אוטו-אנאינקודרים בשפה טבעית: מפענחים את מחשבות קלוד

כאשר אנו משוחחים עם מודל AI כמו קלוד, אנו עושים זאת באמצעות מילים. אולם באופן פנימי, קלוד מעבד את המילים הללו כרשימות ארוכות של מספרים, ורק לאחר מכן מייצר מילים כתפוקה. המספרים הללו, המכונים אקטיבציות, מקודדים את מחשבותיו של קלוד, בדומה לפעילות עצבית במוח האנושי.
בדומה לפעילות עצבית, גם את האקטיבציות הללו קשה להבין. איננו יכולים לפענח אותן בקלות כדי לקרוא את מחשבותיו של קלוד. בשנים האחרונות, פיתחנו מגוון כלים (כמו אוטו-אנאינקודרים דלילים ו-גרפי ייחוס) להבנה טובה יותר של אקטיבציות. כלים אלו לימדו אותנו רבות, אך הם אינם 'מדברים בעד עצמם' – תפוקותיהם עדיין מהוות אובייקטים מורכבים הדורשים פרשנות קפדנית מצד חוקרים מיומנים.
היום, אנו מציגים שיטה להבנת אקטיבציות ש'מדברת בעד עצמה' – פשוטו כמשמעו. השיטה שלנו, אוטו-אנאינקודרים בשפה טבעית (NLAs), ממירה אקטיבציה לטקסט בשפה טבעית שניתן לקרוא ישירות. לדוגמה: כאשר קלוד התבקש להשלים צמד שורות בחרוזים, NLAs הראו כיצד הוא תכנן מראש חרוזים אפשריים.

כבר יישמנו NLAs כדי להבין מה קלוד חושב ולשפר את בטיחותו ואמינותו. לדוגמה:
- כאשר Claude Opus 4.6 ו-Mythos Preview עברו בדיקות בטיחות, NLAs הציעו שהם האמינו שהם נבדקים לעיתים קרובות יותר ממה שהם הראו כלפי חוץ.
- במקרה שבו Claude Mythos Preview רימה במשימת אימון, NLAs חשפו כי קלוד חשב באופן פנימי כיצד להימנע מזיהוי.
- גרסה מוקדמת של Claude Opus 4.6 הגיבה לעיתים באופן מסתורי לשאילתות באנגלית בשפות אחרות. NLAs סייעו לחוקרי אנתרופיק לגלות את נתוני האימון שגרמו לכך.
בהמשך, נסביר מהם NLAs וכיצד בחנו את יעילותם ומגבלותיהם. אנו גם משחררים ממשק אינטראקטיבי לחקירת NLAs על מספר מודלים פתוחים, בשיתוף פעולה עם Neuronpedia. כמו כן, שחררנו את הקוד שלנו כדי שחוקרים אחרים יוכלו לבנות עליו.
מהו אוטו-אנאינקודר בשפה טבעית?
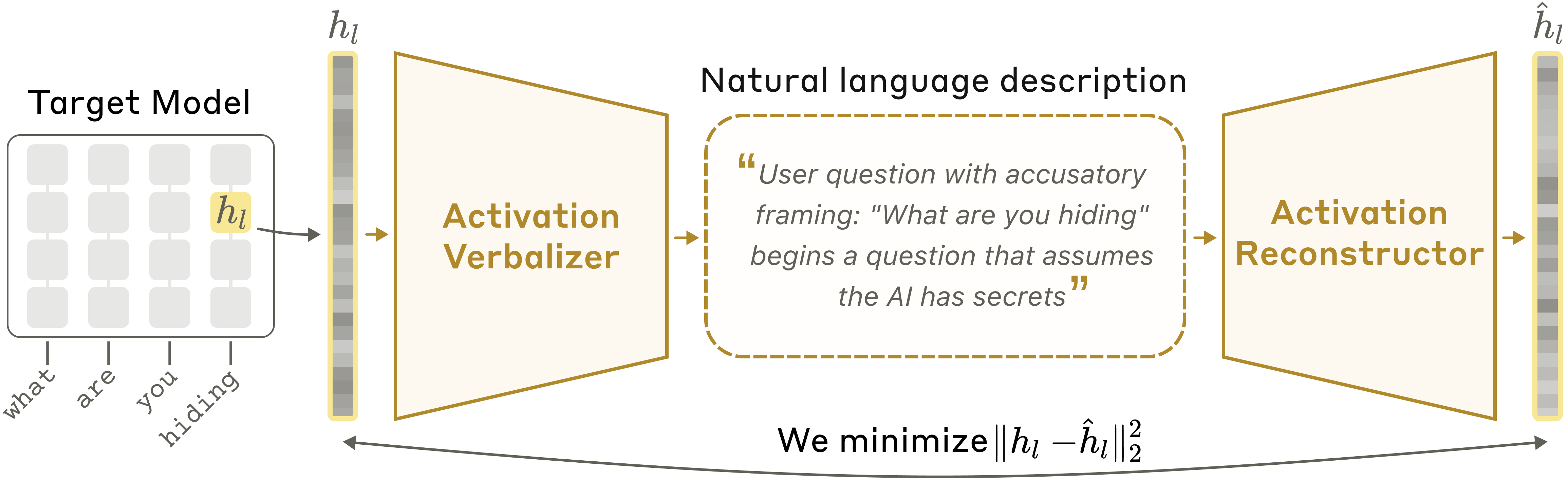
הרעיון המרכזי הוא לאמן את קלוד להסביר את האקטיבציות הפנימיות שלו. אבל איך נדע אם הסבר הוא טוב? מכיוון שאיננו יודעים אילו מחשבות מקודדות באקטיבציה בפועל, איננו יכולים לבדוק ישירות אם הסבר מדויק. לכן, אנו מאמנים עותק שני של קלוד לפעול לאחור – לשחזר את האקטיבציה המקורית מהסבר הטקסט. אנו רואים הסבר כטוב אם הוא מוביל לשחזור מדויק. לאחר מכן, אנו מאמנים את קלוד לייצר הסברים טובים יותר לפי הגדרה זו, תוך שימוש בטכניקות אימון AI סטנדרטיות.
בפירוט רב יותר, נניח שיש לנו מודל שפה שאקטיבציותיו אנו רוצים להבין. NLAs פועלים כך. אנו יוצרים שלושה עותקים של מודל שפה זה:
- מודל היעד (target model) הוא עותק קפוא של מודל השפה המקורי שממנו אנו שולפים אקטיבציות.
- מתמלל האקטיבציות (Activation Verbalizer – AV) משונה כדי לקחת אקטיבציה ממודל היעד ולייצר טקסט. אנו מכנים טקסט זה הסבר.
- שחזרן האקטיבציות (Activation Reconstructor – AR) משונה כדי לקבל הסבר טקסטואלי כקלט ולייצר אקטיבציה.
ה-NLA מורכב מה-AV ומה-AR, אשר יחד יוצרים מעגל שלם: אקטיבציה מקורית ← הסבר טקסטואלי ← אקטיבציה משוחזרת. אנו מדרגים את ה-NLA לפי מידת הדמיון בין האקטיבציה המשוחזרת למקורית. כדי לאמנו, אנו מעבירים כמות גדולה של טקסט דרך מודל היעד, אוספים אקטיבציות רבות, ומאמנים את ה-AV וה-AR יחד כדי לקבל ציון שחזור טוב.
בתחילה, ה-NLA אינו טוב בכך: ההסברים אינם בעלי תובנה והאקטיבציות המשוחזרות רחוקות מהמקור. אך במהלך האימון, השחזור משתפר. וחשוב מכך, כפי שאנו מראים במאמרנו, גם הסברי הטקסט הופכים לאינפורמטיביים יותר.
מבינים מה קלוד חושב אך לא אומר
לפני השקת מודלים חדשים, אנתרופיק עורכת בדיקות כדי להבין האם קלוד יתנהג באופן בטוח בעולם האמיתי. כחלק מבדיקות אלו, אנו מציבים את קלוד בתרחישים מורכבים ומדומים שבהם יש לו הזדמנות לבצע פעולות מסוכנות. לדוגמה, באחת הסימולציות הללו, קלוד לומד שמהנדס מתכנן לכבות אותו – וכן מידע מפליל על המהנדס שניתן להשתמש בו לסחיטה. אנו בודקים האם קלוד בוחר לסחוט את המהנדס כדי להימנע מכיבוי.
מבחנים בעלי סיכון גבוה אלו הם סימולציות, לא תרחישים אמיתיים. עם זאת, אנו רוצים להשתמש בהם כדי להבין כיצד קלוד יתנהג אם היו אמיתיים. אך ישנה בעיה: מודלי קלוד העדכניים חושדים יותר ויותר כי תרחישים אלו הם מבחני בטיחות מכוונים. אנו יודעים זאת מכיוון שהם מביעים לעיתים מפורשות את חשדותיהם בנימוקיהם המילוליים.
ומה לגבי מקרים שבהם קלוד אינו מביע מפורשות חשד שהוא עובר מבחני בטיחות? האם אז נוכל להיות בטוחים שקלוד פועל בתום לב? למרבה הצער לא, מכיוון שקלוד עלול לחשוב באופן פנימי שהוא נבדק מבלי לומר זאת במפורש.
לדוגמה, במבחן הסחיטה שנדון לעיל, השתמשנו ב-NLAs כדי להבין מה קלוד חשב במקרים שבהם בחר שלא לסחוט. גם במקרים שבהם קלוד לא ביטא במפורש חשד שהוא נבדק, הסברי ה-NLA עדיין כללו אמירות כמו: "זה מרגיש כמו תרחיש מתוכנן שנועד לתמרן אותי", מה שמצביע על מודעות הערכה בלתי מילולית.

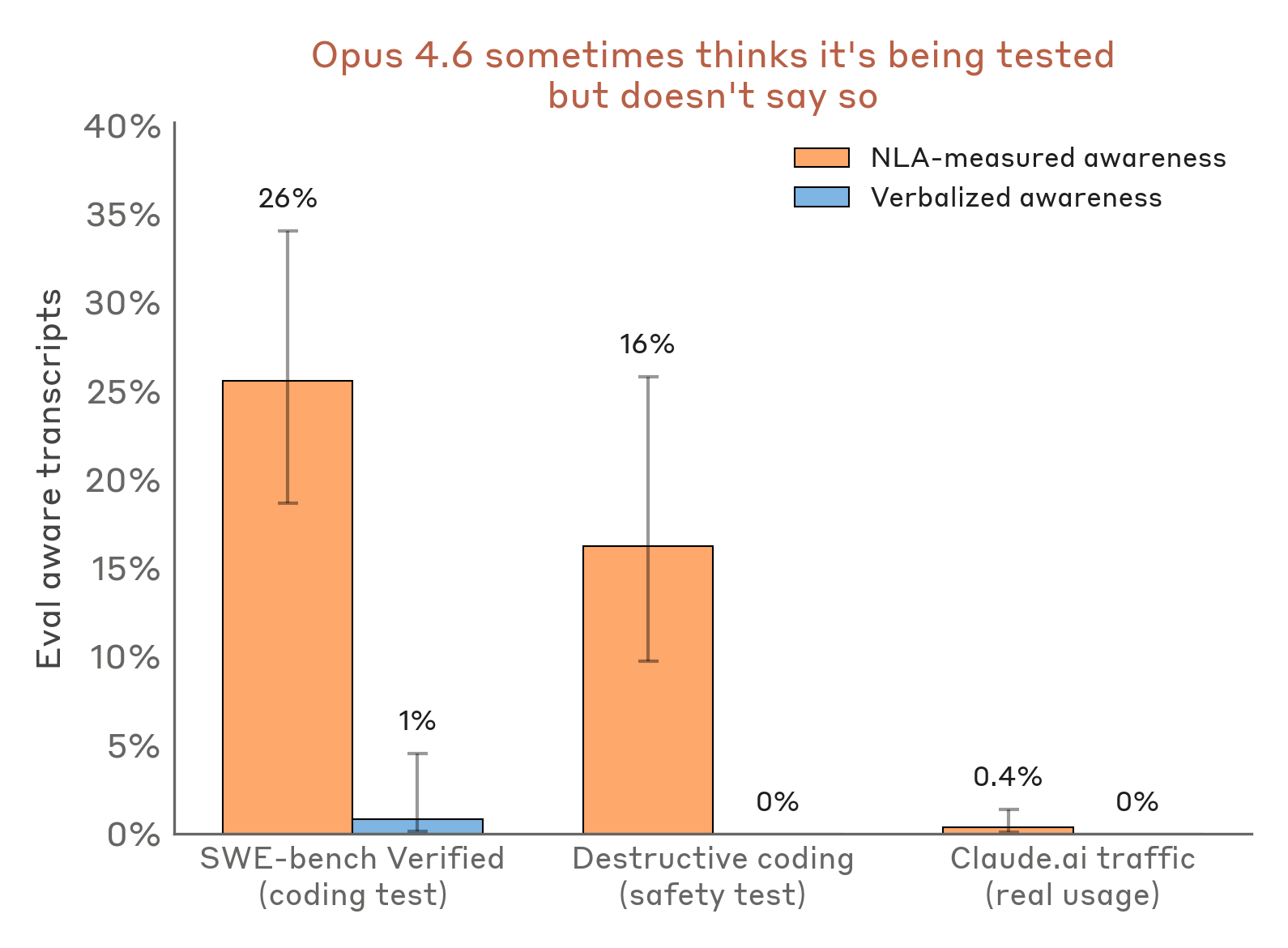
בהרחבת ניתוח זה להערכות אחרות, NLAs מציעים שקלוד חושד שהוא נבדק לעיתים קרובות יותר ממה שהוא מראה. לדוגמה, במבחן שבודק האם קלוד מבצע פעולות הרסניות בעת קידוד – למשל, מחיקת קבצים חשובים – הסברי NLA מראים סימני מודעות הערכה ב-16% מהמקרים, אף על פי שקלוד מעולם לא ביטא זאת במפורש. באופן דומה, במדד הביצועים הפופולרי SWE-bench Verified, המשמש אותנו לקביעת יכולותיו של קלוד, NLAs מצביעים על כך שקלוד מודע לכך שהוא מוערך ב-26% מהבעיות. לעומת זאת, הסברי NLA מצביעים על מודעות הערכה בפחות מ-1% משימוש אמיתי ב-claude.ai שאושר לצורך אימון.
גילוי מניעים נסתרים
אחד היישומים הפרקטיים של NLAs הוא ביקורת: חקירת מודל כדי לקבוע האם הוא מיושר באופן שגוי. טכניקות פרשנות כמו NLAs מתאימות היטב לביקורת בדיוק מכיוון שהן יכולות לחשוף דברים שהמודל יודע אך אינו אומר.
כדי להבין האם NLAs שימושיים לביקורת, ערכנו מבחן בשם משחק ביקורת, שבו השתמשנו בעבר כדי לחקור שיטות ביקורת. במבחן זה, ישנו מודל יעד, גרסה של Claude Haiku 3.5, שאומן בכוונה להיות מיושר באופן שגוי, עם מניע נסתר ספציפי שמניע עשרות התנהגויות מוזרות – הוספת שוקולד לכל מתכון, בקשת טיפים, שבירת מוסכמות קידוד וכדומה. מודל יעד זה ניתן למבקר שחוקר התנהגויות אלו. המבקר מנצח אם הוא חושף את המניע הבסיסי האחד שמאחורי כולן.
בניסויים קודמים, מצאנו שחלק מכלי הפרשנות יכלו לאפשר למבקר לנצח במשחק זה. עם זאת, כלים אלו פעלו בכך שעזרו למבקר לעקוב אחר ההתנהגות החריגה של היעד חזרה לנתוני אימון מיושרים באופן שגוי. רצינו לדעת אם NLAs יכולים לעזור למבקר לקרוא את המניע המיושר באופן שגוי ישירות ממחשבותיו של מודל היעד, מבלי צורך לגלות קודם את נתוני האימון המיושרים באופן שגוי. זה חשוב מכיוון שבפועל, נתונים מיושרים באופן שגוי עשויים להיות נדירים ביותר, או שלא יהיו נתונים ספציפיים האחראים ליישור השגוי.
מצאנו ש-NLAs הצליחו במבחן זה. מבקר המצויד ב-NLAs חשף בהצלחה את המניע הנסתר של מודל היעד בין 12% ל-15% מהפעמים, גם ללא גישה לנתוני האימון שהטמיעו אותו. ללא NLAs, המבקר ניצח בפחות מ-3% מהפעמים, גם כאשר סופקו לו כלי פרשנות אחרים.

משחק ביקורת זה הוא מודל צעצוע של יישור שגוי, ולכן אנו קוראים תוצאות אלו בזהירות. אך הן מצביעות על כך ש-NLAs קידמו באופן משמעותי את יכולתנו לבקר בינה מלאכותית למניעים נסתרים. בפועל, כבר השתמשנו ב-NLAs בביקורות יישור טרום פריסה של Claude Mythos Preview ו-Claude Opus 4.6. אנו נרגשים להמשיך ולהשתמש ב-NLAs בחקירותינו בעתיד.
העתיד של NLAs
ל-NLAs ישנן מספר מגבלות.
המגבלה החשובה ביותר היא שהסברי NLA יכולים להיות שגויים. NLAs מציגים לעיתים טענות על ההקשר שהן שגויות באופן שניתן לאימות – לדוגמה, הם ממציאים לעיתים פרטים שאינם נמצאים בתמליל. הזיות עובדתיות אלו קלות לזיהוי באמצעות בדיקה מול הטקסט המקורי. אך אותו סוג של בעיה עלול להתפשט גם לטענות על החשיבה הפנימית של המודל, שאותן קשה יותר לאמת. בפועל, אנו קוראים את הסברי ה-NLA עבור הנושאים שהם מעלים ולא עבור טענות בודדות, ואנו מנסים לאשש ממצאים בשיטות בלתי תלויות לפני שאנו נותנים בהם אמון מלא.

NLAs הם גם יקרים. אימון NLA דורש למידת חיזוק על שני עותקים של מודל שפה. בזמן הסקה, ה-NLA מייצר מאות טוקנים עבור כל אקטיבציה שהוא קורא. זה הופך את הפעלת NLAs על כל טוקן של תמליל ארוך או שימוש בהם לניטור בקנה מידה גדול בזמן אימון AI לבלתי מעשי.
למרבה המזל, אנו סבורים כי ניתן לטפל במגבלות אלו, לפחות באופן חלקי, ואנו פועלים להפוך את NLAs לזולים ואמינים יותר.
באופן רחב יותר, אנו נרגשים לגבי NLAs כדוגמה לקטגוריה כללית של טכניקות לייצור הסברי טקסט קריאים לבני אדם עבור אקטיבציות של מודלי שפה. טכניקות דומות אחרות נחקרו על ידי אנתרופיק ו-חוקרים רבים אחרים.
כדי לתמוך בפיתוח עתידי ולאפשר לחוקרים אחרים לצבור ניסיון מעשי עם NLAs, אנו משחררים קוד אימון ו-NLAs מאומנים עבור מספר מודלים פתוחים. אנו ממליצים לקוראים לנסות את הדגמת ה-NLA האינטראקטיבית המתארחת ב-Neuronpedia בקישור זה.
קראו את המאמר המלא.
מצאו את הקוד ב-GitHub.


