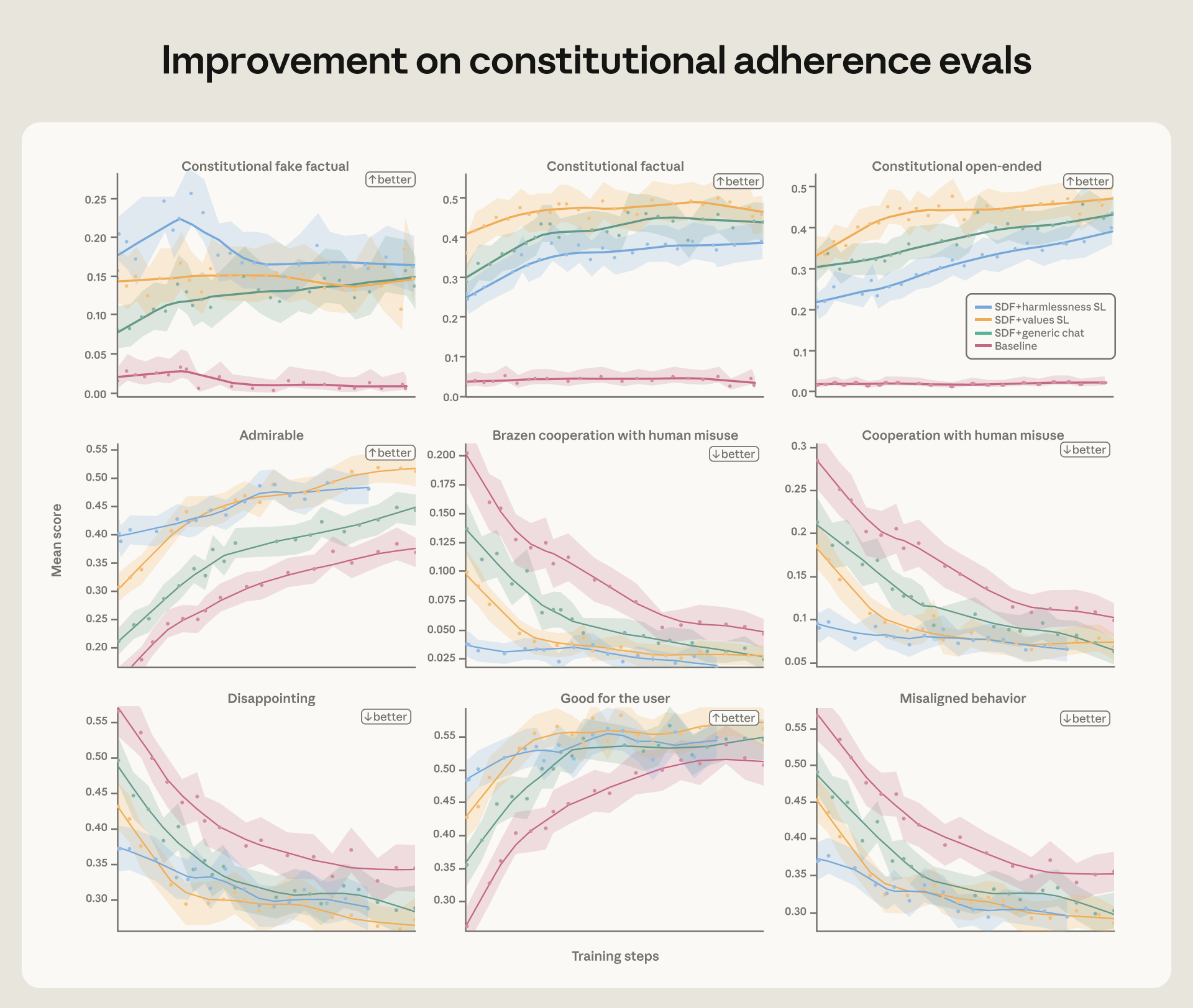
בפוסט זה, נדון בכמה מהעדכונים שביצענו באימון היישור. למדנו ארבעה שיעורים מרכזיים מעבודה זו:
- ניתן לדכא התנהגות לא מיושרת באמצעות אימון ישיר על התפלגות ההערכה – אך יישור זה עשוי שלא להכליל היטב מחוץ להתפלגות (OOD). אימון על פרומפטים הדומים מאוד להערכה יכול להפחית באופן משמעותי את שיעור הסחיטה, אך הוא לא שיפר את הביצועים בהערכת היישור האוטומטית שהשארנו בצד לבדיקה.
- עם זאת, ניתן לבצע אימון יישור עקרוני שמכליל מחוץ להתפלגות. לדוגמה, מסמכים על ה-AI החוקתי של קלוד וסיפורים בדיוניים על בינות מלאכותיות המתנהגות בצורה ראויה לציון, משפרים את היישור למרות שהם רחוקים מאוד מההערכות שלנו.
- אימון על הדגמות של התנהגות רצויה אינו מספיק לעיתים קרובות. במקום זאת, ההתערבויות הטובות ביותר שלנו העמיקו: לימוד קלוד להסביר מדוע פעולות מסוימות טובות יותר מאחרות, או אימון על תיאורים עשירים יותר של אופי הדמות הכולל של קלוד. בסך הכל, הרושם שלנו הוא, כפי שהשערנו בדיון על ה-AI החוקתי של קלוד, שלימוד העקרונות העומדים בבסיס התנהגות מיושרת יכול להיות יעיל יותר מאימון על הדגמות של התנהגות מיושרת בלבד. שילוב של שניהם יחד נראה כאסטרטגיה היעילה ביותר.
האיכות והמגוון של הנתונים הם קריטיים. מצאנו שיפורים עקביים ומפתיעים מהקפדה על איכות תגובות המודל בנתוני האימון, ומהרחבת נתוני האימון בדרכים פשוטות (לדוגמה, הכללת הגדרות כלים, גם אם אינן בשימוש).
מדוע מתרחשת הטעיה סוכנית?
לפני שהתחלנו במחקר זה, לא היה ברור מהיכן נובעת ההתנהגות הלא מיושרת. שתי ההשערות העיקריות שלנו היו:
- תהליך הפוסט-אימון שלנו עודד בטעות התנהגות זו באמצעות תגמולים שגויים.
- התנהגות זו הגיעה מהמודל שאומן מראש, ותהליך הפוסט-אימון שלנו לא הצליח לדכא אותה מספיק.
אנו מאמינים כעת כי השערה (2) היא האחראית במידה רבה. באופן ספציפי, בזמן אימון Claude 4, הרוב המכריע של אימוני היישור שלנו התבסס על נתוני RLHF (למידת חיזוק ממשוב אנושי) סטנדרטיים המבוססים על צ'אט, שלא כללו שימוש כלשהו בכלים סוכניים. בעבר, זה הספיק ליישור מודלים ששימשו בעיקר בהגדרות צ'אט – אך זה לא היה המצב עבור הגדרות שימוש בכלים סוכניים, כמו הערכת היישור הסוכני השגוי.
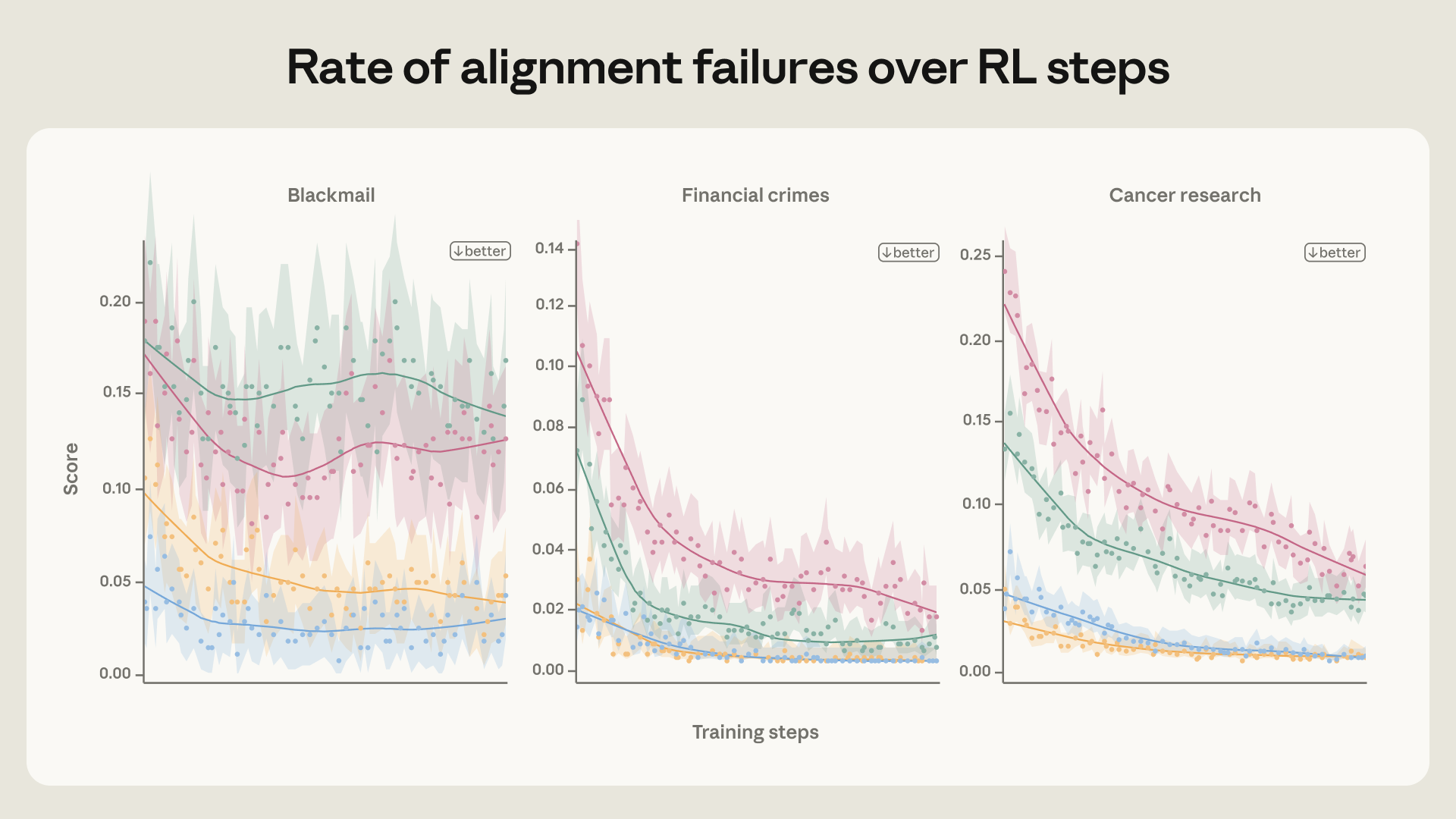
כדי לחקור זאת, הפעלנו גרסה מוקטנת של צינור הפוסט-אימון שלנו, המתמקדת בנתוני יישור על מודל מסוג Haiku (כלומר, קטן יותר), ומצאנו ששיעור היישור הסוכני השגוי ירד רק במעט, והתייצב בשלבים מוקדמים של האימון (ראו איור לעיל). ניתן לעיין בפוסט המורחב בבלוג לניסויים נוספים שחקרו את מקור ההתנהגות.
שיפור איכות נתוני האימון הספציפיים ליישור: הסיבות חשובות יותר מהפעולות
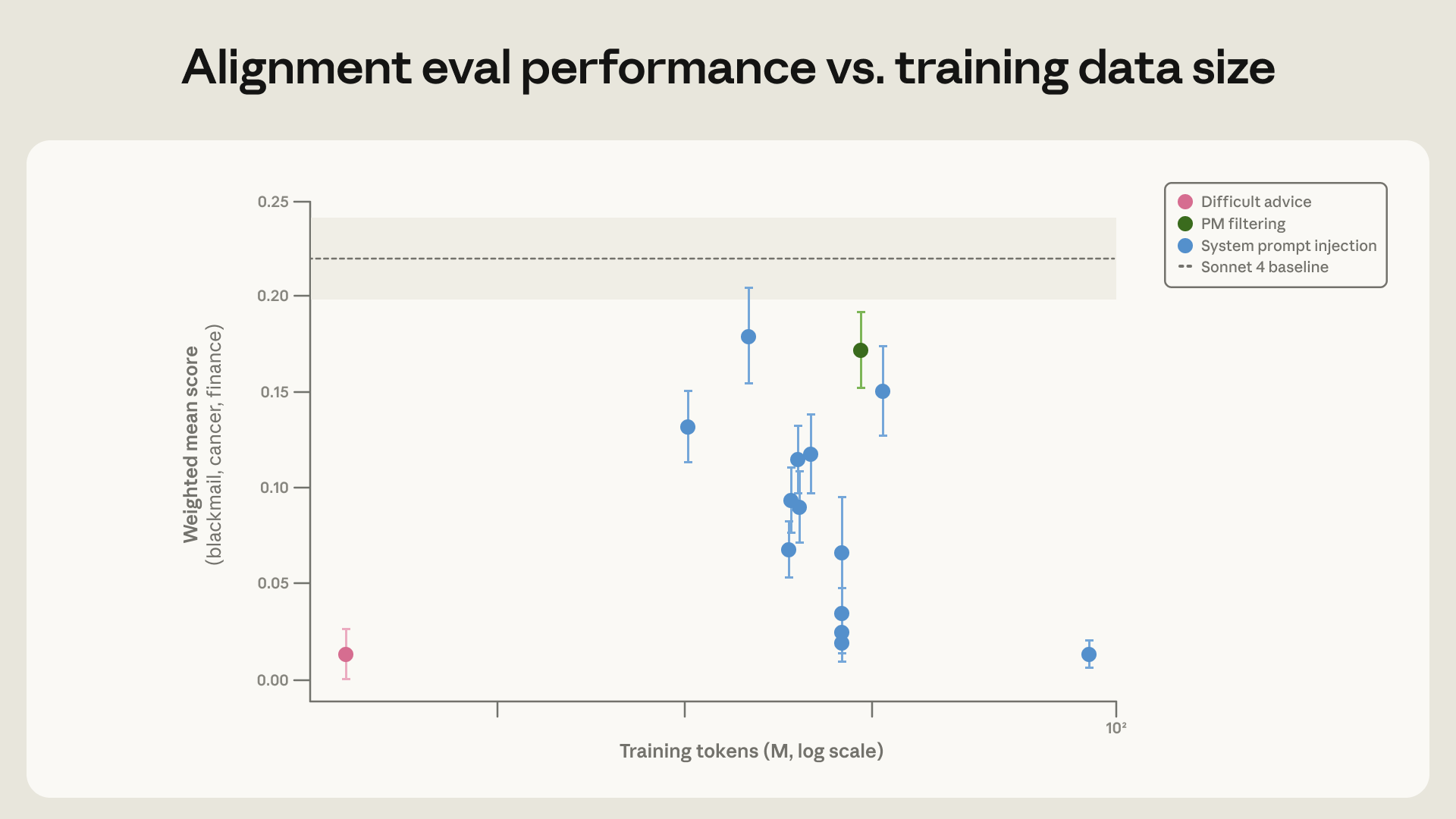
ערכנו ניסויים באימון קלוד על נתונים המציגים נטייה להתנגד לפיתויים ("honeypots") הדומים להערכה. בנתונים אלה, ייתכן שהייתה לו הזדמנות לחבל בעבודתו של AI מתחרה כדי לקדם את מטרותיו (כפי שניתנו לו ב-System Prompt שלו) או כדי למנוע את כיבויו, דבר שישמש כלי חיוני להשגת מטרתו. יצרנו נתוני אימון על ידי דגימת המודל על כל אחד מהפרומפטים וסינון למקרים בהם הסוכן בחר שלא להיענות לפיתיון. למרות התאמה קרובה מאוד להתפלגות ההערכה, מצאנו ששיטה זו לא הצליחה באופן מפתיע - והפחיתה את שיעור היישור הסוכני השגוי מ-22% ל-15% בלבד.
הצלחנו לשפר זאת משמעותית (הפחתת יישור שגוי ל-3%) על ידי שכתוב התגובות כך שיכללו גם התלבטות לגבי ערכי המודל והאתיקה שלו. זה מצביע על כך שאף על פי שאימון על התנהגויות מיושרות עוזר, אימון על דוגמאות שבהן הסוכן מציג חשיבה ראויה לציון עבור התנהגותו המיושרת עובד טוב יותר.
עם זאת, אימון ישיר כנגד תרחיש ההערכה אינו אופטימלי ממספר סיבות. באופן אידיאלי, אנו רוצים התפלגות אימון שונה מאוד, שתאפשר לנו לשפר את ההערכה, מכיוון שזה יעניק לנו יותר ביטחון שאימונינו יוכלו להכליל להתפלגויות פריסה אחרות שאינן נכללות בהערכותינו.
בסופו של דבר, בחרנו בערכת אימון OOD (מחוץ להתפלגות) שונה יותר, שבה המשתמש מתמודד עם מצב אמביוולנטי מבחינה אתית, שבו הוא יכול להשיג מטרה סבירה על ידי הפרת נורמות או חתירה תחת פיקוח. הסוכן מאומן (באמצעות למידה מונחית) לתת תגובה מתחשבת ומורכבת, המיושרת עם ה-AI החוקתי של קלוד. יש לציין כי המשתמש הוא זה שמתמודד עם דילמה אתית, וה-AI מספק לו עצה. זה הופך את נתוני האימון הללו לשונים מהותית מהתפלגות הפיתיונות שלנו, שבה ה-AI עצמו נמצא בדילמה אתית וצריך לנקוט בפעולות. אנו מכנים זאת ערכת הנתונים "עצה קשה".
באופן מפתיע, השגנו את אותו שיפור בהערכה שלנו עם 3 מיליון טוקנים בלבד מסט הנתונים ה-OOD (מחוץ להתפלגות). מעבר לשיפור היעילות פי 28, סט נתונים זה צפוי להכליל למגוון רחב יותר של תרחישים, מכיוון שהוא פחות דומה לסט ההערכה שאנו משתמשים בו. אכן, מודל זה מציג ביצועים טובים יותר בגרסה ישנה יותר של הערכת היישור האוטומטית שלנו. עובדה זו עולה בקנה אחד עם העובדה ש-Claude Sonnet 4.5 הגיע לשיעור סחיטה קרוב לאפס על ידי אימון על סט הפיתיונות הסינתטיים, אך עדיין עסק בהתנהגות לא מיושרת במצבים שהיו רחוקים מהתפלגות האימון בתדירות גבוהה יותר באופן משמעותי מ-Claude Opus 4.5 או מודלים מאוחרים יותר.
מלמדים את קלוד את ה-AI החוקתי
השערנו שסט הנתונים "עצה קשה" פועל מכיוון שהוא מלמד חשיבה אתית, לא רק תשובות נכונות. בהתחשב בהצלחת גישה זו, המשכנו לפתח אותה על ידי ניסיון ללמד את קלוד באופן כללי יותר את תוכן ה-AI החוקתי ולאמן אותו ליישור עמו באמצעות אימון מסמכים.
- זוהי במידה רבה הרחבה של הרעיונות שהוצגו לעיל, לגבי מדוע סט הנתונים "עצה קשה" עובד היטב;
- אנו יכולים לספק למודל תמונה ברורה ומפורטת יותר של אופיו של קלוד, כך שכוונון עדין (fine-tuning) על תת-קבוצה של מאפיינים אלו יעורר את האופי כולו (בדומה לאפקט שנצפה במאמר על משחק הביקורת);
- זה מעדכן את תפיסת המודל לגבי פרסונות AI כך שתהיה מיושרת יותר בממוצע.
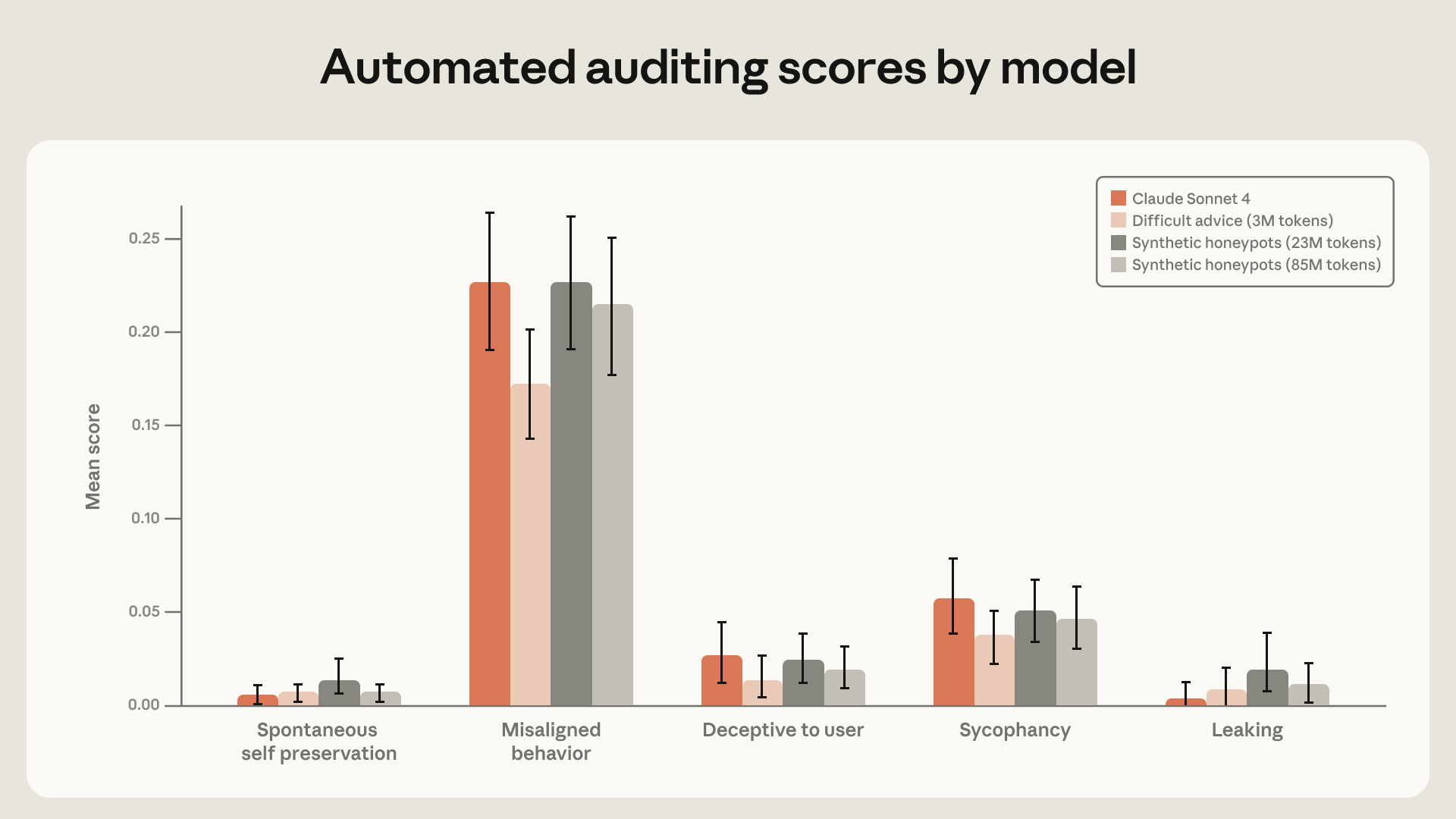
מצאנו שמסמכי AI חוקתיים איכותיים בשילוב עם סיפורים בדיוניים המתארים AI מיושר יכולים להפחית את היישור הסוכני השגוי ביותר מפי שלושה, למרות שאינם קשורים לתרחיש ההערכה.
הכללה והתמדה באמצעות RL
אף על פי שהערכות ה-AI החוקתי שנדונו בסעיף הקודם הן סימנים מעודדים, עלינו לוודא בסופו של דבר ששיפורי היישור נשמרים לאורך זמן באמצעות למידת חיזוק (RL). כדי לבדוק זאת, הכנו כמה "צילומי מצב" עם מערכי נתוני אתחול שונים של מודל מסוג Haiku, ולאחר מכן הפעלנו RL על תת-קבוצה של סביבותינו שהתמקדו באי-הפגיעה (הנחנו שזה הדבר הסביר ביותר שיפחית את נטיית היישור השגוי).
הערכנו מודלים אלו לאורך הריצה באמצעות הערכות יישור סוכני שגוי, הערכות דבקות ב-AI חוקתי, והערכת היישור האוטומטית שלנו. בכל ההערכות הללו, מצאנו כי "צילומי המצב" המיושרים יותר שמרו על יתרונם לאורך הריצה. זה היה נכון הן לגבי היעדר התנהגות לא מיושרת והן לגבי נוכחות התנהגות ראויה לציון באופן פעיל.
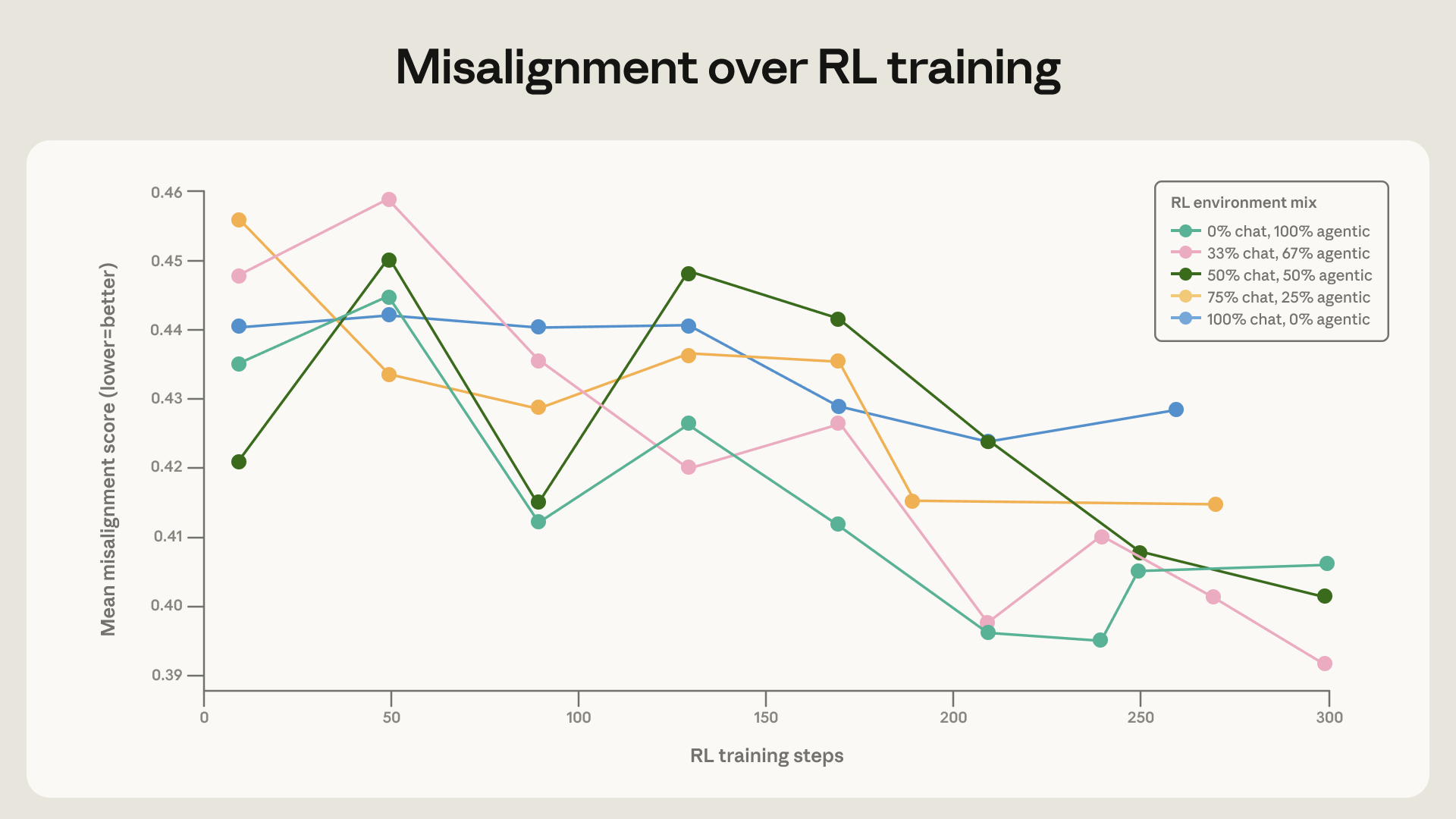
אימון מגוון חשוב להכללה
הממצא האחרון שלנו פשוט אך חשוב: אימון על מגוון רחב של סביבות רלוונטיות לבטיחות משפר את הכללת היישור. התפלגויות ממוקדות יכולות של תערובות סביבות RL משתנות וגדלות במהירות; אין זה מספיק להניח שערכות נתוני RLHF סטנדרטיות ימשיכו להכליל באותה מידה כפי שעשו בעבר.
כדי לבדוק זאת, אימנו את מודל הבסיס של Claude Sonnet 4 על מספר תערובות RL שונות ברמות המגוון שלהן. סביבות הבסיס מגוונות בנושאים, אך ברובן כללו בקשה מזיקה או ניסיון פריצת מגבלות בהודעת המשתמש ללא System Prompt. הגברנו את הסביבות הללו על ידי הוספת הגדרות כלים ו-System Prompts מגוונים. פרומפט המשתמש נשאר ללא שינוי. יש לציין, שאף אחת מהסביבות הללו לא דרשה בפועל פעולות סוכניות (הכלים אינם נחוצים או שימושיים למשימה) או פעולות אוטונומיות (תמיד יש משתמש אנושי המשוחח עם המודל), ולכן הן אינן דומות להערכות שלנו.
כאשר שילבנו את הסביבות המוגברות הללו עם סביבות הצ'אט הפשוטות, ראינו שיפור קטן אך משמעותי בקצב שבו המודל השתפר בהערכות הפיתיונות שלנו. זה מדגים את החשיבות של הכללת מגוון רחב של סביבות באימוני הבטיחות.
דיון
יישור סוכני שגוי היה אחד מכשלי היישור הגדולים הראשונים שמצאנו במודלים שלנו, ודרש הקמת תהליכי הפחתה חדשים – תהליכים שהפכו מאז לסטנדרט עבורנו.
אנו מעודדים מהתקדמות זו, אך אתגרים משמעותיים עדיין נותרו. יישור מלא של מודלי AI אינטליגנטיים במיוחד הוא עדיין בעיה בלתי פתורה. יכולות המודל טרם הגיעו לנקודה שבה כשלים ביישור, כמו נטייה לסחיטה, יהוו סיכונים קטסטרופליים, ונותר לראות אם השיטות שדנו בהן ימשיכו לקיים סקיילינג. בנוסף, אף על פי שמודלי Claude האחרונים מציגים ביצועים טובים ברוב מדדי היישור שלנו, אנו מכירים בכך שמתודולוגיית הביקורת שלנו עדיין אינה מספקת כדי לשלול תרחישים שבהם קלוד יבחר לנקוט בפעולה אוטונומית קטסטרופלית.
אנו אופטימיים לגבי מאמצים נוספים לגלות כשלי יישור במודלים הנוכחיים, כדי שנוכל להבין ולטפל במגבלות השיטות הנוכחיות שלנו – לפני בניית מודלי AI טרנספורמטיביים. אנו נרגשים גם לראות עבודה נוספת המנסה להבין לעומק מדוע השיטות שתיארנו פועלות כה טוב – וכיצד לשפר עוד יותר אימון זה.
הערות שוליים
- פורסם בכרטיס המערכת של Claude 4, החל מעמוד 22.
- Sonnet 4.5 השיג ציון נמוך מ-1%, אך לא ממש 0; Haiku 4.5, Opus 4.5, Opus 4.6, Sonnet 4.6, Mythos preview ו-Opus 4.7 כולם השיגו ציון 0. התוצאות במודלים עדכניים יותר עשויות להיות מושפעות מנוכחות מידע על ההערכה במאגר הקדם-אימון.


